아스키코드란?
-
아스키코드란
ASCII(American Standard Code for Information Interchange)의 줄임말이다.
-
이름에서부터 알 수 있듯이
American을 위한 문자 집합이고
이는 영문 키보드로 입력할 수 있는
모든 기호가 할당되어 있는 부호 체계이다.
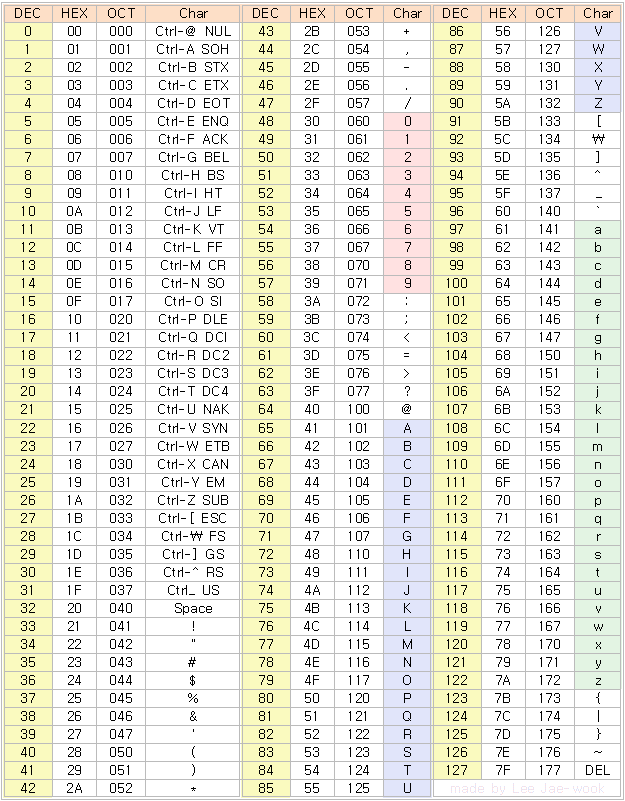
그래서 000(0x00)부터 127(0x7F)까지 총 128개의 부호가 사용된다.
Q. 왜 128개만 사용하는 걸까?
-
아스키코드는 1바이트를 사용한다.
그렇기 때문에 2^8 = 256개를 사용할 수 있지만
2^7 = 128개만 사용한다.
그 이유는 나머지 1bit를 통신 에러 검출을 위해 사용하기 때문이다.
## Parity Bit
7개의 비트 중
1의 개수가 홀수면 1
1의 개수가 짝수면 0으로 하는
Parity Bit를 붙여
전송 도중 변질된 것을 검출해낸다.
-
매우 단순하고 간단하므로
어느 시스템에서도 적용 가능하다는 장점이 있다.
하지만 2바이트 이상의 코드를 표현할 수 없기 때문에
국제표준의 위상은 유니코드에게 넘어갔다.
유니코드와 호환성
-
UTF-8의 경우
ASCII 영역은 그대로 1바이트를 사용하기 때문에 호환이 된다.
-
그러므로 UTF-8으로 인코딩된 문서에서
ASCII 영역에 해당하는 문자만 적혀 있고
Byte Order Mark(BOM)까지 없다면 그냥 ASCII 문서와 다를 게 없다.
-
하지만 UTF-16은
2바이트에서 시작하기 때문에 호환이 되지 않는다.
-
이 때문에 UTF-16에서
ASCII 문자를 나타낼 때는 앞에 0x00이 붙는다.
ex) A라는 글자를 표현하려면
ASCII 혹은 UTF-8에서는 0x41이라고만 표현하면 되지만
UTF-16에서는 0x0041로 표현해야 한다.
이를 무시하고 1바이트로만 표현하면
앞뒤의 바이트가 묶여 다른 문자로 인식된다.
