DB 확장
-
하나의 데이터베이스로 다룰 수 없을 만큼 많은 데이터를 저장하고 조회하려면
-
당연히 여러 데이터베이스를 이용하는 방식을 모색해야 할 것이다.
-
Cassandra나 Dynamo처럼 분산 환경을 고려하여 만들어진 데이터베이스도 있지만
-
범위 검색에 취약하거나 JOIN 연산을 사용할 수 없는 등 기능에 제약이 많다.
-
따라서 상대적으로 풍부한 기능을 사용하면서 데이터 확장을 꾀할 수 있는 방법은
-
RDBMS를 샤딩(sharding)하여 사용하는 것이 유리하다.
-
과거에는 애플리케이션 서버에서 샤딩 로직을 직접 구현하여 사용하였지만
-
최근에는 샤딩 플랫폼을 도입하는 사례가 늘고 있다.
-
계속 증가하는 데이터에 장애 없이 효과적으로 대응할 수 있어야 하고
-
서비스마다 다른 데이터 특성과 모델에 어떻게 대처할 것인가가 샤딩 플랫폼의 핵심이다.
샤딩과 수평 분할
-
샤딩은 수평 분할(horizontal partitioning)과 비슷하다.
-
수평 분할이란 스키마(schema)가 같은 데이터를 두 개 이상의 테이블에 나누어 저장하는 디자인을 말한다.
-
데이터베이스를 샤딩하게 되면 기존에 하나로 구성될 스키마를
-
다수의 복제본으로 구성하고 각각의 샤드에 어떤 데이터가 저장될지를 샤드키를 기준으로 분리한다.
-
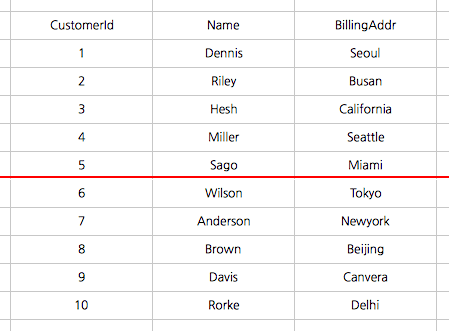
Ex 1)
-
나는 고객의 데이터베이스를 CustomerId를 샤드키로 사용하여 샤딩하기로 하였다.
-
0 ~ 10000 번 고객의 정보는 하나의 샤드 에 저장하고
-
10001 ~ 20000 번 고객의 정보는 다른 샤드 에 저장하기로 하였다.
-
Ex 2)
-
주민 데이터를 처리하기 위해 스키마가 같은 ‘서현동주민 테이블’과 ‘정자동주민 테이블’을 사용하는 것을 말한다.
-
인덱스의 크기를 줄이고 작업 동시성을 늘리기 위한 것이다.
-
보통 수평 분할을 한다고 했을 때는 하나의 데이터베이스 안에서 이루어지는 경우를 지칭한다.
-
샤딩은 물리적(=다른 데이터베이스)으로 데이터를 수평 분할 방식으로 분산 저장하고 조회하는 방법을 말한다.
-
‘주민’ 테이블이 여러 DB에 있을 때
-
서현동 주민에 대한 정보는 A DB에, 정자동 주민에 대한 정보는 B DB에 저장되도록 하는 방식을 말한다.
-
여러 데이터베이스를 대상으로 작업해야 하기 때문에 경우에 따라서는 기능에 제약이 있을 수 있고(JOIN 연산 등)
-
일관성(consistency)과 복제(replication) 등에서 불리한 점이 많다.
-
예전의 샤딩은 애플리케이션 서버 레벨에서 구현하는 경우가 많았다.
-
최근에는 이를 플랫폼 차원에서 제공하려는 시도가 많다.
수직 분할
-
수직 분할(vertical partitioning)은 하나의 엔티티에 저장된 데이터들을 다수의 엔티티들로 분리하는것을 말한다.
-
(마찬가지로 공간이나 퍼포먼스의 이유로) 예를 들면 한 고객은 하나의 청구 주소를 가지고 있을 수 있다.
-
그러나 나는 데이터의 유연성을 위해 다른 데이터베이스로 정보를 이동하거나 보안의 이슈등을 이유로
-
CustomerId를 참조하도록 하고 청구 주소 정보를 다른 테이블로 분리할 수 있다.
-
요약하면 파티셔닝은 퍼포먼스, 가용성, 정비용이성등의 목적을 위해
-
논리적인 엔티티들을 다른 물리적인 엔티티들로 나누는것을 의미하는 일반적인 용어이다.
-
샤딩 또는 수평 파티셔닝은 스키마 복제 후 샤드키를 기준으로 데이터를 나누는 것을 말한다.
-
수직 파티셔닝은 스키마를 나누고 데이터가 따라 옮겨가는 것을 말한다.
샤딩 적용시 문제점들 및 고려사항
-
데이터 재분배 ( Rebalancing data )
-
샤딩된 DB의 물리적인 용량한계나 성능한계에 도달하면
-
샤드의 수를 늘리는 scale-up 작업이 필요하다.
-
서비스 정지 없이 scale-up 할수 있도록 설계방향을 잡아야 한다.
-
-
샤딩으로부터 데이터 조인하기 ( Joining data from multiple shards )
-
샤딩 DB 간에 조인이 불가능 하기에 처음부터 역정규화를 어느정도 감수해야 한다.
-
샤드의 목적이 대용량 데이터 처리이므로 대용량처리시 수행성능을 위해서
-
데이터 중복은 trade-off 관계 임을 이미 알고 있다.
-
-
샤드에 데이터를 파티션하는 방법 ( How do you partition your data in shrads? )
- 샤드 해쉬함수를 잘 설계해야 한다.
-
샤드간의 트랜잭션 문제
-
Global Transaction을 사용하면 샤드 DB간의 트랜잭션도 가능하다.
-
하지만 성능저하 문제가 있다.
-
대표적으로 XA가 있다.
-
-
Global Unique Key
-
DBMS 에서 제공하는 auto-increament를 사용하면 key가 중복될 수 있기 때문에
-
어플리케이션 레벨에서 Key 생성을 담당해야 한다.
-
-
데이터는 작게
- Table의 단위를 가능한 작게 만들어야 한다.
샤딩의 한계
- 샤딩의 대표적인 제약 사항은 다음과 같다.
-
두 개 이상의 샤드에 대한 JOIN 연산을 할 수 없다.
-
auto increment (serial) 등은 샤드별로 달라질 수 있다.
-
last_insert_id() 값은 유효하지 않다.
-
shard key column 값은 update하면 안 된다(delete - insert 사용).
-
하나의 트랜잭션에서 두 개 이상의 샤드에 접근할 수 없다.
- 따라서 샤딩을 사용할 때는 위와 같은 제약 사항이 문제가 되지 않도록 데이터 모델링을 하는 것이 중요하다.
질문
Q. 샤딩(sharding)과 파티셔닝(partitioning)의 차이가 무엇인가?
-
분산 데이터베이스 시스템에서 샤딩과 파티셔닝이라는 단어를 종종 듣는다.
-
하지만 그들의 차이점을 잘 모르겠다.
-
그래서 이것들을 위키에서 검색해보았지만 여전히 혼란스럽다.
A. Tony Bako, Mosaic의 CTO의 답변
-
파티셔닝이란 퍼포먼스(performance), 가용성(availability) 또는 정비용이성(maintainability)를 목적으로
-
당신의 논리적인 데이터 엘리먼트들을 다수의 엔티티(table)로 쪼개는 행위를 뜻하는 일반적인 용어이다.