Prologue
-
업무를 하다 보면 샤딩이란 단어와 파티셔닝이란 단어를 자주 사용한다.
-
각 개념에 대해 기본적인 개념과 헷갈리는 부분을 정리해보자.
샤딩
user_id % 2 == 0 => user_db_0.users 테이블
user_id % 2 == 1 => user_db_1.users 테이블
-
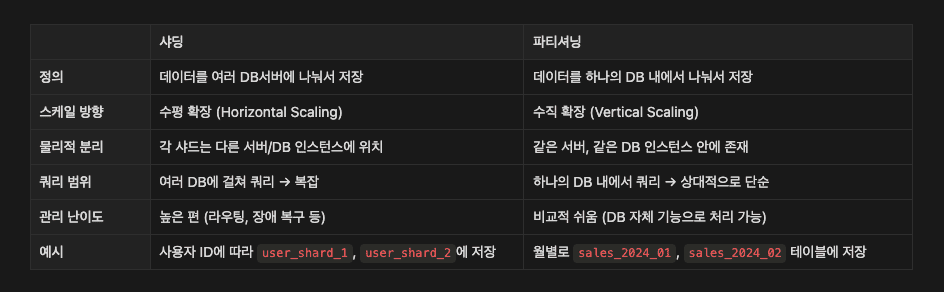
샤딩(Sharding)은 물리적으로 다른 DB에 데이터를 나눠 저장한다.
-
이게 바로 파티셔닝과의 가장 큰 차이점이다.
-
개발자는 저장하려는 데이터를 물리적으로 나뉜 DB에
어떤 기준으로 데이터를 나눠서 저장시킬지 샤딩 정책을 세우고
ShardingSphere와 같은 프레임워크를 사용하여 데이터를 샤딩해서 관리한다.
ShardingSphere
-
ShardingSphere와 같은 프레임워크가
직접 DB에 쿼리를 질의하는 것은 아니고
중간 계층(middleware/router)으로 라우팅과 데이터 병합을 담당한다.
-
어떤 DB에 쿼리를 질의할지 정하고
여러 DB에서 응답을 질의해야 한다면 여러 곳에서 온 응답을 병합하는 역할까지 담당한다.
Example : 단일 테이블에 질의 시
-
애플리케이션은 그냥 SQL을 날림
ex) SELECT * FROM order WHERE user_id = 10 -
ShardingSphere가 설정된 샤딩 키(user_id)와 알고리즘을 보고 어떤 DB와 테이블을 조회할지 결정
-
ShardingSphere가 해당 DB에 SQL 전달
-
SQL 실행은 실제 DB가 진행
-
실행 결과 => ShardingSphere => 애플리케이션으로 반환
Example : N개의 테이블에 나눠서 질의 시
-
애플리케이션은 그냥 SQL을 날림
ex) SELECT * FROM order WHERE status = ‘PAID’ // 샤딩 키 사용 X -
ShardingSphere가 샤딩 키가 없다고 판단하여 모든 샤드 테이블 탐색 결정
-
관련된 모든 샤드 테이블에 SQL 전달
-
SQL 실행은 실제 DB가 진행
-
각 테이블은 병렬적으로 동작 후 질의 결과 응답
-
실행 결과 => ShardingSphere에서 응답 데이터 조합 => 애플리케이션으로 반환
ShardingSphere 사용 이유
샤딩이 없는 상황
-
직접 DB1, DB2, DB3에 각각 쿼리 보내고 결과를 수동으로 병합해야 함
=> 코드 복잡
샤딩 프레임워크 사용 시
-
애플리케이션은 그냥 SELECT * FROM users WHERE user_id = 123 만 보냄
=> ShardingSphere가 알아서 어떤 샤드에 보낼지 정하고, 결과도 깔끔하게 조합해서 응답함
파티셔닝
CREATE TABLE sales (
id INT,
amount DECIMAL,
created_at DATE
)
PARTITION BY RANGE (YEAR(created_at)) (
PARTITION p2023 VALUES LESS THAN (2024),
PARTITION p2024 VALUES LESS THAN (2025)
);
-
겉으로 보기엔 하나의 테이블(sales)처럼 보이지만
DB가 내부적으로 연도 기준으로 여러 파티션으로 나눠서 저장한다.
-
그래서 사용자는 그냥 sales 테이블에 쿼리한다고 생각하지만
DB는 자동으로 적절한 파티션(p2023, p2024)만 조회해서 빠르게 처리한다.
-
즉 하나의 테이블처럼 보이지만 실제론 여러 덩어리로 나뉘어 있는 구조이다.
샤딩이랑 뭐가 다른 거지?…
-
파티셔닝은 책 한 권을 챕터별로 나눈 것이다.
즉 한 권 안에 다 있지만, 목차로 구분된 상태이다.
-
반면 샤딩은 책 내용을 여러 권으로 나눠서 다른 도서관에 둔 것이다.
그러므로 한 곳에서 다 못 보고 분산된 걸 따로 찾아야 한다.
샤딩+파티셔닝 Usecase
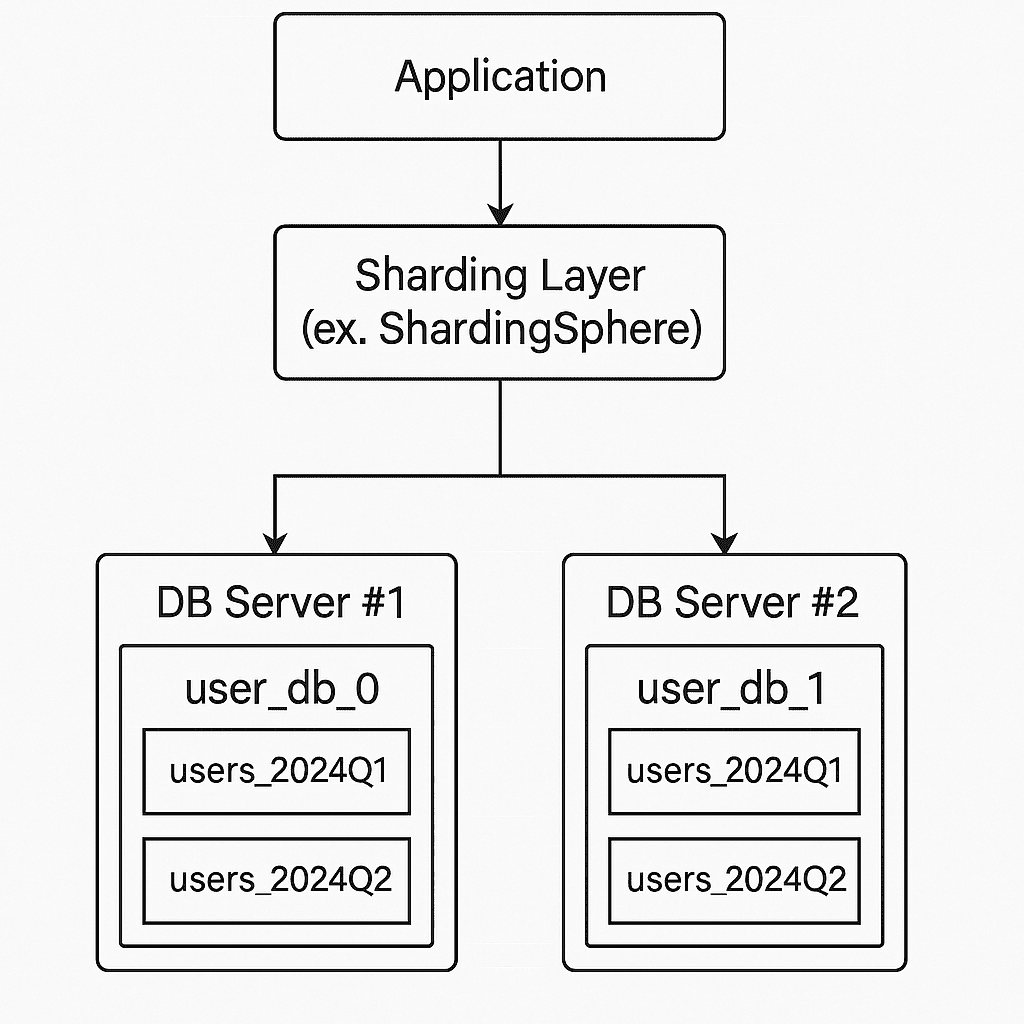
Sharding Layer
-
ShardingSphere, Vitess, Citus 등의 미들웨어를 사용하여 샤딩 로직을 적용하고 관리한다.
-
개발자가 직접 샤딩 조건(ex. user_id로 나눈다)을 지정하고
ShardingSphere, Vitess, Citus는 그 샤딩 전략을 실행하고
분산된 DB에 쿼리를 질의하는 역할을 한다.
-
그러므로 개발자는 DB가 몇 개인지 신경 쓰지 않아도 된다.
샤딩 (Sharding)
-
user_id % 2로 DB를 2개로 나눈다.
ex) user_db_0, user_db_1
-
여러 개의 DB 서버로 분산시켜 저장하고 처리하기 때문에
데이터 양이 엄청나게 많아져도 하나의 서버가 버티지 않아도 된다.
그래서 서버를 하나씩 추가하면서 성능을 수평으로 확장할 수 있게 된다.
파티셔닝 (Partitioning)
-
각 DB 내부의 users 테이블은 분기별로 파티셔닝하므로
쿼리 속도가 빨라진다.
ex) users_2024Q1, users_2024Q2
Summary
-
규모가 커서 여러 DB로 나눠야 함 => 샤딩
-
대규모 트래픽 분산, 수평 확장 필요 => 샤딩
-
운영 간편함 우선 => 파티셔닝
-
단일 DB 서버에서 성능 향상 => 파티셔닝