이 글의 개념 및 코드들은 책을 읽으며 정리한 내용을 바탕으로 작성하였습니다.
웹 로봇
-
1994년 웹 마스터에게
-
로봇의 동작을 더 잘 제어할 수 있는 메커니즘을 제공하는 단순하고 자발적인 기법이 제안되었다.
-
이 표준은 Robots Exclusion Standard 라고 이름이 지어졌다.
-
그리고 로봇의 접근을 제어하는 정보를 저장하는 파일의 이름을 따서 robots.txt라고 부른다.
-
웹 서버는 서버의 문서 루트에 robots.txt 파일을 제공한다.
-
이 파일은 웹 로봇이 서버의 어떤 부분에 접근할 수 있는지에 대한 정보가 담겨있다.
-
만약 웹 로봇이 표준을 따른다면
-
웹 사이트의 리소스에 접근하기전에 우선 사이트의 robots.txt를 요청할 것이다.
robots.txt 가져오기
-
웹 로봇은 HTTP GET 메소드를 이용해 robots.txt를 가져온다.
-
해당 서버에 robots.txt가 존재한다면 text/plain 본문으로 반환한다.
-
만약 서버가 404 NOT Found HTTP를 반환한다면
-
로봇은 접근을 제한하지 않는 것으로 간주하고 모든 리소스를 요청한다.
-
로봇은 사이트 관리자가 접근을 추적할 수 있도록
-
From이나 User-Agent 헤더를 통해 신원 정보를 넘기고
-
사이트 관리자가 로봇에 대해 문의나 불만사항이 있을 경우를 위해 연락처를 제공해야한다.
응답 코드
- 로봇은 robots.txt의 검색 결과에 따라 다르게 동작한다.
HTTP 상태 코드 : 2xx
-
로봇은 반드시 응답의 콘텐츠를 파싱하여 차단 규칙을 얻어야 한다.
-
그리고 해당 사이트에서 리소스를 요청 할 때 규칙을 따라야한다.
HTTP 상태 코드 : 404
-
활성화된 차단 규칙이 존재하지 않는다고 판단한다.
-
어떤 제약도 없이 해당 사이트에 접근하여 리소스를 요청한다.
HTTP 상태 코드 : 401 or 403
- 로봇은 그 사이트로의 접근은 완전히 제한되어 있다고 가정해야 한다.
HTTP 상태 코드 : 503
-
요청 시도가 일시적으로 실패했다면
-
로봇은 그 사이트의 리소스 요청 행위를 미루어야한다.
HTTP 상태 코드 : 3xx
-
서버 응답이 리다이렉션을 의미한다면
-
로봇은 리소스가 발견될 때까지 리다이렉트를 따라가야한다.
robots.txt 파일 포맷
-
robots.txt 파일은 줄 기반 문법을 갖는다.
-
3가지 종류가 있다.
-
빈 줄 : CRLF
-
주석 줄 : #
-
규칙 줄 : [ Key : value ]
-
Example
# goodgid와 good_gid 유저를 제어한다.
User-Agent : goodgid
User-Agent : good_gid
Disallow : /admin
User-Agent : *
Disallow :
-
robots.txt의 줄들은 레코드로 구분된다.
-
위에는 2개의 레코드가 존재한다.
-
각 레코드는 특정 로봇들에 대해 적용시킬 차단 규칙의 집합을 기술한다.
-
User-Agent 줄에는 차단 규칙을 적용시킬 1개 이상의 로봇 이름을 명시한다.
-
그리고 로봇들이 접근할 수 있는 URL들을 명시하는 Allow / Disallow 줄이 온다.
-
이를 토대로 위 Example을 해석해보면 다음과 같다.
-
goodgid, good_gid 유저는 /admin 요청을 제외한 리소스 요청이 가능하다.
-
goodgid_, good_gid 유저를 제외한 모든 유저는(=Asterisk(*))는 접근을 거절한다.
-
User-Agent
사용법 : [ User-Agent : Robot-name ]
-
모든 로봇을 지칭하고 싶다면 Asterisk(*)를 사용하면 된다.
-
로봇의 이름은 로봇의 HTTP Get 요청 안의 User-Agent 헤더를 통해 전달된다.
-
robots.txt 파일을 처리한 로봇은 다음 규칙을 반드시 준수해야한다.
-
로봇 이름이 Asterisk(*)인 레코드에 포함되는 경우
-
로봇 이름이 robots.txt의 User-Agent에 적힌 Robot-name의 부분 문자열이 될 수 있는 경우
-
-
만약 로봇이 자신의 이름에 대응하는 규칙을 찾지 못한다면
-
해당 사이트를 접근하는데 있어 어떤 제한도 없다.
-
참고로 로봇 이름은 대소문자를 구분하지 않는다.
-
또한 부분 문자열과 맞춰보기 때문에 의도치 않게 맞는 경우를 주의해야한다.
Example
-
User-Agent : bot 인 경우
-
Robot-Name이 Bot, Robot, Bottom, Spambot, Bother 등등이 매칭된다.
Allow / Disallow
- Allow / Disallow 규칙을 적용시키는데 몇 가지 주의 사항이 있다.
1st
-
URL 경로가 규칙 경로보다 대소문자 구분 없이 같거나 길어야한다.
-
또한 규칙 경로는 대소문자를 구분하는 URL 경로의 부분 문자열에 포함되어야한다.
-
예를 들어 Disallow : /tmp는 다음의 모든 URL에 대응된다.
http://www.goodgid.com/tmp
- /tmp는 규칙 경로와 길이가 같다.
- /tmp의 부분 문자열은 /tmp 이다.
- 그리고 경로 규칙은 부분 문자열에 포함된다.
http://www.goodgid.com/tmp/
- /tmp/는 규칙 경로보다 길이가 길다.
- /tmp/의 부분 문자열은 /tmp, /tmp/ 이다.
- 그리고 경로 규칙은 부분 문자열에 포함된다.
http://www.goodgid.com/tmp/admin.html
- /tmp/admin.html은 규칙 경로보다 길이가 길다.
- /tmp/admin.html의 부분 문자열은 /tmp, /tmp/, /tmp/a, /tmp/admin.h 등등이다.
- 그리고 경로 규칙은 부분 문자열에 포함된다.
http://www.goodgid.com/tmprint/logo.img
- /tmprint/logo.img은 규칙 경로보다 길이가 길다.
- /tmprint/logo.img의 부분 문자열은 /tmprint, /tmprint/logo, /tmprint/logo.im 등등이다.
- 그리고 경로 규칙은 부분 문자열에 포함된다.
2st
-
규칙 경로나 URL 경로의 임의의 Escaping된 문자들(%XX)은 원래대로 복원된다.
-
단 빗금(/)을 의미하는 %2F는 예외로 반드시 그대로 매치되어야 한다.
3st
- 어떤 규칙 경로가 빈 문자열이라면 그 규칙은 모든 URL 경로와 매칭된다.
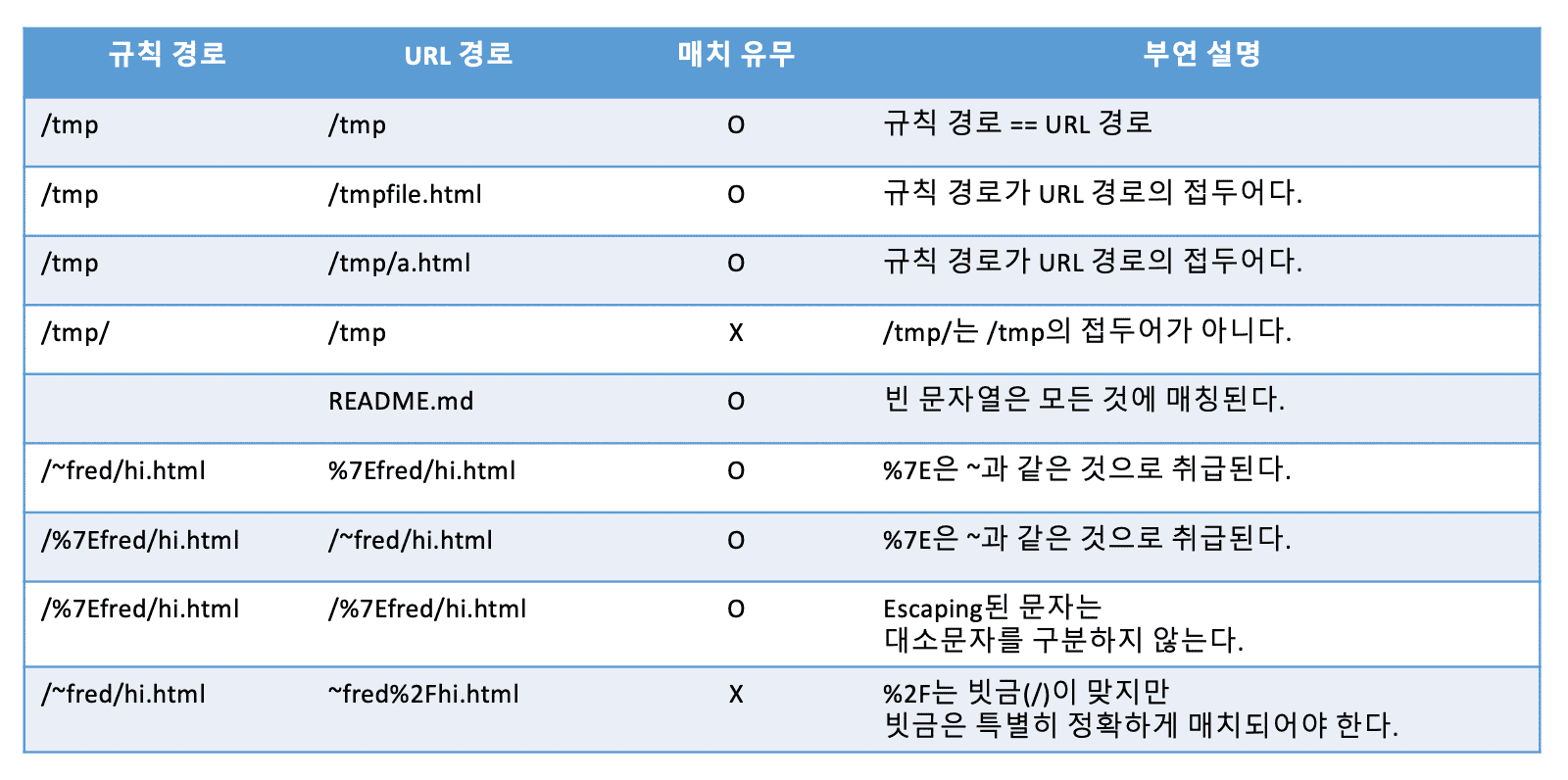
-
3번째 예시에서 URL 경로(= /tmp/a.html )의 부분 문자열은
-
/tmp, /tmp/, /tmp/a, /tmp/a.h 등등이 된다.
-
그리고 이 중에 3번째 예시의 규칙 경로(= /tmp )가 있기 때문에 매칭이된다.
-
4번째 예시에서 URL 경로(= /tmp )의 길이는 4글자다.
-
하지만 규칙 경로(= /tmp/ )는 5글자다.
-
그렇기 때문에 매칭이 되지 않는다.
–
Example
-
To : All robot
Goal : 모든 문서 접근 허락
User-agent: *
Allow: /
-
To : All robot
Goal : 모든 문서 접근 허락 X
User-agent: *
Disallow: /
-
To : All robot
Goal : 3개의 접근만 차단
User-agent: *
Disallow: /a/
Disallow: /b/
Disallow: /c/
-
To : All robot
Goal : 특정 파일 접근 차단
User-agent: *
Disallow: /directory/index.html
-
To : 특정 robot
Goal : 모든 접근 차단
User-agent: badBot
Disallow: /
-
To : 특정 robot
Goal : 특정 디렉토리 접근 차단
User-agent: badBot
User-agent: googlebot
Disallow: /private/
-
To : All robot, 특정 robot
Goal : 각 robot에 맞는 설정
User-agent: googlebot // googlebot robot만 적용
Disallow: /private/ // 해당 디렉토리 접근 차단
User-agent: googlebot-news // googlebot-news robot만 적용
Disallow: / // 모든 디렉토리 접근 차단
User-agent: * // 모든 로봇 적용
Disallow: /something/ // 특정 디렉토리 접근 차단
Summary
-
웹 로봇에 대한 개념을 알아보았다.
-
또한 robots.txt를 작성하는데 있어서 규칙에 대해서도 알아보았다.
-
특히 Allow / Disallow 규칙을 정확히 이해하는 것이 중요하다.