네이버 메인 페이지의 분산 처리
-
로드 밸런서를 사용하는 일반적인 3계층(3-Tier) 분산 처리 모델은 구성 요소에 문제 발생 시 해결하기에 어려움이 있다.
-
그래서 네이버 메인 페이지의 서비스 특성과 요구 사항에 맞는 분산 처리 모델을 구축해 적용하고 있다.
일반적인 분산 처리 모델
- 다음은 로드 밸런서로 구성한 일반적인 3계층(3-Tier) 분산 처리 모델을 표현한 도식이다.
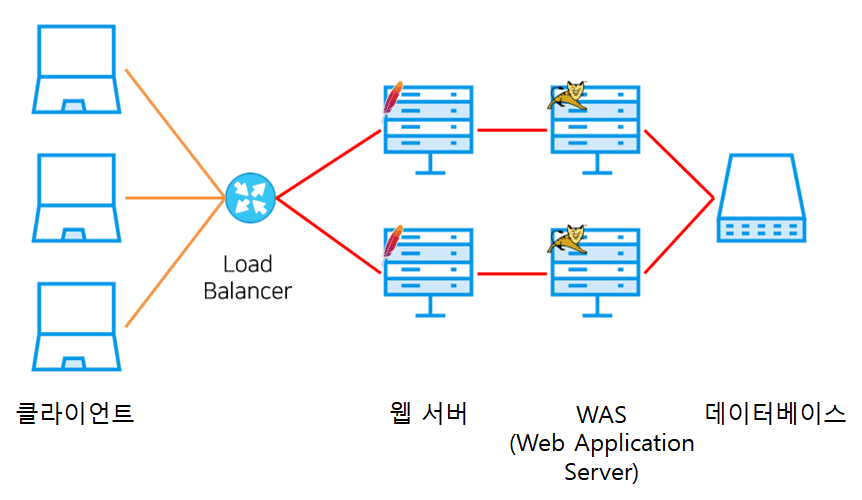
-
클라이언트의 트래픽이 로드 밸런서를 통해 각 웹 서버로 분산된다.
-
WAS는 동일한 데이터베이스를 참조한다.
-
이런 분산 처리 환경에서 각 구성 요소에 문제가 생긴다면 어떻게 처리해야 할까?
-
로드 밸런서에 문제가 생기면 로드 밸런서를 다중화한 다음 DNS 라운드로빈 방식 등을 적용해 문제를 처리할 수 있다.
-
하지만 WAS에 문제가 생기면 다음과 같은 점을 고려해야 하기 때문에 다중화로 문제를 해결하기가 쉽지 않다.
-
WAS에 문제가 생겼을 때 웹 서버가 다른 WAS를 찾도록 해야 한다.
-
사용자가 로그인한 상태라면 WAS에 세션 클러스터링을 설정해야 한다.
-
세션 클러스터링 설정을 위한 추가 작업이 필요하고 관리 지점이 증가한다.
-
-
데이터베이스에서는 다음과 같은 점을 고려해야 하기 때문에 역시 다중화로 문제를 해결하기가 쉽지 않다.
-
데이터 동기화 등의 문제 때문에 데이터 스토리지 레이어는 다중화가 특히 어려운 부분에 속한다.
- 사용하는 데이터베이스가 RDB라면 다중화를 어떻게 할 것인지, 데이터를 어떻게 분산할 것인지에 관해 깊이 고민해야 한다.
-
예를 들어 샤딩 등을 도입했을 때 데이터가 늘어나 샤드를 추가해야 한다면 기존 데이터의 마이그레이션은 어떻게 할지 고민해야 한다.
- 사용하는 데이터베이스가 NoSQL이라면 데이터 정합성, 동기화, 장애 복구 시 다수결에 의한 데이터 오염 가능성 등을 고려해야 한다.
-
분산 처리 모델
-
서비스 특성상 네이버 메인 페이지가 실행하는 역할의 대부분이 데이터를 사용자에게 보여 주는 역할(View)이다.
-
데이터를 받아서 저장하는 동작이 거의 없기 때문에 분산 처리나 다중화에서 트랜잭션을 고려할 필요도 거의 없다.
-
이러한 서비스 특성을 고려해 도출한 요구 사항은 다음과 같다.
-
어떤 서버로 접속해도 동일한 내용을 보여 주어야 하며, 특정 상탯값(사용자의 로그인 여부 등)에 의존하지 말아야 한다.
-
무슨 일이 있더라도 사용자에게 서비스가 제공되어야 한다.
-
브라우저에 빈 페이지가 나타나지 않아야 한다.
- 네이버 메인 페이지에서 연동하는 외부 시스템은 언제든 접속이 불안해질 가능성이 있다고 가정하고
- 빠른 실패 전략을 실행해야 한다.
-
-
트래픽 증가에 탄력적으로 대처할 수 있어야 한다.
-
트래픽이 폭주할 때 서버 증설만으로도 대응할 수 있어야 한다.
-
각 컴포넌트(웹 서버, WAS)의 효율성을 극대화할 수 있어야 한다.
-
-
- 네이버 메인 페이지의 서비스 특성과 요구 사항을 반영한 네이버 메인 페이지의 분산 처리 모델을 간략하게 표현하면 다음과 같다.
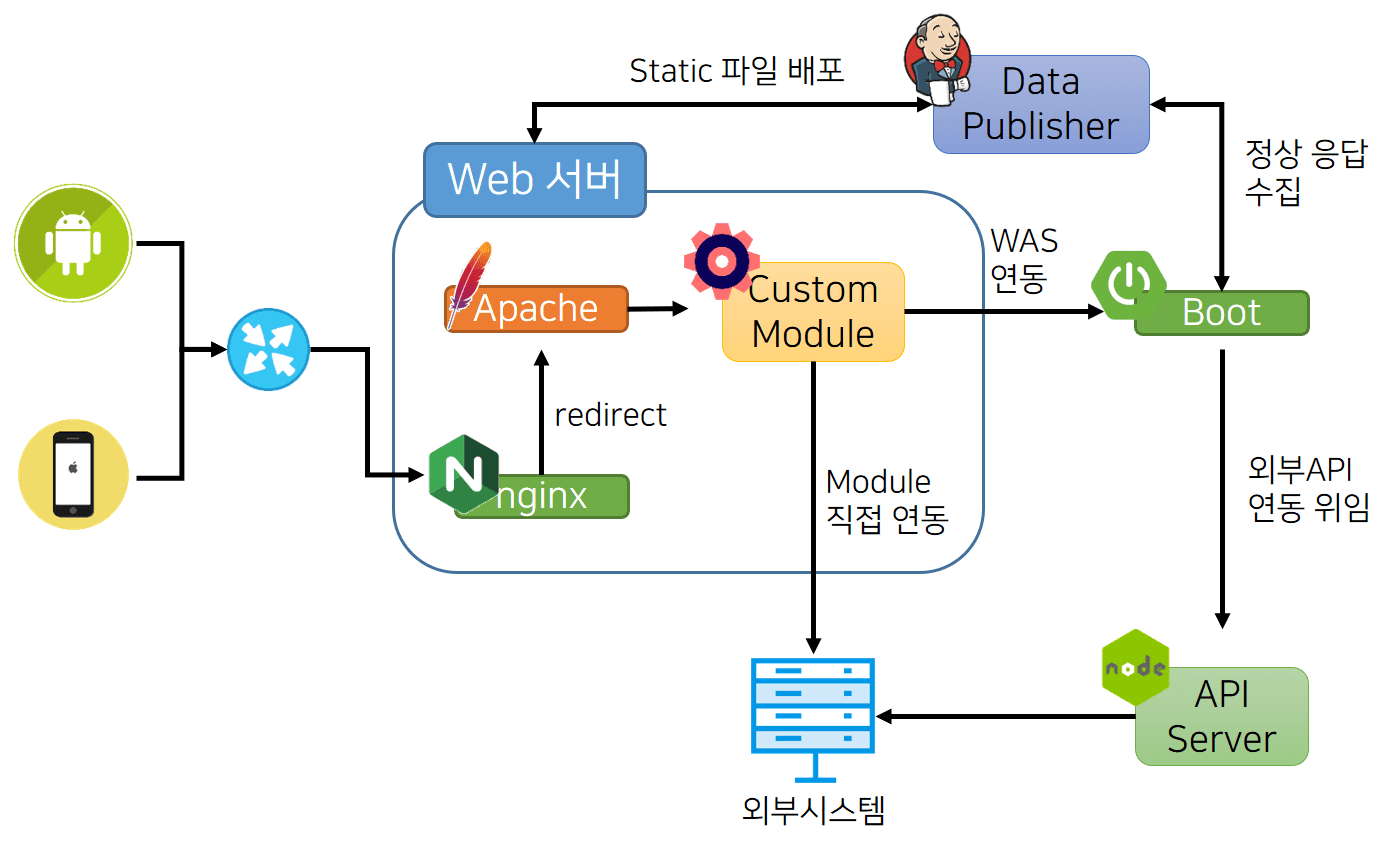
분산 처리 기술
- 네이버 메인 페이지의 분산 처리에는 다음과 같은 기술이 사용된다.
-
GCDN(Global CDN)
-
SSI(Server Side Includes)
-
마이크로서비스(부분 도입)
-
서킷 브레이커(circuit breaker)
-
서비스 디스커버리(service discovery)
-
GCDN(Global CDN)
-
CSS와 JavaScript, 이미지와 같이 공통으로 호출되는 리소스는 한 번 업로드되면 잘 변하지 않는다.
-
이런 리소스를 네이버 메인 페이지의 웹 서버에서 직접 제공하면 트래픽 부하가 엄청나게 가중된다.
-
예를 들어 100KB 용량의 이미지를 10만 명이 조회하면 대략 10GB의 트래픽이 발생한다.
-
그래서 공통적으로 호출되는 리소스의 부하 분산을 위해 GCDN을 사용한다.
-
리소스를 GCDN으로 분산하면 네이버 메인 페이지의 트래픽을 상당히 절감할 수 있다.
-
또한 GCDN에서 지원하는 GSLB(Global Server LB) 기능은
-
접속한 IP 주소에서 가장 가까운 CDN 서버를 자동으로 선정해 연결하기 때문에 사용자가 빠른 서비스 속도를 체감할 수 있다.
SSI(Server Side Includes)
-
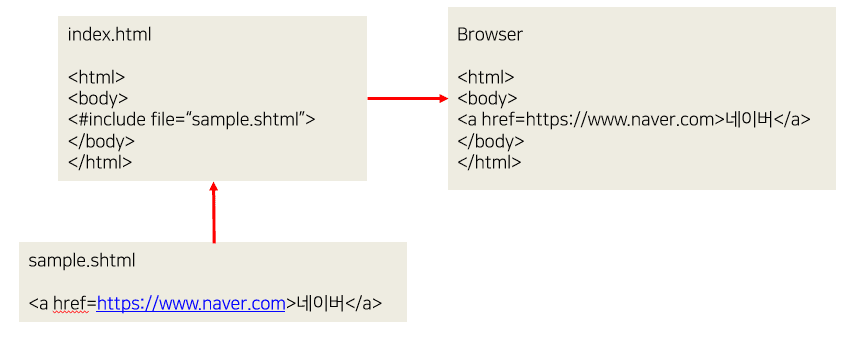
SSI는 웹 서버(Apache, NGINX 등)에서 지원하는 서버사이드 스크립트 언어다.
-
서버에 있는 특정 파일을 읽어오거나 특정 쿠키 유무의 판별 등 간단한 기능을 실행할 수 있다.
-
이런 기능을 WAS에서만 실행할 수 있다고 생각하고 WAS에 요청을 보내는 경우가 많다.
-
하지만 SSI를 사용해 웹 서버에서 기능을 처리하면 WAS의 부담을 줄여 WAS의 성능에 여유를 줄 수 있게 되고
-
웹 서버의 활용도도 높여 서버의 자원을 더 효율적으로 사용할 수 있다.
마이크로서비스의 부분 도입
- 네이버 메인 페이지에서는 다른 시스템과 연관성이 적은 독립적인 기능을 별도 서비스로 분리해 구축했다.
-
외부 시스템과 API 연동을 담당하는 부분은 특히 Node.js로 구축했다.
-
네이버 메인 페이지에서는 동시에 여러 대의 외부 시스템과 API 연동을 실행해야 하는 경우가 많다.
-
Node.js를 사용하면 병렬 처리 시 스레드 문제 등을 고려할 필요가 없고
-
비동기식으로 외부 시스템 연동 시 병렬로 여러 개의 요청을 한 번에 처리할 수 있다.
-
그래서 이러한 기능을 구현하기에는 기존에 사용하던 Java보다는 Node.js로 구현하는 것이 더 유리하다고 판단했다.
-
또한 부서 내 언어적 다양성을 확보해 용도에 맞는 적절한 기술을 사용할 수 있고
-
부서원의 기술 역량 향상에 도움을 주는 장점도 있다.
-
API 서버에는 또한 서킷 브레이커를 적용했다.
-
WAS에는 서버의 모니터링과 관리를 위해 서비스 디스커버리를 적용했다.
서킷 브레이커
-
서킷 브레이커는 외부 서비스의 장애로 인한 연쇄적 장애 전파를 막기 위해
-
자동으로 외부 서비스와 연결을 차단 및 복구하는 역할을 한다.
-
서킷 브레이커를 사용하는 목적은 애플리케이션의 안정성과 장애 저항력을 높이는 데 있다.
-
분산 환경에서는 네트워크 일시 단절 또는 트래픽 폭증으로 인한 간헐적 시간 초과 등의 상황이 종종 발생한다.
-
이로 인해 다음과 같은 연쇄 장애가 발생할 가능성이 있다.
-
트래픽 폭증으로 인해 API 서버 등 외부 서비스의 응답이 느려진다.
-
외부 서비스의 응답이 타임아웃 시간을 초과하면 데이터를 받아오기 위해 외부 서비스를 다시 호출한다.
-
이전에 들어온 트래픽을 다 처리하지 못한 상태에서 재시도 트래픽이 추가로 적체되어 외부 서비스에 장애가 발생한다.
-
외부 서비스의 장애로 인하여 데이터를 수신하지 못해 네이버 메인 서비스에도 장애가 발생한다.
-
일시적인 경우라면 2, 3회 재시도로 정상 데이터를 수신할 수 있다.
-
하지만 장애 상황이라면 계속 재시도하는 것이 의미도 없을 뿐 아니라 외부 서비스의 장애 복구에 악영향을 미칠 수 있다.
-
이럴 때는 외부 서비스에서 데이터를 받아오는 것을 포기하고
-
미리 준비된 응답을 사용자에게 전달하는 것이 시스템 안정성 및 사용 편의성 측면에서 옳다고 할 수 있다.
- 다음 그림은 서킷 브레이커에서 서킷의 상태 변화를 나타내는 그림이다.
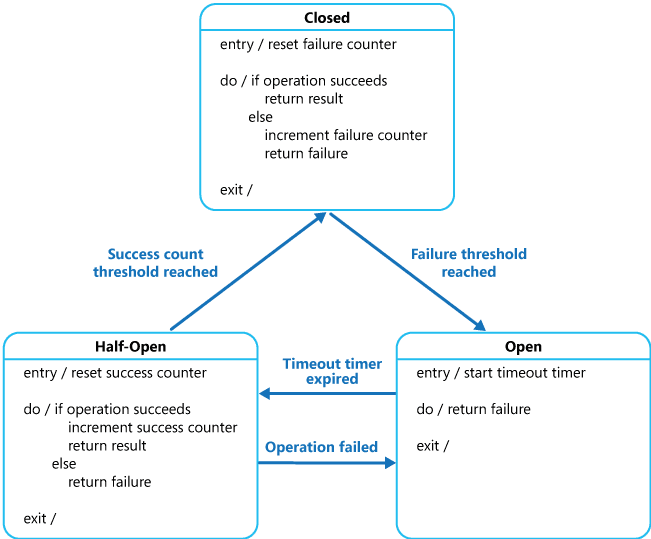
-
서킷은 다음과 같은 세 가지 상태를 가진다(회로이므로 닫힌 것이 정상, 열린 것이 비정상).
-
Closed 상태: 메서드가 정상적으로 작동해 서킷이 닫힌 상태
-
Open 상태: 메서드에 문제가 생겨서 서킷이 열린 상태
- Half-Open 상태: Open 상태와 Closed 상태의 중간 상태.
- 메서드를 주기적으로 확인해 정상이라고 판단되면 Closed 상태로 상태를 전환하고, 정상이 아니라면 Open 상태를 유지한다.
-
-
서킷이 Closed 상태에서 잘 작동하고 있다가 오류가 발생하기 시작해서 일정 횟수에 도달하면 일단 서킷을 Open 상태로 전환한다.
-
이때 메서드를 호출해도 실제로 메서드가 실행되는 대신
-
서킷 브레이커가 개입해 미리 지정된 응답(단순 실패를 반환할 수도 있고 특정한 값을 반환할 수도 있음)을 반환한다.
-
특정 주기 동안 Open 상태로 유지하고 있다가
-
서킷이 자체적으로 메서드가 정상으로 작동하는지 확인하는데 이 상태가 Half-Open 상태다.
-
Half-Open 상태에서 메서드를 몇 번 호출해서 정상 응답이 돌아온다면
-
서킷은 다시 Closed 상태로 전환되어 요청을 처리한다.
-
몇 번 호출했는데 계속 실패가 반환된다면 서킷은 Open 상태로 유지된다.
서비스 디스커버리
- 서비스 디스커버리는 동적으로 생성, 삭제되는 서버 인스턴스에 대한 IP 주소와 포트를 자동으로 찾아 설정할 수 있게 하는 기능이다.
-
다음은 서비스 디스커버리를 사용하지 않는 서버군의 환경을 나타낸 그림이다.
-
서버군 1과 서버군 2가 서로 다른 기능을 실행하는 서버군이라고 가정한다.
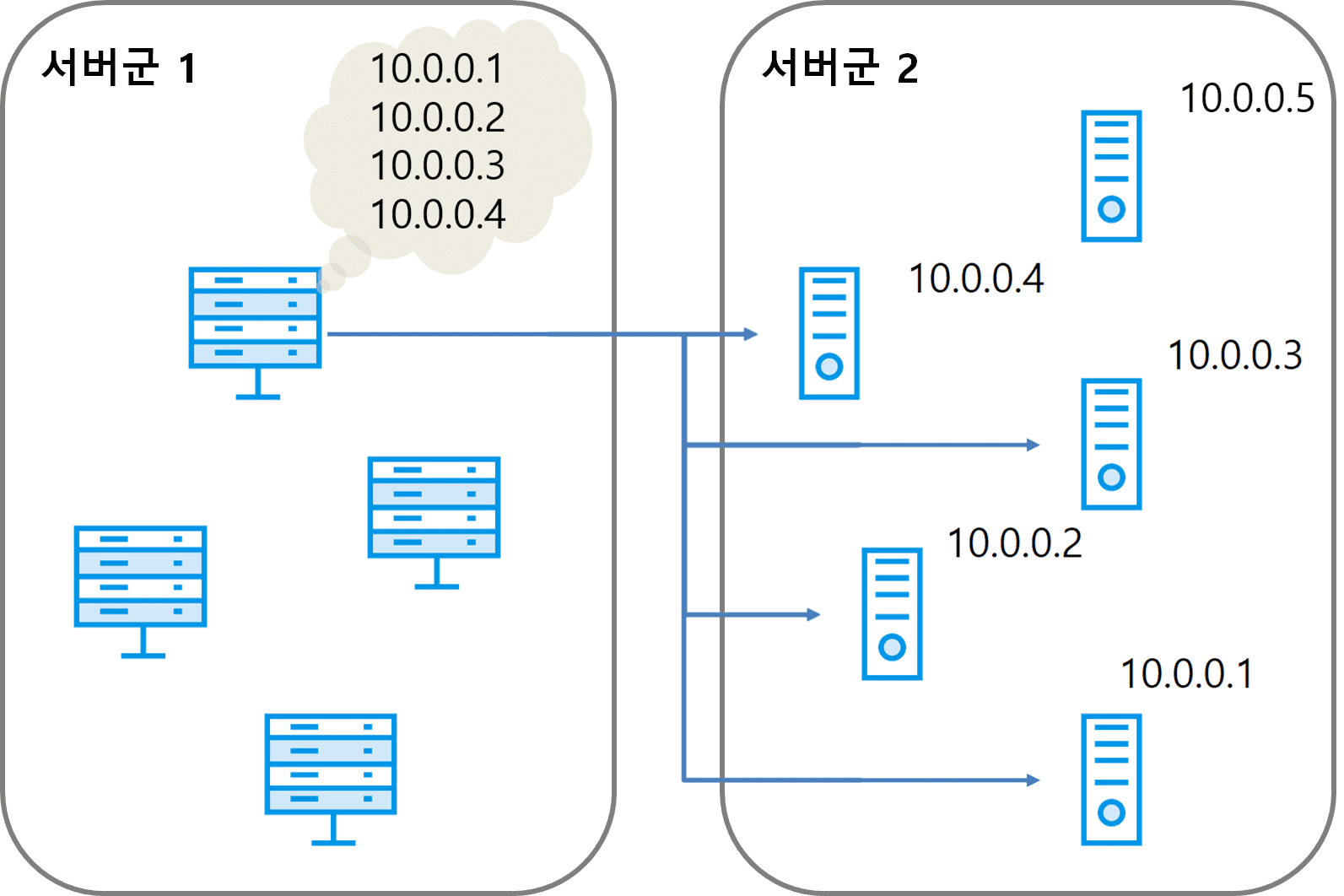
-
서버군 2에서 10.0.0.5 서버가 신규로 생성됐지만
-
서버군 1에서는 10.0.0.5 서버로 연결을 맺을 수 없다.
-
서버군 1이 최초에 실행됐을 때에는 10.0.0.5 서버가 없었기 때문에
-
서버 목록에 10.0.0.5 서버가 없기 때문이다.
-
서버 목록을 갱신하려면 서버군 1에 있는 서버를 다시 실행해야 한다.
-
하지만 롤링 리스타트를 한다고 해도 서비스를 운영하는 도중에 서버를 다시 실행하는 것은 매우 위험하다.
- 다음은 서비스 디스커버리를 도입한 환경을 나타내는 그림이다.
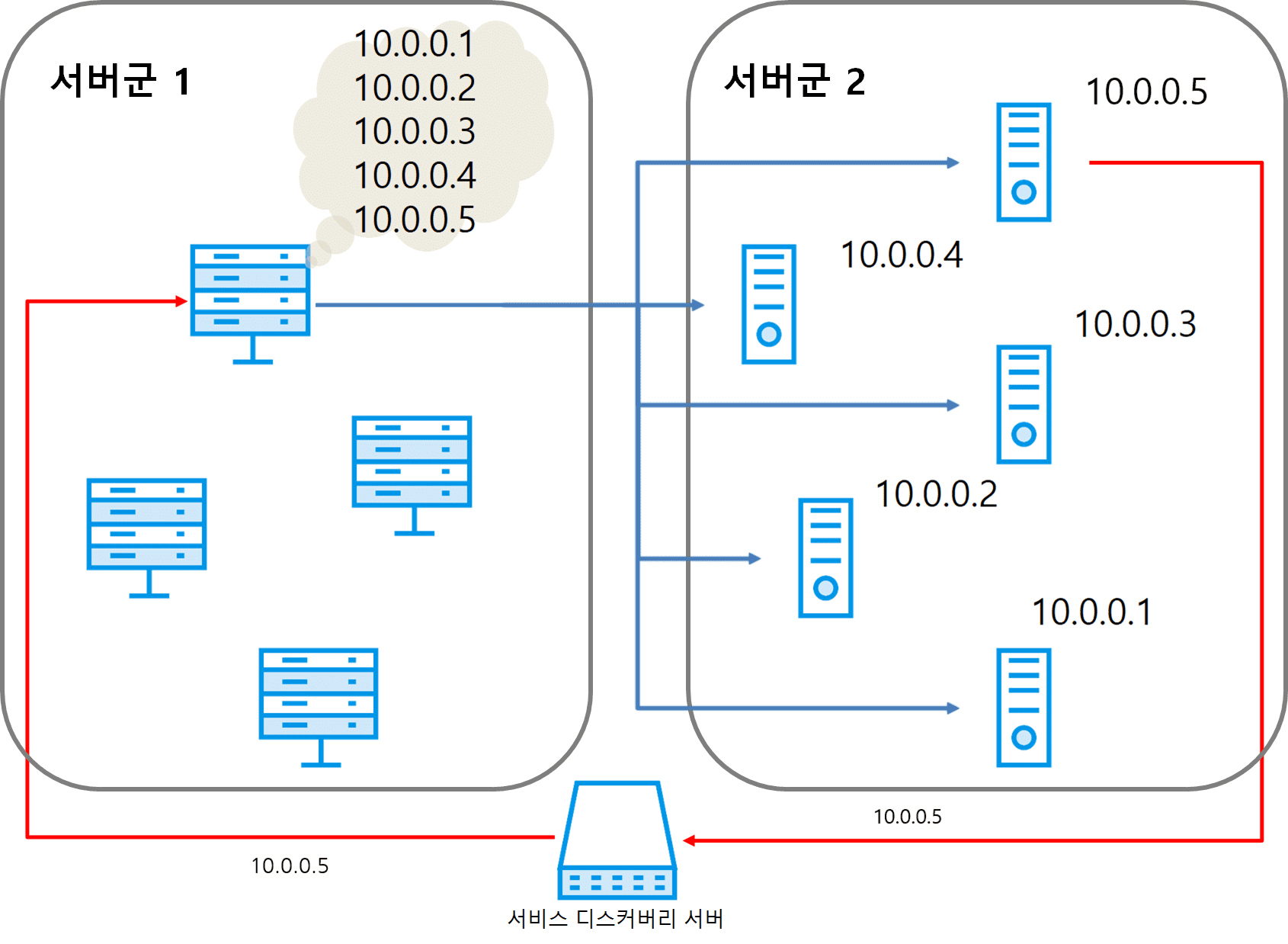
-
서비스 디스커버리 서버는 각 서버군의 서버 목록을 관리한다.
-
서버는 시작할 때 자신의 정보(IP 주소, 포트)를 서비스 디스커버리 서버로 보내고
-
서비스 디스커버리 서버는 이 정보를 받아 서버군의 서버 목록을 최신으로 갱신한다.
-
각 서버군에 있는 서버는 주기적으로 서비스 디스커버리 서버로 목록을 요청해 서버 목록을 최신으로 유지한다.
-
이러한 방법으로 서버는 재시작 등 외부의 개입이 없어도 자동으로 항상 최신 서버 목록을 확보할 수 있다.
-
예를 들어 10.0.0.5 서버가 추가되면 서버군 2의 서버 목록이 갱신되고
-
이 목록을 받아서 서버군 1의 서버가 자신의 서버 목록을 갱신하면
-
외부의 개입 없이 10.0.0.5 서버에 연결할 수 있게 된다.
-
서비스 디스커버리는 특히 클라우드 환경에서 빛을 발한다.
-
기존 온프레미스(on-premises) 환경에서는 서버를 추가, 삭제하는 일이 많지 않았다.
-
서버를 추가, 삭제하는 경우에도 통제된 환경에서 주로 작업하므로 갱신 문제가 크지 않다.
-
하지만 클라우드 환경에서는 수시로 서버가 추가, 삭제된다.
-
특히 오토스케일링 등의 기능을 사용한다면 더더욱 발생한다.
-
이를 사람이 일일이 확인해 서버를 다시 실행하는 것은 불가능에 가깝다.
-
서비스 디스커버리는 이런 상황에서 아주 유용하게 사용할 수 있는 기술이다.