- 인덱스 구조
- 인덱스 스캔
- 인덱스 스캔을 이용한 질의 처리 과정
- 인덱스 사용하기
- 인덱스 활용 최적화
- Key Filter 활용
- 커버링 인덱스
- 정렬 연산 대체
- LIMIT 최적화
- 은 총알은 없다(No Silver Bullet)
- Reference
-
DBMS는 저장되어 있는 데이터를 효율적으로 검색할 수 있게 인덱스를 사용한다.
-
웹 애플리케이션의 백엔드 성능을 높이려고 종종 실행하는 SQL 튜닝이란
-
SQL이 DBMS의 인덱스를 활용하도록 SQL을 수정하는 것이라고 할 수 있다.
-
그러니 인덱스를 잘 이해하고 있다면 더 좋은 SQL을 작성할 수 있을 것이고
-
훨씬 더 성능 좋은 애플리케이션을 만들 수 있을 것이다.
-
이 글에서는 CUBRID를 중심으로 알아본다.
인덱스 구조
-
거의 모든 DBMS는 B-Tree 계열 인덱스를 사용한다.
-
인덱스 종류에 대한 특별한 언급이 없다면 아마도 B-Tree 계열 인덱스를 의미할 것이다.
-
CUBRID는 B+-Tree를 이용하고 있다.
-
B+-Tree는 B-Tree의 한 종류로서
-
일반적인 B-Tree와 달리 데이터 포인터를 리프(Leaf) 노드에만 저장한다.
-
리프 노드의 상위 레벨인 비리프(Non-Leaf) 노드는 전형적인 B-Tree 로 구성되며 리프 노드를 빠르게 찾는 인덱스 역할을 한다.
-
리프 노드에는 키와 키에 대응하는 데이터의 포인터가 저장되어 있다.
-
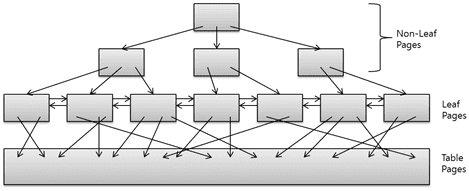
다음 그림은 전형적인 B+-Tree 모습이다.
인덱스 스캔
-
B+-Tree의 리프 노드는 링크드 리스트(linked list)로 서로 연결되어 있고
-
저장된 키는 정렬되어 있어서 순차 처리가 용이하다.
-
그렇기 때문에 범위를 검색하는 데 유리하다.
-
테이블에서는 처음부터 끝까지 모든 레코드를 읽어야 완전한 결과 집합을 얻을 수 있지만
-
인덱스는 키-컬럼 순으로 정렬되어 있기 때문에 특정 위치에서 검색을 시작해서 검색 조건이 일치하지 않는 값을 만나는 순간 검색을 멈출 수 있다.
-
이것을 인덱스 범위 스캔(Index Range Scan)이라고 한다.
-
CUBRID는 범위 스캔을 B+-Tree 검색의 기본 연산으로 제공하고 있다.
-
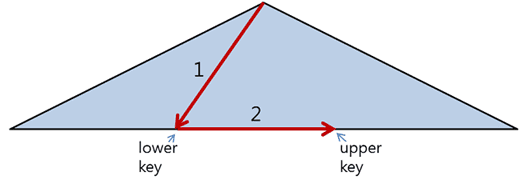
범위 스캔에는 두 개의 키가 필요한데
-
범위의 양 끝을 표현하는 하위 키(Lower Key)와 상위 키(Upper Key)이다.
-
인덱스 범위 스캔은 다음 그림과 같이 두 단계로 진행된다.
-
첫 번째 단계에서는 루트에서부터 트리를 순회하여 리프 노드에서 하위 키를 찾는다.
-
두 번째 단계에서는 첫 번째 단계에서 찾은 키에서부터 상위 키까지 순차적으로 레코드를 읽어 처리한다.
-
상위 키가 현재 노드에서 발견되지 않으면 다음 노드를 읽어 상위 키를 가진 노드까지 검색을 계속해 나간다.
-
상위 키까지 순차 검색이 끝나면 전체 범위 검색이 완료된다.
-
두 번째 단계에서 상위 키까지 찾아가는 과정은 레코드에서 키를 읽어와 상위 키와 비교하는 과정의 연속이다.
-
상위 키가 최대 키이면 현재 노드의 키부터 마지막 노드까지 모두 검색 결과에 포함되기 때문에
-
비교 연산을 할 필요가 없어져서 검색의 성능이 좋아진다.
-
검색 성능을 위해 옵티마이저는 입력된 쿼리를 재작성(rewrite)하며
-
CUBRID는 특정 키를 찾는 검색도 범위 검색으로 변환하여 수행한다.
-
특정 키를 찾는 검색을 범위 검색으로 변환할 때에는 하위 키와 상위 키 모두를 찾으려는 키로 동일하게 설정한다.
인덱스 스캔을 이용한 질의 처리 과정
-
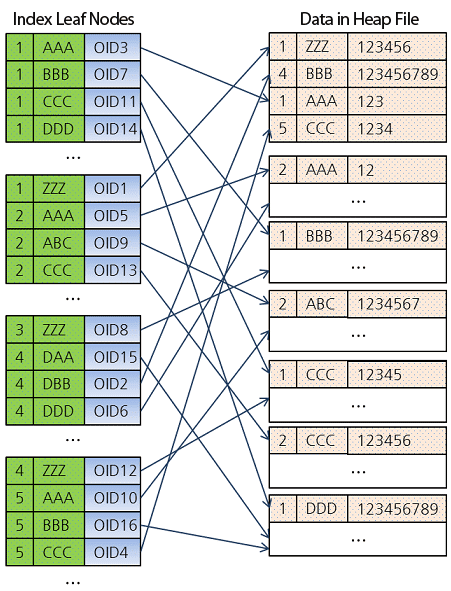
다음 그림은 CUBRID에서 아래의 SQL 질의로 테이블과 인덱스를 생성하고 데이터를 입력했을 때
-
인덱스 리프 노드와 테이블 데이터의 관계를 나타낸 그림이다.
-
왼쪽 인덱스 리프 노드에는 인덱스 키와 키에 대응 되는 OID(레코드의 물리적 주소 값)가 저장되어 있다.
CREATE TABLE tbl
(a INT NOT NULL,
b STRING,
c BIGINT);
CREATE INDEX idx ON tbl
(a, b);
INSERT INTO tbl VALUES
(1, 'ZZZ', 123456),
(4, 'BBB', 123456789),
(1, 'AAA', 123'),
…
(이하 생략)
SELECT * FROM tbl
WHERE a > 1 AND a < 5
AND b < 'K'
AND c > 10000
ORDER BY b;
-
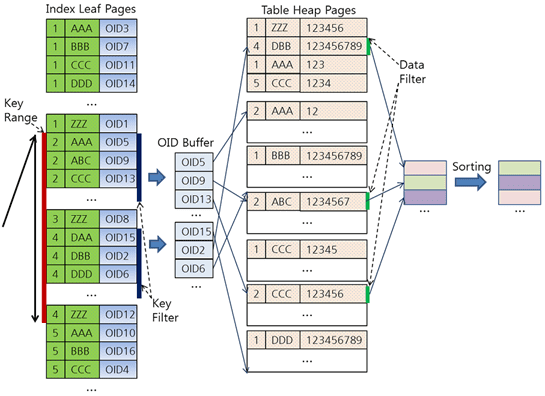
위와 같은 SELECT 질의에서 WHERE 절에 있는 검색 조건은 다음과 같이 3가지로 나눌 수 있다.
-
Key Range: 인덱스 스캔 범위로 활용하는 조건이다(a > 1 AND a < 5)
-
Key Filter: Key Range에 포함할 수 없지만 인덱스 키로 처리 가능한 조건이다(b < ‘K’)
-
Data Filter: 인덱스를 사용할 수 없는 조건이다. 테이블에서 레코드를 읽어야만 처리 가능한 조건이다(c > 10000)
-
-
CUBRID의 질의 처리 과정은 다음과 같다.
- 인덱스 스캔인 경우 먼저 Key Range와 Key Filter를 적용하여 조건에 부합하는 OID 리스트를 만든다.
-
이 과정은 Key Range의 시작부터 끝까지 계속된다.
- OID를 이용해 데이터 페이지에서 해당 레코드를 읽어 Data Filter를 적용하거나
-
SELECT 리스트에 기술된 컬럼 값을 읽어와 결과를 저장하는 임시 페이지에 기록한다.
- ORDER BY 절이나 GROUP BY 절이 있으면 임시 페이지에 저장된 레코드를 정렬하여 최종 결과를 생성한다.
- 다음 그림은 위의 SELECT 질의가 처리되는 과정이다.
인덱스 사용하기
-
옵티마이저가 인덱스를 사용하게 하려면 WHERE 절에 범위(Range) 조건이 있어야 한다.
-
범위 조건은 “크다, 작다, 크거나 같다, 작거나 같다, 같다”와 같은 비교문으로 기술한다.
-
만약 범위 조건이 없다면 옵티마이저는 테이블 순차 스캔을 시도할 것이다.
-
두 개 이상의 컬럼을 묶어서 인덱스를 만들 때는 컬럼의 순서가 매우 중요하다.
-
이런 인덱스를 다중 컬럼 인덱스(Multi-Column Index) 또는 복합 인덱스라고 한다.
-
복합 인덱스에서는 WHERE 절에 인덱스 키의 첫 번째 컬럼을 사용해야 인덱스 스캔을 수행한다.
-
인덱스가 여러 컬럼으로 조합되어 있을 때
-
컬럼 가운데 한 가지 컬럼만 사용해도 무방하다고 알려져 있는데 잘못 알려진 것이라고 할 수 있다.
-
첫 번째 컬럼이 없는 상태에서는 두 번째 컬럼이 정렬된 상태라고 할 수 없기 때문에 범위를 정의할 수 없다.
-
따라서 반드시 첫 번째 컬럼이 조건에 있어야 하며 첫 번째 이후의 컬럼은 조건에 없어도 상관없다.
-
인덱스는 값의 대소 비교를 토대로 트리를 구성한다.
-
따라서 값의 대소 비교가 아닌 조건은 B+-Tree를 사용해서 값을 찾을 수 없다.
-
<>, != 와 같이 부정형 조건이나 NULL 비교는 인덱스를 사용할 수 없다.
-
인덱스의 컬럼을 조건절에서 가공할 때도 인덱스를 사용할 수 없다.
-
다음은 인덱스를 사용하지 못하는 쿼리와 튜닝 후 인덱스를 사용하도록 수정한 쿼리의 예이다.

-
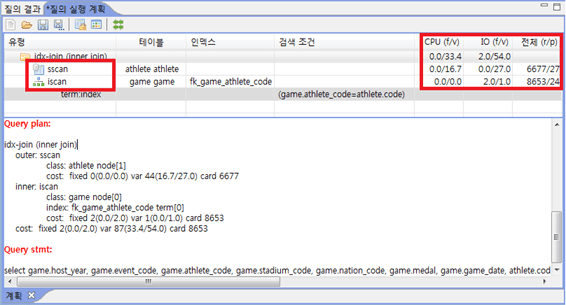
작성한 SQL 질의가 DBMS에서 실행될 때 인덱스 스캔을 이용하는지 확인하려면 질의 실행 계획을 출력해 봐야 한다.
-
CUBRID Manager의 질의 편집기에 질의 실행 계획을 출력하는 기능이 있다.
-
다음 그림은 CUBRID Manager에서 질의 실행 계획을 출력한 예다.
-
질의 실행 계획에서는 테이블 스캔(sscan)이나 인덱스 스캔(iscan) 여부
-
예상되는 CPU 및 I/O 비용, 예상 결과 집합의 레코드 개수, 예상 페이지 접근 개수 등을 볼 수 있다.
인덱스 활용 최적화
-
B+-Tree는 특성상 어떤 리프 페이지에 접근하든 거의 동일한 비용이 든다.
-
B+-Tree를 사용할 때 가장 큰 비용이 드는 부분은
-
Key Range의 시작부터 끝까지 인덱스 리프 노드를 따라 진행하는 스캔과
-
여기에 대응하는 테이블 데이터의 스캔이다.
-
대부분의 DBMS가 페이지(또는 블록) 단위로 I/O를 수행하며 CUBRID도 예외는 아니다.
-
즉 하나의 레코드에서 하나의 컬럼만 읽으려 해도 레코드가 속한 페이지 전체를 디스크로부터 읽어온다.
-
따라서 질의 성능을 좌우하는 가장 중요한 성능 지표는 I/O를 수행하는 페이지 개수이며
-
이 개수는 옵티마이저의 판단에 가장 큰 영향을 미친다.
-
옵티마이저가 인덱스를 읽을지 테이블을 읽을지 결정하는데 있어 가장 중요한 판단 기준은
-
읽어야 할 레코드 가 아니라 읽어야 할 페이지 개수인 것이다.
-
디스크 I/O는 메모리 액세스에 비해 비용이 아주 크다.
-
질의 수행에 필요한 모든 데이터 페이지와 인덱스 페이지를
-
데이터베이스 버퍼에 로드해서 처리할 수 있다면 좋지만 그러기에는 한계가 있다.
-
결국 디스크 I/O를 최소화하고 대부분의 연산을 데이터베이스 버퍼에서 처리할 수 있도록
-
질의 처리 과정에서 액세스하는 페이지 수를 최소화하는 것이 튜닝의 핵심이다.
-
액세스하는 페이지 수가 적으면 자연스럽게 물리적으로 디스크에서 읽어야 할 페이지 수도 줄기 때문에
-
데이터베이스 버퍼 히트율(DB buffer hit ratio)이 높아져서 데이터베이스의 전체적인 성능이 높아진다.
-
그러면 지금부터 인덱스 스캔 과정에서 액세스해야 할 페이지 수를 줄일 수 있는 기법을 알아보자.
Key Filter 활용
-
앞서 설명한 바와 같이 Key Filter는
-
Key Range에는 포함되지 않지만 인덱스 키로 처리할 수 있는 조건이다.
-
이러한 Key Filter가 WHERE 조건절에 포함되면 데이터 페이지에 접근하는 횟수를 줄일 수 있다.
-
데이터 페이지는 랜덤 액세스로 읽기 때문에 인덱스 페이지 스캔보다 많은 비용이 든다.
-
따라서 WHERE절에 Key Filter를 포함하면 성능 향상에 유리하다.
-
또한 Data Filter가 Key Filter로 적용될 수 있도록 인덱스에 컬럼을 추가하는 것도 방법이 될 수 있다.
-
예를 들어 user 테이블에 (groupid, name)으로 구성된 인덱스 idx_1이 있는 상태에서 아래 질의를 수행한다고 하자.
SELECT * FROM user
WHERE groupid = 10
AND age > 40;
-
groupid=10인 조건을 만족하는 레코드가 100건이고 그 중 age > 40인 레코드가 10건이라고 하면
-
인덱스 스캔으로 100건의 OID를 가져온 후 최악의 경우 데이터 페이지로 100회의 액세스를 수행할 것이다.
-
그러나 idx_1 인덱스에 age 컬럼을 추가하여 (groupid, name, age)로 만들면
-
age > 40 조건이 Key Filter 조건으로 처리되어 인덱스 스캔으로 10건의 OID만 추출할 수 있다.
커버링 인덱스
-
만약 사용하는 인덱스로 SELECT 질의에 대한 결과를 모두 얻을 수 있는 상황이라면
-
데이터 페이지에 저장되어 있는 레코드를 읽어오지 않아도 인덱스 키의 값만으로도 결과를 얻을 수 있다.
-
이와 같이 인덱스가 하나의 질의를 모두 커버 한 경우를 커버링 인덱스(Covering Index)라고 한다.
-
CUBRID 2008 R4.0는 커버링 인덱스를 지원한다.
SELECT a, b FROM tbl
WHERE a > 1 AND a < 5
AND b < 'K'
ORDER BY b;
-
위의 SQL 질의에서 커버링 인덱스를 적용할 수 있다.
-
질의에 사용한 컬럼은 a, b 뿐이고 모두 인덱스 컬럼이기 때문이다.
-
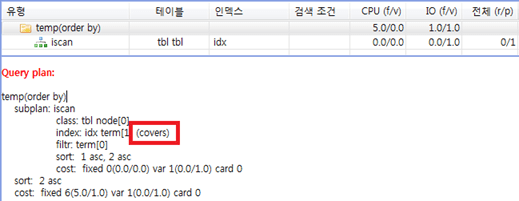
질의에 커버링 인덱스가 활용되는지 확인하려면
-
다음 그림과 같이 질의 실행 계획에 covers라는 표시가 있는지 보면 된다.
-
커버링 인덱스는 데이터 페이지를 읽지 않는다는 점
-
그리고 해당 질의를 자주 사용하면 인덱스가 데이터베이스 버퍼에 캐시되어 있을 가능성이 높다는 점에서
-
디스크 I/O를 줄이는 데 큰 역할을 한다.
-
따라서 레코드 크기에 비해 인덱스 키의 크기가 작고
-
커버링 인덱스를 이용하는 질의가 자주 수행되는 것이 확실하다면
-
커버링 인덱스를 사용하여 SELECT 질의 성능을 크게 향상시킬 수 있다.
정렬 연산 대체
-
인덱스 스캔으로 생성한 결과 집합 은 인덱스 컬럼 순으로 정렬된 상태이므로
-
ORDER BY 절이나 GROUP BY 절에 의한 정렬 연산을 생략하도록 질의를 작성할 수 있다.
-
정렬 연산을 생략하려면 인덱스 컬럼의 순서대로 ORDER BY 절이나 GROUP BY 절에 컬럼이 지정되어야 한다.
-
예를 들어 인덱스 키가 (a, b)로 되어 있다면
-
“ORDER BY a” 또는 “ORDER BY a, b”처럼 정렬할 컬럼이 명시되어야 한다.
-
“ORDER BY b”는 정렬 연산을 대체할 수 없다.
-
인덱스 (a, b)에서 b는 a가 같은 값일 경우에만 정렬된 상태를 보장하기 때문이다.
-
하지만 “a = 2”와 같은 조건이 WHERE 절에 있다면 “ORDER BY b”도 정렬 연산을 대체할 수 있다.
-
즉 인덱스 컬럼이 조건절에서 ‘=’ 연산자로 동등 비교되는 경우에는
-
(= “a = 2”와 같은 조건이 WHERE 절에 있다면)
-
해당 컬럼이 ORDER BY나 GROUP BY 절에서 중간에 생략되어도 된다.
-
(= “ORDER BY b”도 정렬 연산을 대체할 수 있다.)
-
GROUP BY에 대한 정렬 연산 대체는 CUBRID 2008 R4.0부터 지원된다.
-
아래 질의는 정렬 연산 없이 인덱스 스캔만으로 정렬된 결과를 만들어 내는 예이다.
SELECT * FROM tbl
WHERE a = 2 AND b < 'K'
ORDER BY b;
SELECT COUNT(*) FROM tbl
WHERE a > 1 AND a < 5
AND b < 'K'
AND c > 10000
GROUP BY a;
-
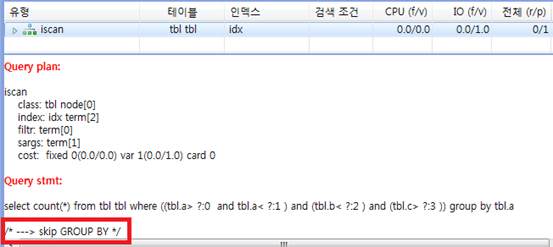
정렬 연산이 인덱스 스캔으로 대체되는지 확인하려면
-
다음 그림과 같이 질의 실행 계획에 skip ORDER BY 또는 skip GROUP BY가 표시되는지 확인하면 된다.
-
앞에서 인덱스 스캔을 하려면 조건절에 인덱스의 첫 번째 컬럼이 명시돼야 한다고 설명했다.
-
하지만 인덱스 컬럼에 NOT NULL 제약 조건이 설정돼 있다면
-
옵티마이저는 조건절에 인덱스 첫 번째 컬럼이 없더라도
-
최소 키 값과 최대 키 값으로 Key Range를 자동으로 추가하여 인덱스 스캔을 할 수 있게 최적화한다.
-
즉 인덱스 리프 노드의 처음부터 끝까지 스캔하는데
-
이를 오라클에서는 인덱스 전체 범위 스캔(Index Full Range Scan)이라고 한다.
SELECT * FROM tbl
WHERE b < 'K'
ORDER BY a;
-
위 SQL 질의는 옵티마이저에 의해 인덱스 전체 범위 스캔이 수행되는 예다.
-
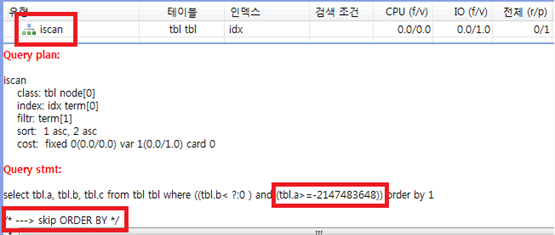
위 질의문의 실행 계획을 확인하면
-
다음 그림처럼 Key Range가 자동으로 추가되어 ORDER BY 정렬 연산이 생략되는 것을 알 수 있다.
LIMIT 최적화
-
LIMIT 절은 질의의 최종 결과 개수를 제한한다.
-
CUBRID 2008 R4.0에서는 Data Filter가 없는 질의에 LIMIT 절이 있으면
-
Key Range에 해당하는 키 값 전부를 스캔할 필요 없이
-
LIMIT 절에 기술된 개수 만큼의 결과를 확보했을 때 바로 스캔을 중단할 수 있다.
-
이렇게 하면 범위의 끝까지 스캔하고 나서 결국 버리게 되는 페이지를 액세스하지 않기 때문에 불필요한 I/O를 줄일 수 있다.
SELECT * FROM tbl
WHERE a = 2 AND b < 'K'
ORDER BY b
LIMIT 3;
-
이 SQL 질의는 LIMIT 최적화로 필요한 결과를 얻은 후 인덱스 스캔이 중단되는 예다.
-
만약 a = 2인 인덱스 키가 10페이지에 걸쳐 저장돼 있더라도
-
LIMIT 절에 명시한 3개의 키 값만 스캔하므로 1개의 페이지만 읽게 된다.
-
IN 절을 사용한 질의에도 LIMIT 최적화를 적용할 수 있다.
-
CUBRID는 인덱스 컬럼이 IN 절에 사용되면 Key Range를 IN 절에 사용된 개수만큼 생성하고
-
각 Key Range에 대해 인덱스 스캔을 수행한다.
-
다만 아래 질의처럼 LIMIT 절에 결과 개수가 명시되면
-
3번의 인덱스 스캔에 대해 각각 3건의 결과만 구하고 인덱스 스캔을 중단한다.
-
즉 각 인덱스 스캔에 대해서 LIMIT 최적화가 적용되는 것이다.
SELECT * FROM tbl
WHERE a IN (2, 4, 5)
AND b < 'K'
ORDER BY b
LIMIT 3;
-
ORDER BY 절은 전체 결과에 대한 정렬을 의미하기 때문에
-
Key Range가 여러 개이면 각 인덱스 스캔 결과를 모아서 다시 정렬해야 한다.
-
하지만 인덱스 스캔의 결과로 정렬을 대체할 수 있을 때에는 스캔 과정에서 바로 병합(merge)할 수 있다.
-
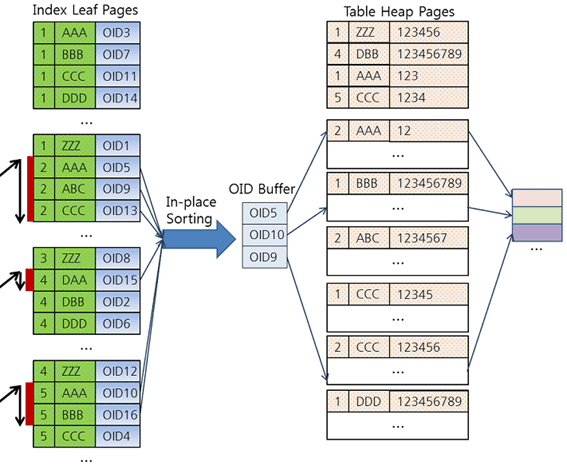
CUBRID는 이 과정을 In-Place Sorting이라고 부른다.
-
다음 그림을 보면서 자세히 설명하면
-
먼저 첫 번째 범위(a = 2 AND b < ‘K’)를 스캔하여 3건의 OID를 확보한다.
-
그 다음 두 번째 범위(a = 4 AND b < ‘K’)에 대한 스캔을 시도하는데
-
이 범위의 첫 번째 키(4, ‘DAA’)는 첫 번째 범위의 마지막 스캔 키(2, ‘CCC’)보다 b 컬럼의 값이 크기 때문에 바로 스캔을 중단한다.
-
마찬가지로 다음 세 번째 범위인 a = 5 AND b < ‘K’에 대한 스캔에서도
-
두 번째 키를 읽은 후 바로 스캔을 중단한다.
-
이처럼 In-Place Sorting 기법은 인덱스 스캔 범위를 더욱 축소하고
-
최종 결과에 대한 별도의 정렬을 수행하지 않기 때문에 성능 향상에 많은 도움을 준다.
은 총알은 없다(No Silver Bullet)
-
인덱스가 좋다고 인덱스를 많이 만드는 것은 능사가 아니다.
-
오히려 인덱스 관리 비용이 증가하고 INSERT, UPDATE, DELETE의 성능 저하의 원인이 될 수 있다.
-
인덱스 사용 시 다음 내용을 고려하자.
-
인덱스 키의 크기는 되도록 작게 설계해야 성능에 유리하다.
-
분포도가 좋은 컬럼(좁은 범위), 기본 키, 조인의 연결 고리가 되는 컬럼을 인덱스로 구성한다.
-
단일 인덱스 여러 개보다 다중 컬럼 인덱스의 생성을 고려한다.
-
업데이트가 빈번하지 않은 컬럼으로 인덱스를 구성한다.
-
JOIN 시 자주 사용하는 컬럼은 인덱스로 등록한다.
-
되도록 동등 비교(=)를 사용한다.
-
WHERE 절에서 자주 사용하는 컬럼에는 인덱스 추가를 고려한다.
-
인덱스를 많이 생성하는 것은 INSERT/UPDATE/DELETE의 성능 저하의 원인이 될 수 있다.
-
인덱스 스캔이 테이블 순차 스캔보다 항상 빠르지는 않다.
보통 선택도(selectivity)가 5~10% 이내인 경우에 인덱스 스캔이 우수하다.
-
정리하면 데이터베이스 튜닝의 핵심은
-
적절한 수의 인덱스를 생성하고 질의가 이 인덱스를 활용할 수 있도록 질의를 최적화하는 것이다.
-
이를 위해서는 DBMS에 구현된 인덱스 구조와 다양한 활용 기법을 이해하고
-
질의 패턴과 사용 빈도, I/O 비용, 저장 공간에 대한 비용을 전체적으로 고려해야 한다.