- 가비지 컬렉션(Garbage Collection) 1편에 이어 GC에 대해 알아보자.
GC
Generational GC
- GC는 두 가지 가정에 따라 만들어졌다.
1.대부분의 객체는 금방 접근 불가능 상태(unreachable)가 된다.
2.오래된 객체에서 젊은 객체로의 참조는 아주 적게 존재한다.
-
이러한 가설을 Weak generational hypothesis라 한다.
-
실제 통계로도 생성된 객체의 98%의 객체가 곧바로 쓰레기 객체가 된다고 한다.
-
이 가설의 장점을 최대한 살리기 위해서 HotSpot VM에서는 크게 2개로 물리적 공간(Young/Old)을 나누었다.
-
이러한 경험적 사실들을 바탕으로 Generational GC가 디자인되었다.
-
우선 2번째 가설에 대해 살펴보면
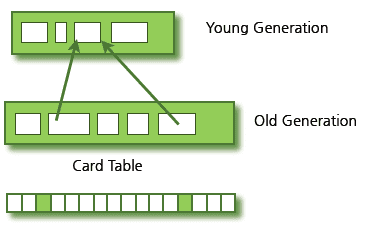
Old 영역에는 512 Byte의 덩어리(chunk)로 되어 있는 카드 테이블(Card Table)이 존재한다.
-
카드 테이블에는 Old 영역에 있는 객체가
Young 영역의 객체를 참조할 때마다 정보가 표시된다.
-
Young 영역의 GC를 실행할 때에는
Old 영역에 있는 모든 객체의 참조를 확인하지 않고 이 카드 테이블만 뒤져서 GC 대상인지 식별한다.
-
힙을 Young Generation 영역과 Old Generation 영역으로 나눈 뒤
Young Generation 영역을 주기적으로 청소하고
상대적으로 오랜 기간 사용되는 객체는 Old Generation으로 보내버린다.
그리고 Old 영역에 공간이 부족하게 될 때만 Old 영역을 청소하게 된다.
-
이렇게 함으로써 GC는 매번 힙 전체를 청소할 필요가 없어진다.
-
이러한 디자인에는 성능상 이점이 2가지가 있다.
-
첫째로 Young Generation은 Old Generation 보다 사이즈가 작고 힙 공간의 일부분이므로
GC가 전체 영역을 처리하는 것보다 시간이 덜 걸린다.
즉 stop-the-world로 애플리케이션이 중지되는 시간이 짧아진다.
-
비록 자주 GC가 작동하지만
stop-the-world로 길게 한 번 멈추는 것보다 짧게 여러 번 멈추는 것이 더 이익이라고 한다.
-
둘째로 Young Generation 영역을 한 번에 모두 비우므로
이 Young Generation 부분에 연속된 여유 공간이 만들어진다.
이 작업을 Compacting이라고 한다.
-
만약 GC가 군데군데 골라서 객체를 제거했다면
메모리 파편화(memory fragmentation)이 발생하여 연속된 큰 데이터가 들어갈 공간이 부족해지게 된다.
Young Generational GC
-
Minor GC 동작 방식은 가비지 컬렉션(Gabage Collection) 1편 - Minor GC를 참고하자.
-
여기서는 Eden 영역에 대해 더 알아본다.
-
참고로 HotSpot VM에서는 보다 빠른 메모리 할당을 위해서 두 가지 기술을 사용한다.
하나는 bump-the-pointer라는 기술이며
다른 하나는 TLABs(Thread-Local Allocation Buffers)라는 기술이다.
-
bump-the-pointer는 Eden 영역에 할당된 마지막 객체를 추적한다.
마지막 객체는 Eden 영역의 맨 위(top)에 있다.
그리고 그다음에 생성되는 객체가 있으면 해당 객체의 크기가 Eden 영역에 넣기 적당한지만 확인한다.
-
만약 해당 객체의 크기가 적당하다고 판단되면
Eden 영역에 넣게 되고 새로 생성된 객체가 맨 위에 있게 된다.
따라서 새로운 객체 생성 시 마지막에 추가된 객체만 점검하면 되므로 매우 빠르게 메모리 할당이 이루어진다.
-
그러나 Multi Thread 환경을 고려하면 이야기가 달라진다.
Thread-Safe 하기 위해서
만약 여러 Thread에서 사용하는 객체를 Eden 영역에 저장하려면
락(lock)이 발생할 수밖에 없고 Lock Contention 때문에 성능은 매우 떨어지게 된다.
-
HotSpot VM에서 이를 해결한 기술이 TLABs이다.
-
각각의 Thread가 각각의 몫에 해당하는 Eden 영역의 작은 덩어리를 가질 수 있도록 한다.
각 Thread에는 자기가 가진 TLAB에만 접근할 수 있으므로
bump-the-pointer 기술을 사용하더라도 아무런 Lock 없이 메모리 할당이 가능해진다.
Old Generational GC
-
Old 영역에서의 GC는 방식에 따라 처리 절차가 달라진다.
-
Old 영역에서는 기본적으로 데이터가 가득 차면 GC를 실행한다.
-
GC 방식은 JDK 7을 기준으로 알아본다.
-
Serial GC
-
Parallel GC
-
Concurrent Mark & Sweep GC(이하 CMS)
-
G1(Garbage First) GC
-
이 중에서 운영 서버에서 절대 사용하면 안 되는 방식이 Serial GC다.
-
Serial GC는 데스크톱의 CPU 코어가 하나만 있을 때 사용하기 위해서 만든 방식이다.
-
Serial GC를 사용하면 애플리케이션의 성능이 많이 떨어진다.
Serial GC (-XX:+UseSerialGC)
-
Serial GC는 Mark-Sweep-Compact 알고리즘을 사용한다.
-
이 알고리즘의 첫 단계는 Old 영역에 살아 있는 객체를 식별(Mark)하는 것이다.
-
그다음에는 힙(heap)의 앞부분부터 확인하여 살아 있는 것만 남긴다(Sweep).
-
마지막 단계에서는 각 객체가 연속되게 쌓이도록 힙의 가장 앞부분부터 채워서
객체가 존재하는 부분과 객체가 없는 부분으로 나눈다(Compaction).
-
Serial GC는 적은 메모리와 CPU 코어 개수가 적을 때 적합한 방식이다.
Parallel GC (-XX:+UseParallelGC)
-
Parallel GC는 Serial GC 와 기본적인 알고리즘은 같다.
-
Minor GC, Full GC 모두 All Stop인건 Serial GC 와 같다.
-
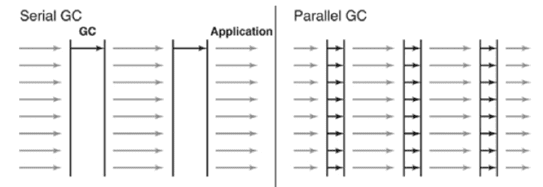
그러나 Serial GC는 GC를 처리하는 Thread가 하나인 것에 비해
Parallel GC는 GC를 처리하는 Thread가 여러 개이다.
여러 Thread가 작동하기 때문에 이름이 Parallel이다.
-
즉 Minor GC와 Full GC에서 모두 Multi Thread를 사용한다.
그러므로 Serial GC 보다 빠르게 객체를 처리할 수 있다.
-
Parallel GC는 메모리가 충분하고 코어의 개수가 많을 때 유리하다.
-
Parallel GC는 Throughput GC라고도 부른다.
-
다음 그림은 Serial GC와 Parallel GC의 Thread를 비교한 그림이다.
CMS(Concurrent Mark & Sweep) GC (-XX:+UseConcMarkSweepGC)
-
어떻게 하면 Full GC의 stop-the-world 상태를 줄일 수 있을까? 라는 고민에서 출발한 GC이다.
-
Parallel Collector 와 같이 Multi Thread로 Minor GC를 한다.
그리고 이 순간에는 stop-the-world가 발동한다.
-
하지만 Full GC는 거의 stop-the-world가 발생하지 않는다.
-
어플리케이션이 작동하는 중에 Background에서 Thread를 만들어서
Old Generation 영역에 참조되지 있지 않은 객체들을 지속해서 제거한다.
-
즉 CMS의 장점은 stop-the-world가 거의 발생하지 않는다는 점이다.
정리하자면 Background에서 항상 일하므로
Minor GC에서 잠깐씩 그리고 Full GC에서는 거의 발생하지 않는다.
-
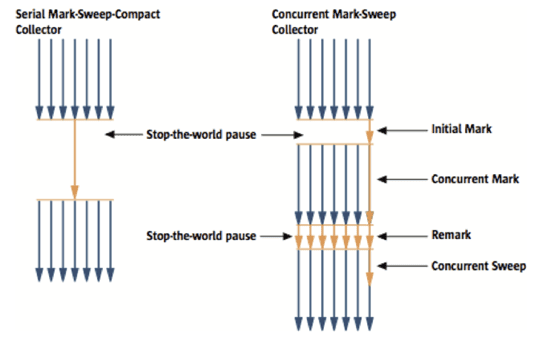
다음 그림은 Serial GC와 CMS GC의 절차를 비교한 그림이다.
그림에서 보듯이 CMS GC는 지금까지 설명한 GC 방식보다 더 복잡하다.
-
초기 Initial Mark 단계에서
클래스 로더에서 가장 가까운 객체 중 살아 있는 객체만 찾는 것으로 끝낸다.
따라서 멈추는 시간은 매우 짧다.
-
그리고 Concurrent Mark 단계에서는
방금 살아있다고 확인한 객체에서 참조하고 있는 객체들을 따라가면서 확인한다.
-
이 단계의 특징은 다른 Thread가 실행 중인 상태에서 동시에 진행된다는 것이다.
-
그 다음 Remark 단계에서는 Concurrent Mark 단계 에서 새로 추가되거나 참조가 끊긴 객체를 확인한다.
-
마지막으로 Concurrent Sweep 단계에서는 쓰레기를 정리하는 작업을 실행한다.
-
이 작업도 다른 Thread가 실행되고 있는 상황에서 진행한다.
즉 동시에 진행이 된다.
-
이러한 단계로 진행되는 GC 방식이므로 stop-the-world 시간이 매우 짧다.
-
모든 애플리케이션의 응답 속도가 매우 중요할 때
CMS GC를 사용하며 Low Latency GC라고도 부른다.
-
그런데 CMS GC는 stop-the-world 시간이 짧다는 장점에 반해 다음과 같은 단점이 존재한다.
-
일단 Background에서 항상 GC Thread가 돌아야 하므로
다른 GC 방식보다 메모리와 CPU를 더 많이 사용한다.
-
Compaction(압축) 단계가 기본적으로 제공되지 않는다.
-
중간마다 Old Generation에 있는 객체들을 해제하면서 메모리가 불규칙적으로 비워지게 된다.
즉 메모리 파편화가 발생한다.
-
만약 CPU 리소스가 부족해진다거나
메모리 파편화가 너무 심해서 메모리 공간이 부족해지면
Serial GC가 하던 방식(Single Thread로 청소)을 똑같이 따라 하게 된다.
-
따라서 CMS GC를 사용할 때에는 신중히 검토한 후에 사용해야 한다.
G1(Garbage First) GC (-XX:+UseG1GC)
-
G1 GC를 이해하려면 지금까지의 Young 영역과 Old 영역에 대해서는 잊는 것이 좋다.
-
다음 그림처럼 G1 GC는 바둑판의 각 영역에 객체를 할당하고 GC를 실행한다.
-
그러다 해당 영역이 꽉 차면 다른 영역에서 객체를 할당하고 GC를 실행한다.
-
즉 지금까지 설명한 Young의 세 가지 영역에서
객체가 Old 영역으로 이동하는 단계가 사라진 GC 방식이라고 이해하면 된다.
-
G1 GC는 장기적으로 말도 많고 탈도 많은 CMS GC를 대체하기 위해서 만들어졌다.

-
G1 GC의 가장 큰 장점은 성능이다.
-
지금까지 설명한 어떤 GC 방식보다도 빠르다.
-
JDK 7에서 정식으로 G1 GC를 포함하여 제공한다.
-
더 자세한 내용은 [Java Optimizing] 7. 가비지 수집 고급 : G1 GC글을 참고하자.
+
-
힙 영역이 매우 큰 머신(최소 4GB)에서 돌리기에 적합한 GC이다.
-
CMS의 단점을 어느 정도 극복했다.
-
힙에 영역(Region)이라는 개념을 도입하였다.
-
힙을 여러 개의 Region으로 나눈다.
일부 Region은 Young Generation 영역으로
나머지 일부 Region은 Old Generation 영역으로 사용한다.
-
Young Generation 영역을 정리하는 건 Parallel이나 CMS처럼 Multi Thread로 정리를 한다.
그리고 Old Generation 영역에 해당하는 여러 개의 Region에 대해선
CMS처럼 Background Thread로 이 영역들을 정리한다.
-
그런데 CMS와 차이점은 중간중간 쓸모없는 객체들을 정리하는 게 아닌 한 Region을 통째로 정리해버린다.
-
참조가 없는 객체들은 지우고 사용 중인 객체는 다른 Region으로 고스란히 복사한다.
포인터 추적 기법 중 객체 이동 기법을 참고하자.
-
다른 Region으로 복사하는 과정에서
Compacting(압축)이 되므로 메모리 파편화 현상이 생기지 않게 된다.
-
CMS의 문제점이었던 메모리 파편화 문제를 해결하게 된다.
CMS 문제점
-
많은 CPU 리소스 사용
-
메모리 파편화 발생