이 글의 코드 및 정보들은 책을 바탕으로 작성하였습니다.
카프카 데이터 모델
-
카프카가 고성능, 고가용성 메시징 Application으로 발전할 수 있던 배경에는
토픽과 파티션이라는 데이터 모델의 역할이 컸다.
토픽
- 메시지를 받을 수 있는 논리적인 단위
파티션
-
토픽을 구성하는 데이터 저장소
-
수평 확장이 가능한 단위
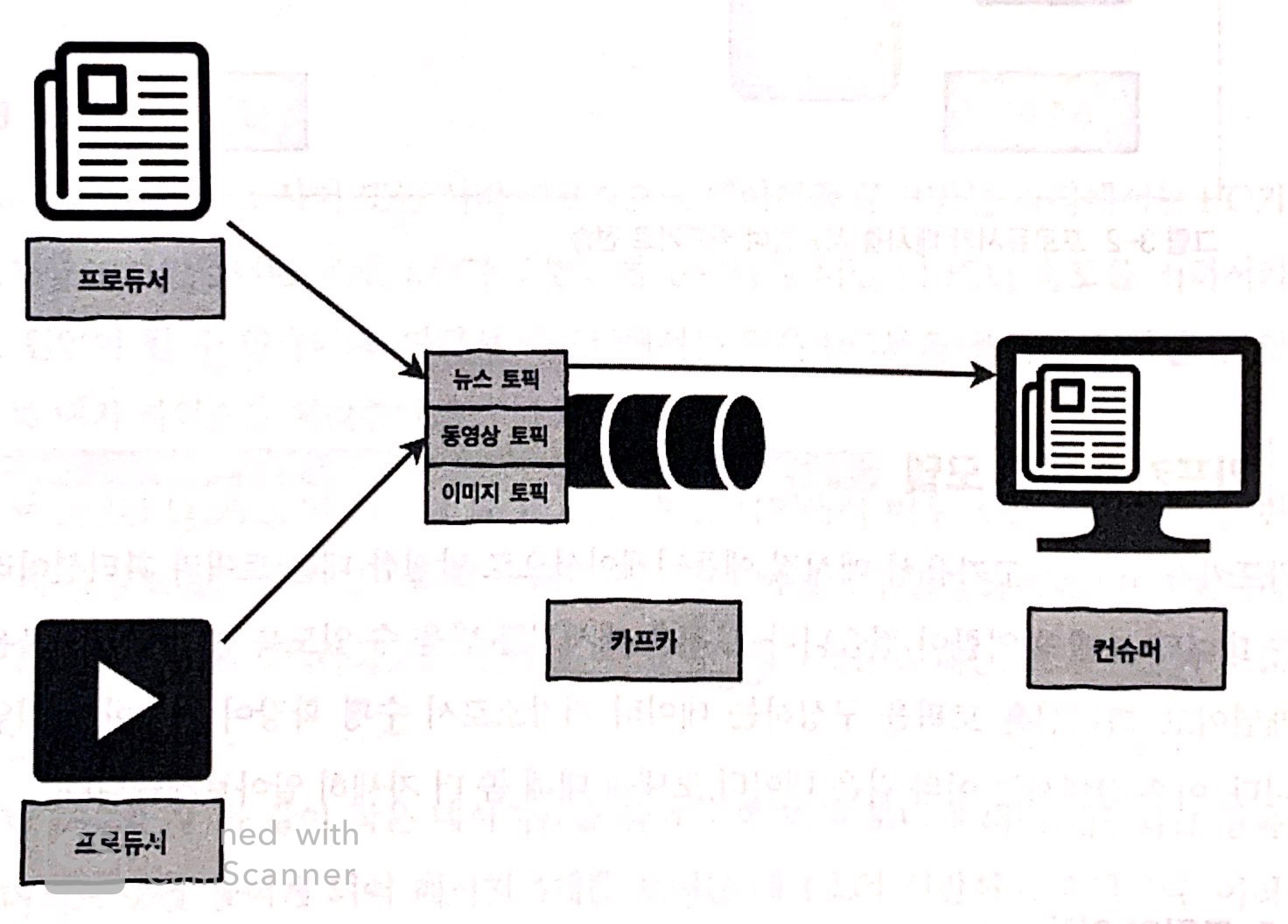
토픽의 이해
-
카프카 클러스트는 토픽이라 불리는 곳에 데이터를 저장한다.
ex) 메일 주소 = 토픽
-
토픽 이름은 249자 미만의 영문 / 숫자 / . / _ / - 를 조합하여 생성이 가능하다.
-
토픽 이름이 중복되지 않도록
카프카를 사용하는 유저들간에 사전에 정의한다.
파티션의 이해
- 카프카에서 파티션이란 토픽을 분할한 것이다.
Why divide ?
- 각 메시지를 보내는데 1초의 시간이 걸린다고 가정한다.
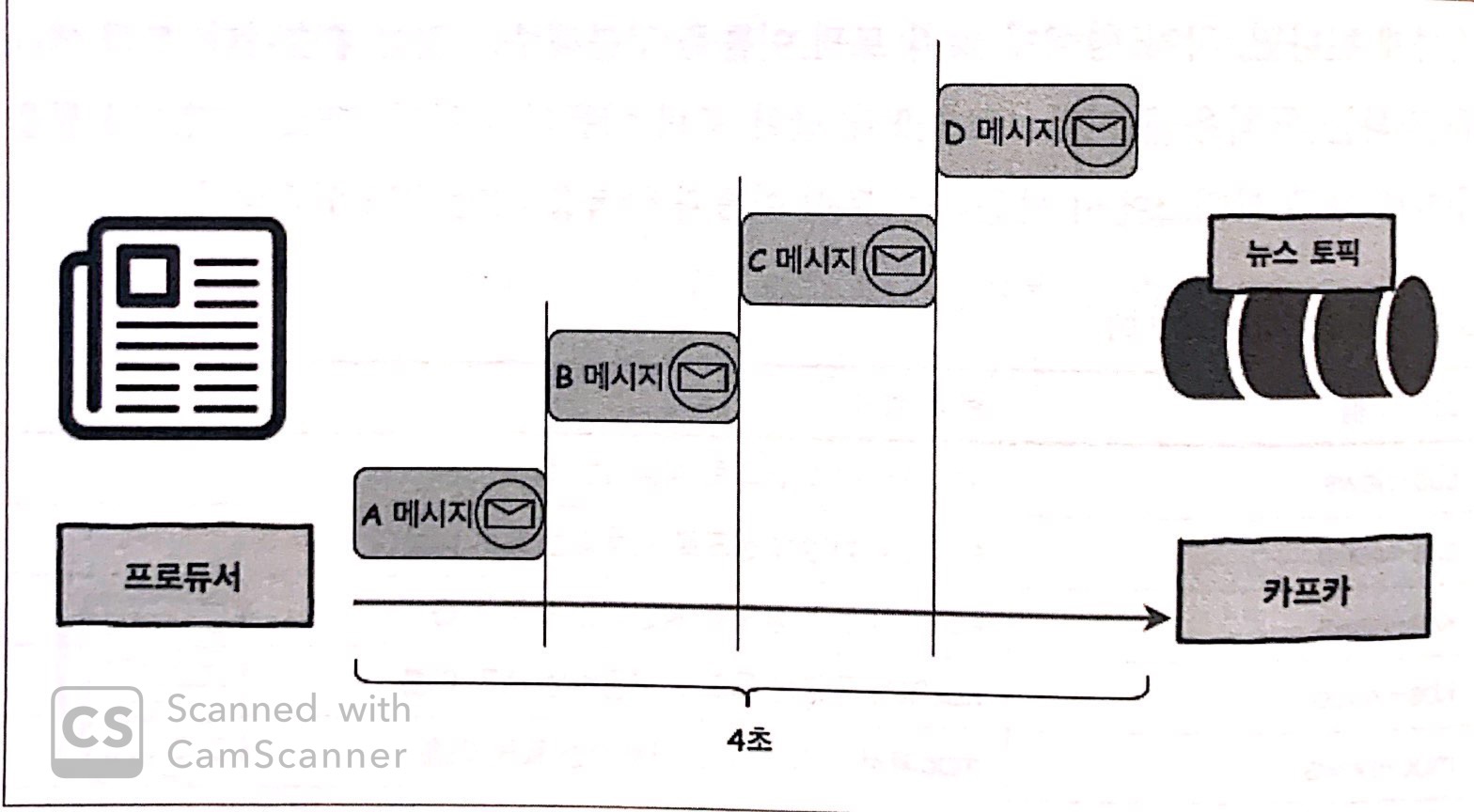
Case1. 프로듀서 1 : 파티션 1
-
하나의 프로듀서가 카프카의 토픽으로 4개의 메시지를 전송하는 상황이다.
프로듀서는 A 메시지 전송이 완료된 후 B 메세지를 전송한다.
그러므로 총 4초의 시간이 걸린다.
Case2. 프로듀서 4 : 파티션 1
-
프로듀서만 4개로 변경한다면 어떻게 될까?
일반적인 분산 시스템의 경우라면
4배의 성능을 보장할 수 있다.
-
하지만 메시징 큐 시스템의 경우
메시지의 순서가 보장되어야한다는 제약 조건이 있다.
-
그렇기 때문에 이전 메시지 처리가 완료된 후 다음 메시지를 처리해야한다.
그래야 메시지의 순서가 보장되기 때문이다.
-
다시 말해 카프카에서 효율인 메시지 전송과 속도를 높히기 위해선
토픽의 파티션 수를 늘려줘야한다.
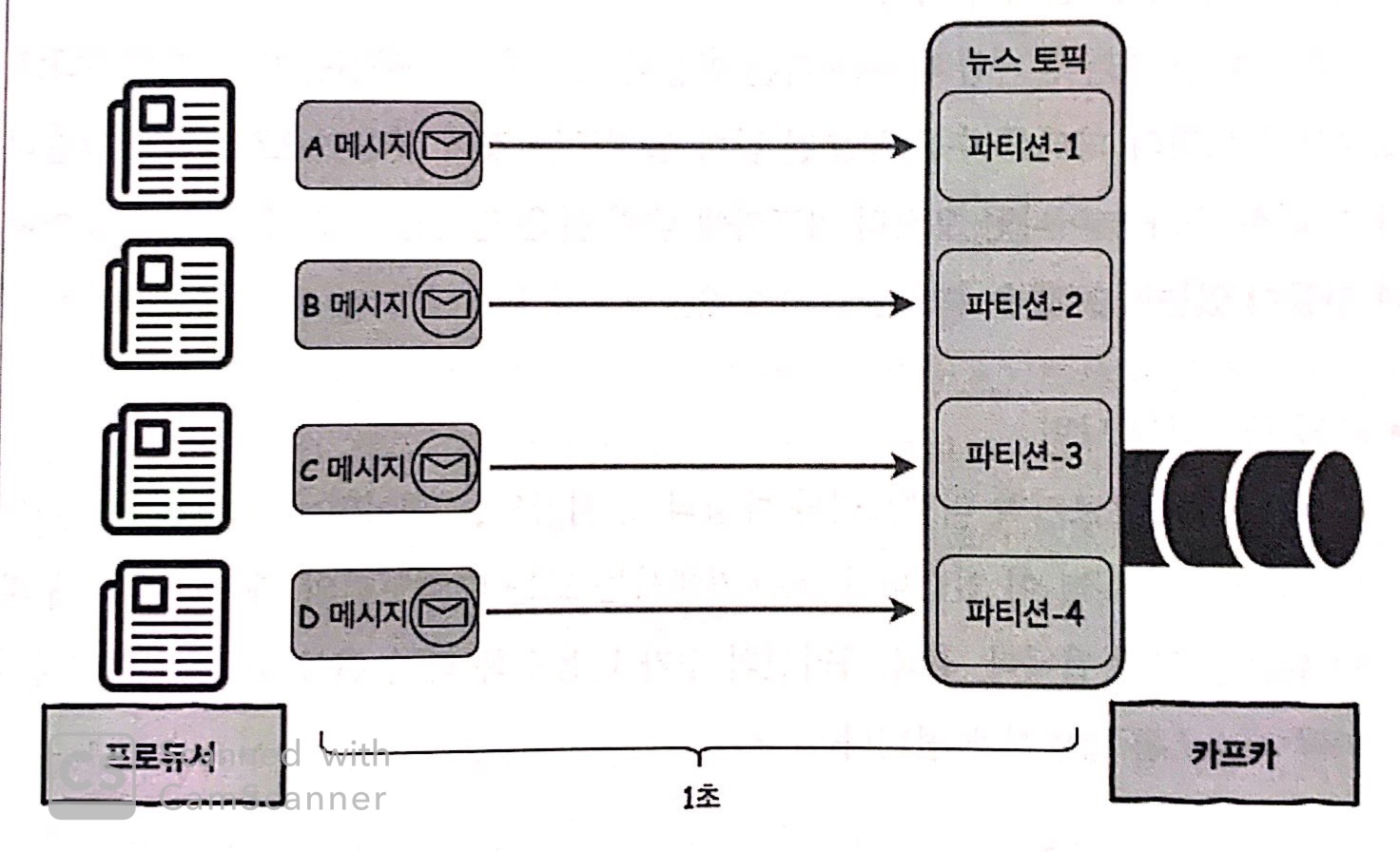
Case3. 프로듀서 4 : 파티션 4
-
토픽의 파티션 수를 1 -> 4개로 늘려보자.
-
파티션 수에 맞춰 프로듀서의 수도 1 -> 4개로 늘린다.
-
각 프로듀서는 하나의 메시지를
토픽의 파티션으로 전송한다.
-
이처럼 병렬 처리 방식으로
동시에 4개의 토픽을 전송할 수 있고
총 1초의 시간이 소요된다.
-
즉 빠른 전송을 위해서
토픽의 파티션을 늘려야하며
파티션의 수만큼
프로듀서 수도 늘려야 제대로 효과를 볼 수 있다.
- 그렇다면 2가지 질문을 던질 수 있다.
-
무조건 파티션 수를 늘리는게 답일까?
-
내 토픽의 적절한 파티션 수는 어떻게 알 수 있을까?
- 2가지 질문에 대해서는 Kafka 파티션 설정시 고려할 점글을 참고하자.
오프셋과 메시지 순서
-
카프카에서는 각 파티션마다 메시지가 저장되는 위치를
오프셋(Offset)이라 한다.
-
오프셋은 파티션 내에서
유일하고 순차적으로 증가하는 64비트 정수 형태로 되어있다.
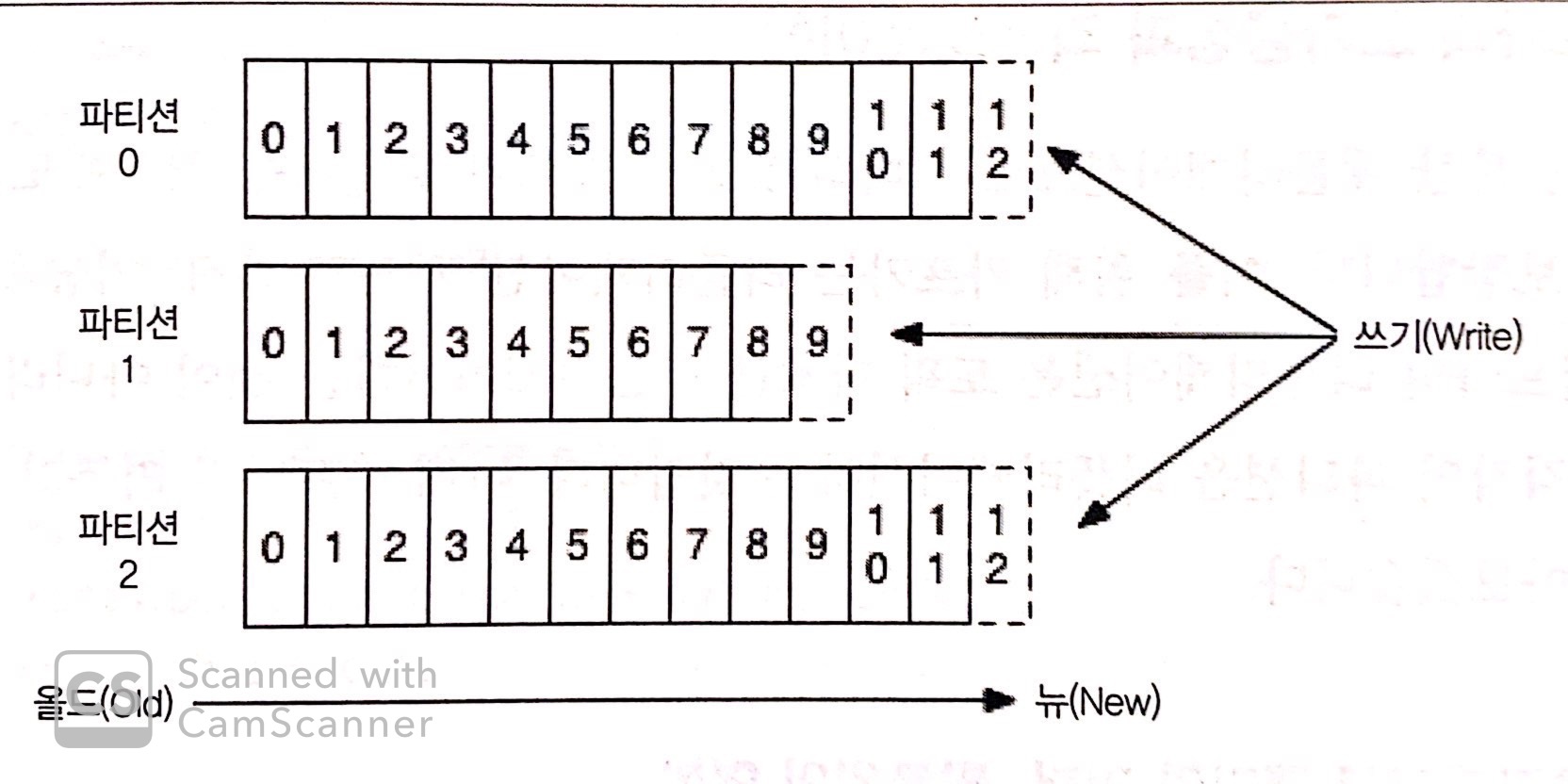
- 위 그림은 하나의 토픽을 총 3개의 파티션으로 나눈 그림이다.
-
그림에서 쓰기(Write)의 의미는
프로듀서가 메시지를 보내면
메시지가 각 파티션 별로 분산되어
데이터가 저장되는 상태를 의미한다.
-
각 파티션에는
프로듀서가 전송한 메시지들이 저장되어 있다.
-
저장된 위치를 유니크하고
순차적인 숫자 형태인 0, 1, 2 형태로 나타낸다.
-
이러한 숫자는 파티션마다 유니크한 값을 가지며
(= 오프셋 값이 1이라는 값이더라도 각 파티션마다 독립적인 값이다.)
카프카에서 이를 오프셋이라 한다.
-
토픽 기준으로 오프셋이 0인 것을 보면
총 3개가 존재한다.
-
하지만 0번 파티션 기준으로 보면
오프셋 0은 유일한 값이다.
-
카프카에서는 이 오프셋을 이용해
메시지의 순서를 보장한다.
-
만약 컨슈머가 파티션 0에서 데이터를 가져가면
오프셋 0,1,2,3,4,5 순서대로만 가져갈 수 있다.
절대로 오프셋 순서가 바뀐 상태로 가져갈 수 없다.