- 카프카의 리플리케이션
- 리플리케이션 팩터
- 카프카의 높은 가용성
- 리플리케이션 동작 방식
- 리더와 팔로워
- 리더와 팔로워 위치
- 리플리케이션 상황에서의 장애
- 리플리케이션 단점
- Reference
이 글의 코드 및 정보들은 책을 바탕으로 작성하였습니다.
카프카의 리플리케이션
-
카프카는 분산 Application으로
-
서버의 물리적 장애가 발생하는 경우에도
-
높은 가용성을 보장한다.
-
이를 위해 카프카는
-
Replication(복제) 기능을 제공한다.
-
카프카의 리플리케이션은
-
토픽 자체를 복제하는 것이 아니라
-
토픽을 이루는 각각의 파티션을 리플리케이션한다.
리플리케이션 팩터
-
카프카에는 Replication Factor라는 개념이 있다.
-
기본값은 1로 설정되어 있다.
-
변경방법은 카프카 설정 파일에서 수정이 가능하다.
vim /usr/local/kafka/config/server.properties
->
default.replication.factor 값 수정
ex) default.replication.factor = 2
-
default.replication.factor값은
-
아무런 옵션을 주지 않고
-
토픽을 생성할 때 적용되는 값이다.
-
추가적으로
-
각 토픽별로 리플리케이션 팩터 값 설정 가능하며
-
운영 중에도 토픽의 리플리케이션 팩터 값 변경 가능하다.
-
만약 설정 파일에서 해당 항목이 없다면
-
기본값이 적용되어 있는 것이다.
카프카의 높은 가용성
-
카프카가 리플리케이션 기능을 통해
-
어떻게 높은 가용성을 얻을 수 있을까?
카프카의 리플리케이션은
토픽 자체를 복제하는 것이 아니라
토픽을 이루는 각각의 파티션을 리플리케이션한다.
-
라고 위에서 말했다.
-
하지만 이해를 위해서
-
파티션이 아닌 토픽으로 리플리케이션을 시키며
-
이해를 해보자.
Example
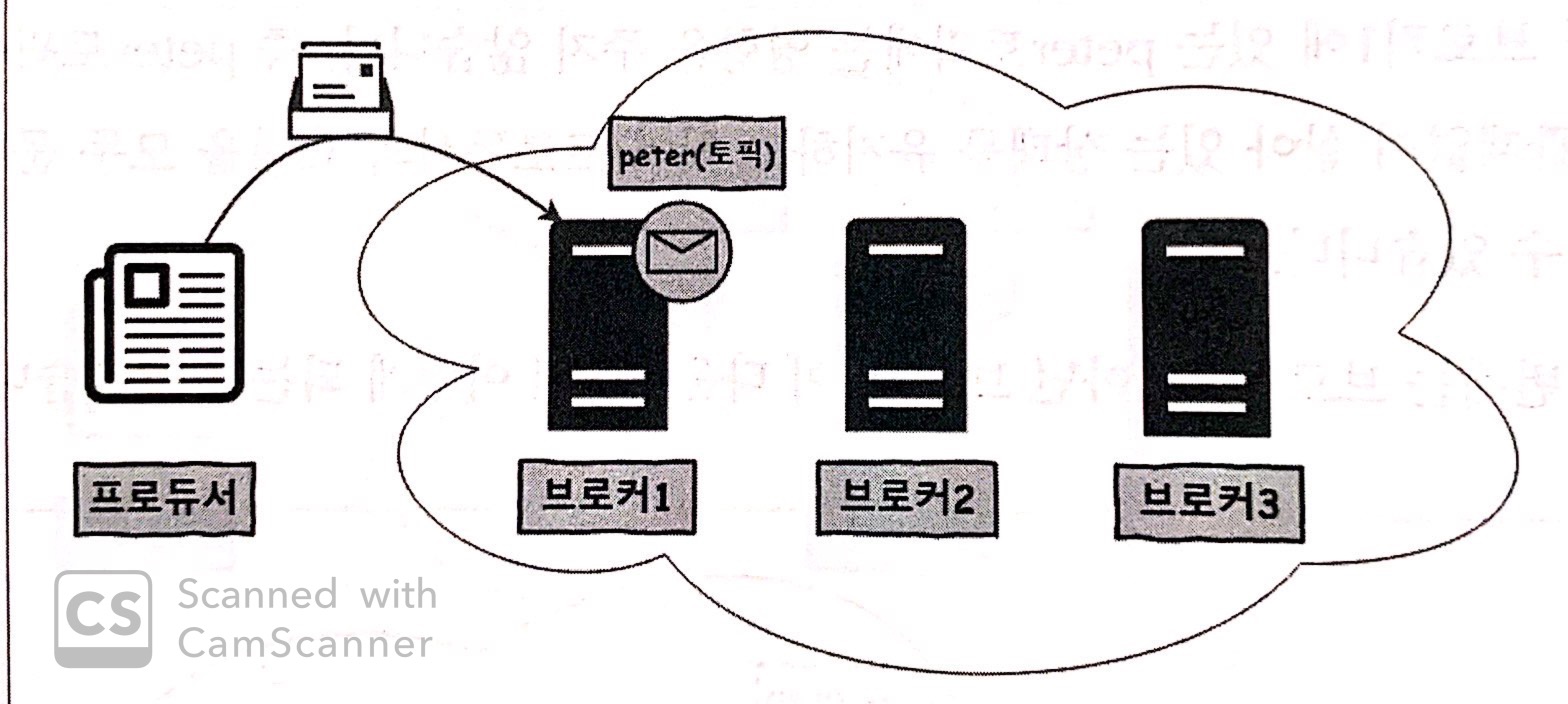
-
카프카 클러스터를 3대의 브로커로 구성하고
-
프로듀서가 peter라는 토픽으로 메시지를 보내는 상황이다.
-
peter 토픽은 리플리케이션이 구성되지 않아
-
브로커1에만 위치하고 있다.
Case 1. If Broker 3 goes down
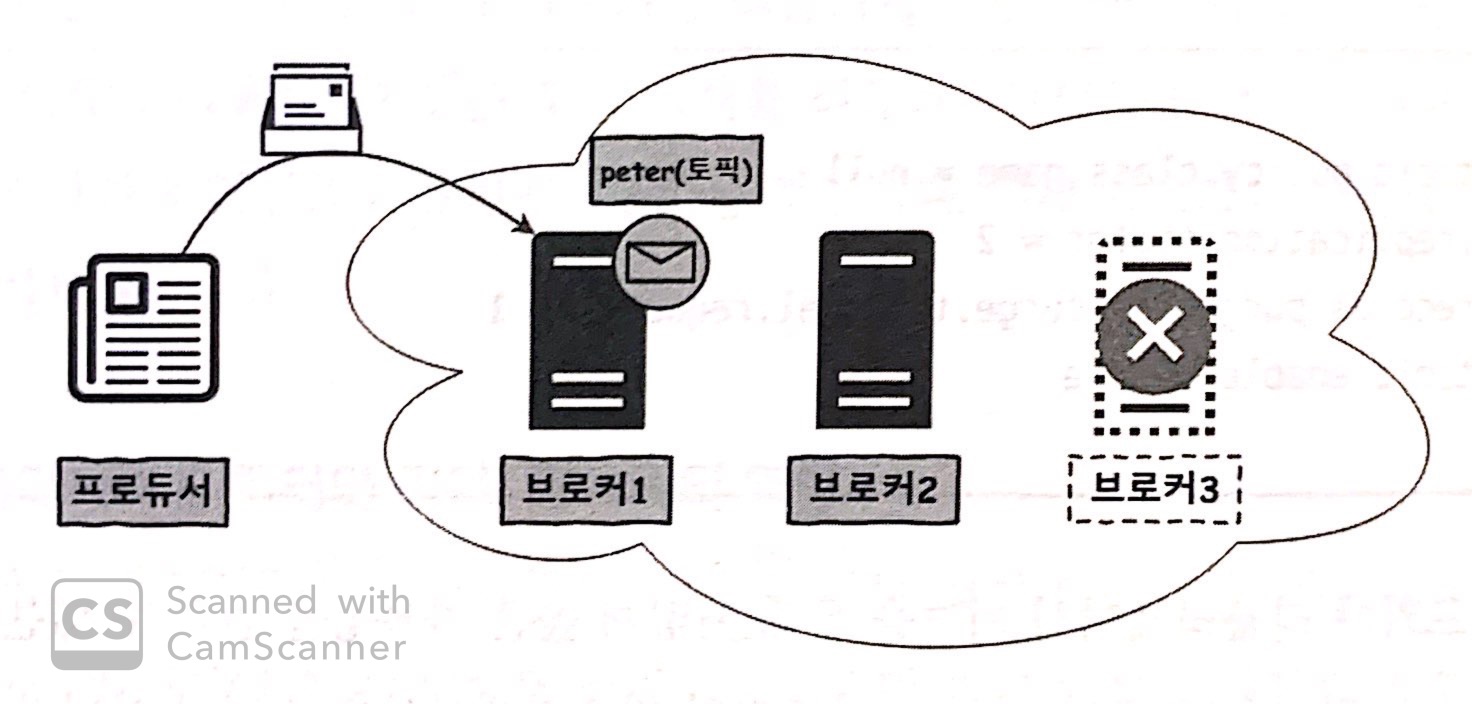
-
프로듀서가 보내는 토픽은
-
브로커 1에서만 처리하기 때문에
-
브로커 1과 3은 동일한 카프카 클러스터이지만
-
서비스에는 영향이 없다.
Case 2. If Broker 1 goes down
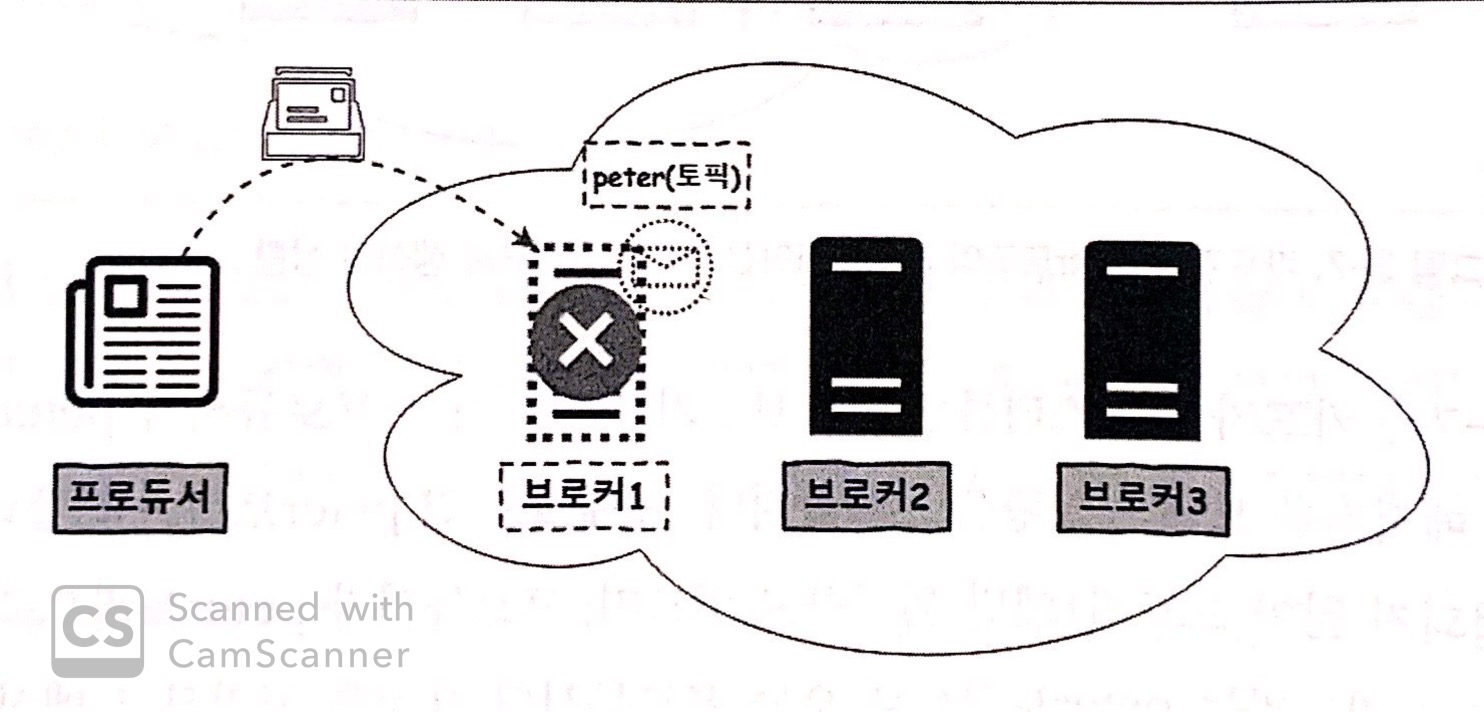
-
브로커 1이 다운되었기 때문에
-
peter 토픽도 다운된다.
-
그렇기 때문에
-
프로듀서가 보내는 메시지를 처리할 수 없게 된다.
So what?
-
Case 2와 같은 경우를 대비해
-
카프카는 리플리케이션 기능을 제공하여
-
치명적인 장애가 발생하지 않도록 방지할 수 있다.
리플리케이션 동작 방식
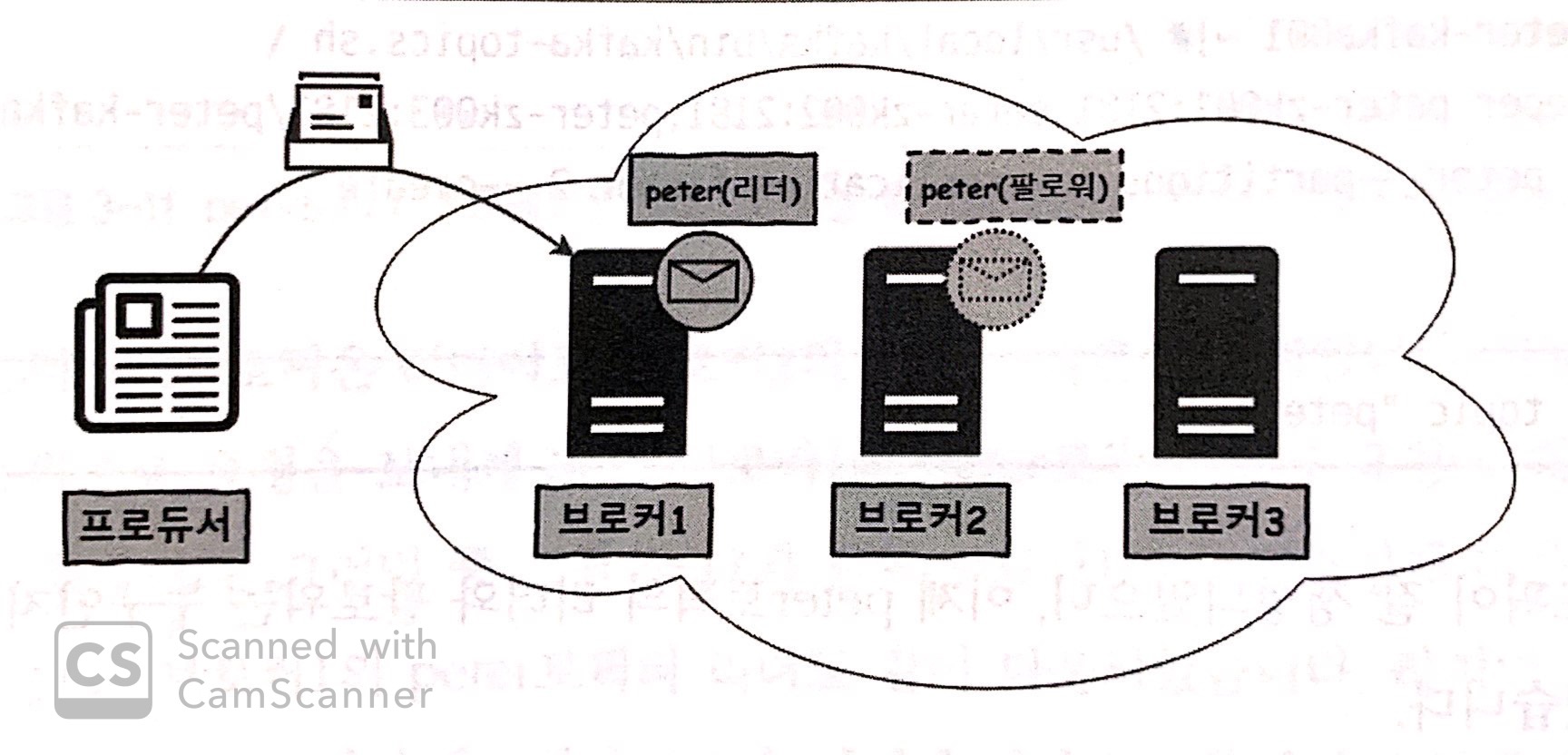
-
peter 토픽에 대해 리플리케이션을 구성했다.
-
이제 토픽은 브로커 1과 2에 존재한다.
-
여기서 원본과 복제본을 구분하기 위해
-
원본을 갖고 있는 브로커는 리더(Leader)
-
복제본을 갖고 있는 브로커는 팔로워(Follower)라 부른다.
리더와 팔로워
-
리더와 팔로워의 가장 중요한 핵심은
-
모든 Read/Write는 리더를 통해서만 일어난다.
-
즉 팔로워는 리더의 데이터 및 정보를 그대로 복제만 한다.
-
그렇기 때문에
-
리더와 팔로워는 저장된 데이터의 순서도 일치하고
-
동일한 오프셋과 메시지들을 갖게 된다.
리더와 팔로워 위치
-
생성된 토픽의 리더와 팔로워가 어느 브로커에 위치하는지
-
알아보기 위해
-
peter라는 토픽을
-
파티션 : 1
-
리플리케이션 팩터 : 2
-
옵션으로 카프카에 직접 토픽을 생성한다.
/usr/local/kafka/bin/kafka-topics.sh \
--zookeeper peter-zk001:2181, peter-zk002:2181, peter-zk003:2181/peter-kafka \
--topic peter --partitions 1 --replication-facotr 2 --create
-
생성이 되었다면
-
리더와 팔로워가 누군지 확인해보자.
/usr/local/kafka/bin/kafka-topics.sh \
--zookeeper peter-zk001:2181, peter-zk002:2181, peter-zk003:2181/peter-kafka \
--topic peter --describe
- 다음과 같이 출력이 된다.
Topic : peter PartititonCount : 1 ReplicationFacotr : 2 Configs :
Topic : pter
Partition : 0
Leader : 1
Replicas : 1,2
Isr : 1,2
-
Leader : 1은 peter 토픽의 0번 파티션 리더가
-
1번 브로커에 있다는 의미이다.
-
그 옆에 Replicas : 1,2는
-
peter 토픽이 리플리케이션 되고 있으며
-
브로커 1과 2에 위치하고 있다는 의미이다.
-
출력문에 Leader가 1이라는 값이 있기 떄문에
-
팔로워는 2번이라는 것을 알 수 있다.
리플리케이션 상황에서의 장애
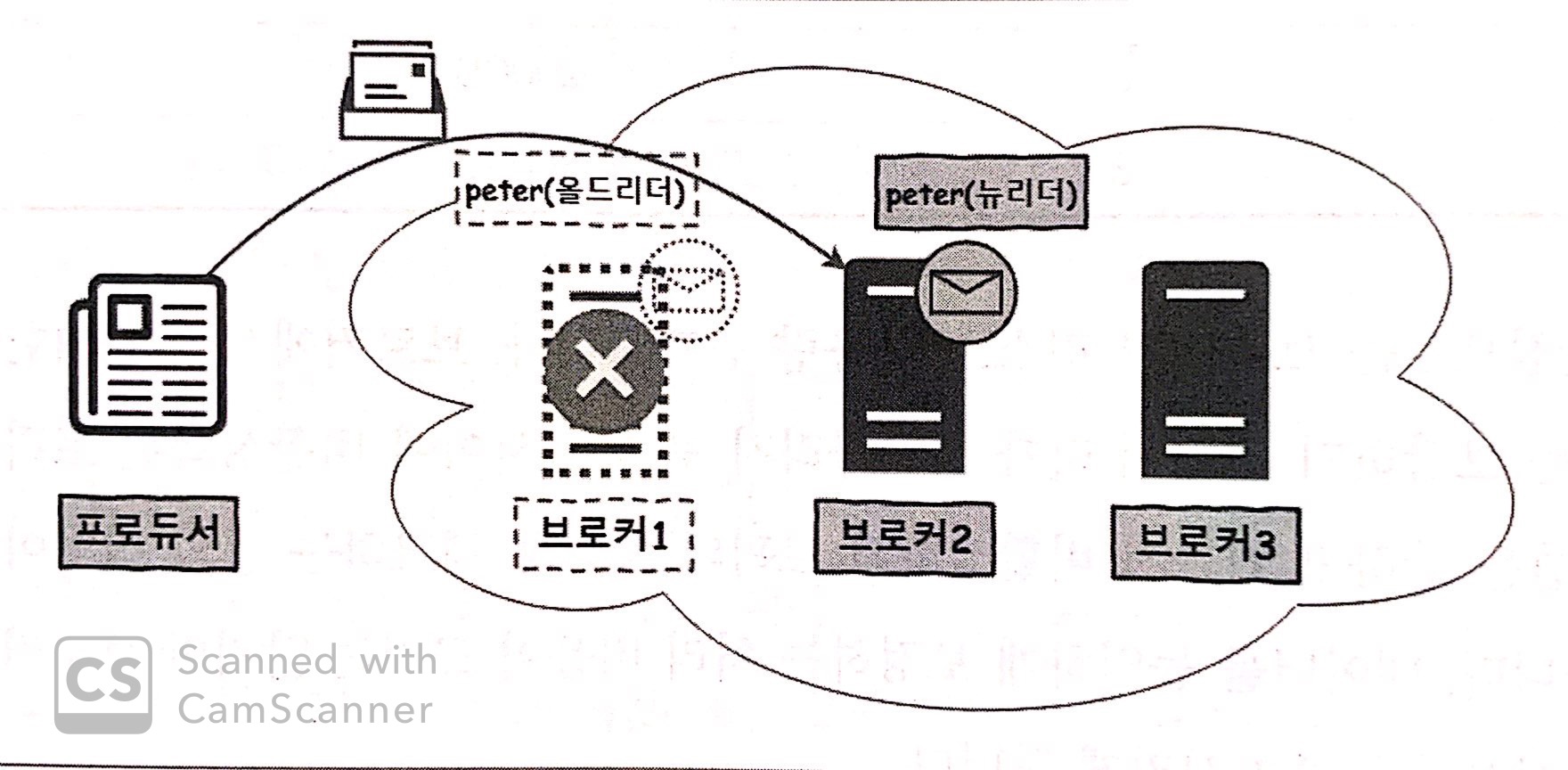
-
브로커 1의 peter 토픽은 리더이고
-
브로커 2의 peter 토픽은 팔로워이다.
-
만약 브로커 1이 다운된다면
-
브로커 1의 peter 토픽의 리더도 같이 다운된다.
-
하지만 브로커 2에 남아있는
-
peter 토픽의 팔로워가
-
새로운 리더가 되어
-
프로듀서 요청에 응답하게 된다.
-
프로듀서 입장에서는
-
어느 브로커가 다운되었는지는 중요치 않다.
-
단지 메시지를 끊김없이 보낼 수 있기만 하면 된다.
-
즉 리플리케이션 기능을 이용해
-
리플리케이션된 토픽의 서버가 다운되는 상황이 발생하더라도
-
리더 변경으로 프로듀서의 요청들을 처리할 수 있게 된다.
리플리케이션 단점
저장소
-
팔로워는 리더의 데이터 및 추가적인 정보를 복제한다.
-
그렇기 때문에 팔로워는
-
리더와 동일한 저장소가 필요하다.
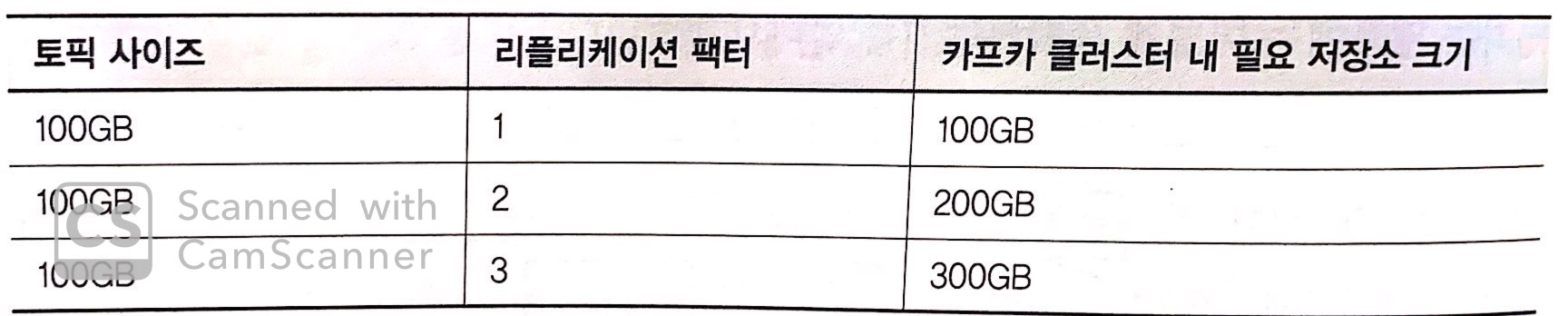
리소스 사용량
-
브로커에서는 완벽한 리플리케이션을 보장하기 위해
-
비활성화된 토픽이 리플리케이션을 잘하고 있는지
-
비활성화된 토픽의 상태를 체크하는 등의 작업이 이뤄진다.
-
이로인해 브로커의 일부 리소스 사용량을 증가시킨다.
Summary
-
따라서 모든 토픽에 리플리케이션 팩터를 크게 잡아 운영하기 보다는
-
토픽에 저장되는 데이터의 중요도에 따라
-
리플리케이션 팩터를 2 또는 3으로 설정해 운영하는 것이 효율적이다.