Solution for overfitting

-
학습 데이터를 늘리자.
-
features를 줄이면 되는데 굳이 할 필욘 없다.
-
Regularization: Let’s not have too big numbers in the weight
Q. “Let’s not have too big numbers in the weight”가 무슨 말이지 ?
Weight값으로 너무 큰 값을 주지말자는 뜻이다.
학습 데이터가 너무 넓은 범위에 분포되어 있으면
W값이 모든 경우를 처리하기 위해서
값이 커질수가 있다. 그런 경우를 방지하기 위해
W값은 줄이되 모든 경우를 포함할 수 있도록
Regularization하자는 것이다.
( 약간 soft_max처럼 [ 0 ~ 1 ]사이로 줄이는 느낌이랄까 ? )
( 지극히 주관적인 생각이라 틀린 답변일수있다.)

- 각각 W(Element)를 제곱한 값을 더한게 최소화가 되게 하자.
Dropout
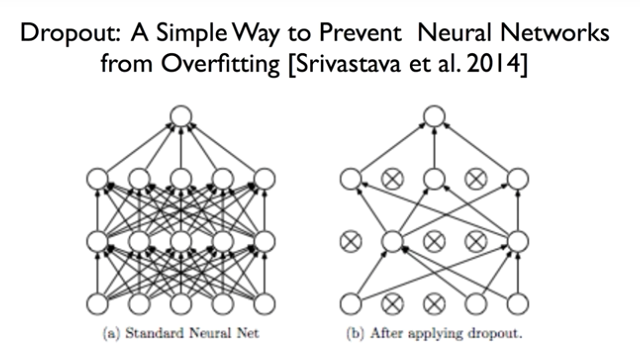
Neural Networks에는
Solution for overfitting에 대한 해결책이
1가지 더 있다.
바로 Dropout이다.
Random하게 어떤 neurons을 squeeze하자.

그런데 Random하게 설정을 해도 될까? …
가.능.하.다.
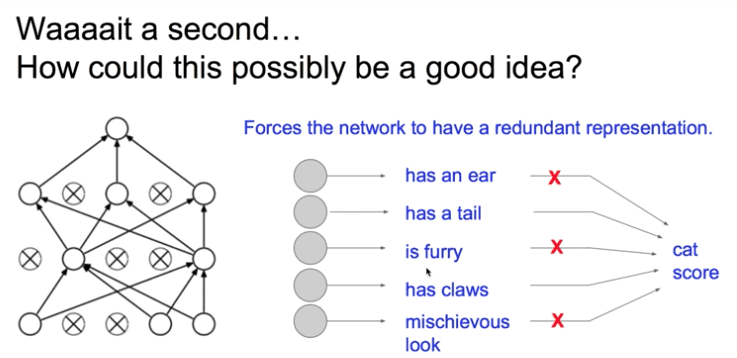
각각의 neurons들은
각각의 정보를 갖고 있다.
그래서
일부는 쉬게하고
남은 것들로 훈련을 시킨다.
그리고
마지막에 쉬게한 것들을 총 동원해서
예측을 한다.
Dropout Implementation code

주의할 점은
학습 할 때만 dropout을 한다.
실전에서는 dropout을 하지 않는다.
# Train:
sess.run(optimizer, feed_dict={X: batch_xs, Y: batch_ys, dropout_rate: 0.7})
# Evaluation:
print('Accuracy:', sess.run(accuracy, feed_dict={
X: mnist.test.images, Y: mnist.test.labels, keep_prob: 1}))
What is Ensemble ?
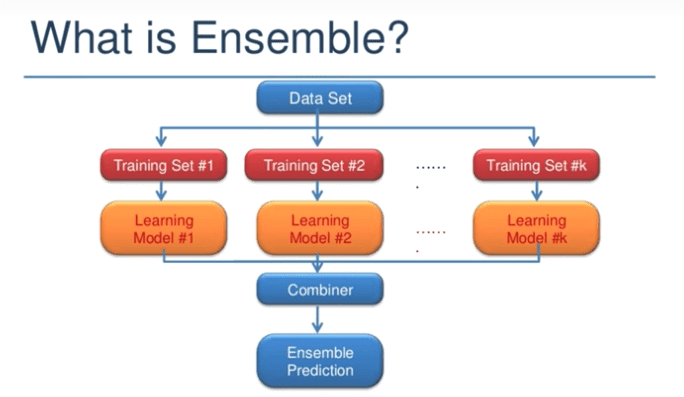
Ensemble 앙상블이라 읽는다.
100개의 Data가 있을 때
1명한테 100번 학습을 시키는게 아니라
10명한테 10번 씩 학습을 시키는 것이다.
독립적으로 모델을 학습시키고
나중에 합치는 것이다.
실제로 정확도도 더 높게 나온다.