NoSQL이란?
-
“Not Only SQL” : 데이터를 저장하는 데에는 SQL 외에 다른 방법들도 있다.
-
NoSQL이라고 하는 말은 No ‘English’ 라고 하는 말과 마찬가지다.
-
세상에는 영어 말고도 수많은 언어가 존재한다.
-
MongoDB에서 사용하는 쿼리 언어와 CouchDB에서 사용하는 쿼리 언어는 서로 전혀 다르다.
-
그럼에도 이 두 쿼리 언어는 같은 NoSQL 카테고리에 속한다.
-
어쨌거나 SQL이 아니기 때문이다.
-
또한 NoSQL이 No RDBMS를 의미하지는 않는다.
-
BerkleyDB같은 예외가 있기 때문이다.
-
그리고 No RDBMS가 NoSQL인 것도 아니다. SQL호환 레이어를 제공하는 KV-store라는 예외가 역시 존재한다.
-
사실 아직까지 NoSQL에 내려진 구체적인 정의는 없다.
-
하지만 NoSQL이라 불리는 데이터베이스들은 대체로 다음과 같은 공통적인 성향을 보인다.
-
대부분 클러스터에서 실행할 목적으로 만들어졌기 때문에 관계형 모델을 사용하지 않는다.
그러나 모든 NoSQL 데이터베이스가 클러스터에서 실행되도록 맞춰진 것은 아니다.
예를 들어 NoSQL 데이터 모델 중 하나인 그래프 데이터베이스는 관계형 데이터베이스와 비슷한 분산 모델을 사용한다. -
오픈 소스이다.
비오픈 소스 프로젝트도 있긴 하지만, 대부분 오픈 소스이다. -
스키마 없이 동작하며 구조에 대한 정의를 변경할 필요 없이 데이터베이스 레코드에 자유롭게 필드를 추가할 수 있다.
등장 배경
-
지난 20년간, 데이터를 저장하는 데에는 관계형 데이터베이스가 사용되었다.
-
트랜잭션을 통한 안정적인 데이터 관리가 가장 중요한 이슈였기 때문이다.
-
하지만 웹 2.0 환경과 빅데이터가 등장하면서 RDBMS는 난관에 부딪히게 되었는데,
바로 데이터를 처리하는 데 필요한 비용의 증가때문이다. -
데이터와 트래픽의 양이 기하급수적으로 증가함에 따라
한 대에서 실행되도록 설계된 관계형 데이터베이스를 사용하는 것은 하드웨어적으로 큰 비용이 들게 되었다. -
장비의 성능이 좋을수록 성능을 향상시키는 데(Scale-up : 수직적 확장) 비용이 기하급수적으로 증가하기 때문이다.
-
NoSQL은 데이터의 일관성을 약간 포기한 대신
여러 대의 컴퓨터에 데이터를 분산하여 저장하는 것(Scale-out : 수평적 확장)을 목표로 등장하였다. -
NoSQL의 등장으로 작고 값싼 장비 여러 대로 대량의 데이터와 컴퓨팅 부하를 처리하는 것이 가능하게 되었다.
CAP이론
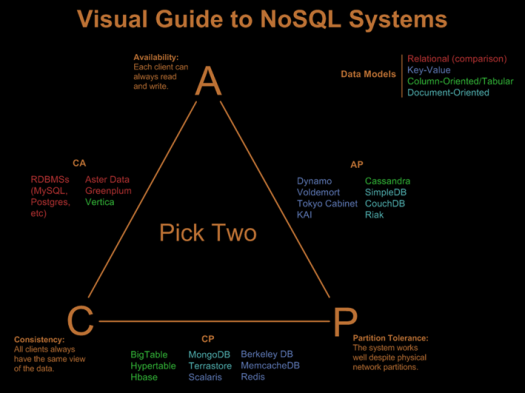
-
다음과 같은 질문을 할 수 있다.
-
RDBMS에서는 ACID라는 개념이 있다.
ACID(원자성, 일관성, 고립성, 지속성)는 데이터베이스 트랜젝션이 안전하게 수행된다는 것을 보장하기 위한 성질 -
그렇다면 NoSQL에서는?
-
ACID는 RDBMS에서 매우 중요하게 생각하는 성질이라 할 수 있다.
-
그런데 NoSQL에서는 찾아보기 힘든 단어이다.
-
CAP이론은 분산 시스템에서는 위 그림의 3개 속성을 모두 가지는 것이 불가능하다! 이다.
Consistency
-
CAP이론에서 말하는 Consistency는 ACID의 C가 아니다.
-
ACID의 ‘C’는 데이터는 항상 일관성 있는 상태를 유지해야 하고 데이터의 조작 후에도 무결성을 해치지 말아야 한다는 속성이다.
-
CAP의 ‘C’는 Single request/response operation sequence의 속성을 나타낸다.
-
그 말은 쓰기 동작이 완료된 후 발생하는 읽기 동작은 마지막으로 쓰여진 데이터를 리턴해야 한다는 것을 의미한다.
-
정리해보면 Consistency라는 단어보다는 Atomic이라는 단어가 더 정확하게 특징을 나타낸다고 할 수 있다.
-
일관성은 동시성 또는 동일성이라고도 하며
다중 클라이언트에서 같은 시간에 조회하는 데이터는
항상 동일한 데이터임을 보증하는 것을 의미한다. -
이것은 관계형 데이터베이스가 지원하는 가장 기본적인 기능이지만
일관성을 지원하지 않는 NoSQL을 사용한다면
데이터의 일관성이 느슨하게 처리되어 동일한 데이터가 나타나지 않을 수 있다. -
느슨하게 처리된다는 것은 데이터의 변경을 시간의 흐름에 따라 여러 노드에 전파하는 것을 말한다.
-
이러한 방법을 최종적으로 일관성이 유지된다고 하여 최종 일관성 또는 궁극적 일관성을 지원한다고 한다.
-
각 NoSQL들은 분산 노드 간의 데이터 동기화를 위해서 두 가지 방법을 사용한다.
-
첫번째로 데이터의 저장 결과를 클라이언트로 응답하기 전에 모든 노드에 데이터를 저장하는 동기식 방법이 있다.
그만큼 느린 응답시간을 보이지만 데이터의 정합성을 보장한다. -
두번째로 메모리나 임시 파일에 기록하고 클라이언트에 먼저 응답한 다음
특정 이벤트 또는 프로세스를 사용하여 노드로 데이터를 동기화하는 비동기식 방법이 있다.
빠른 응답시간을 보인다는 장점이 있지만, 쓰기 노드에 장애가 발생하였을 경우 데이터가 손실될 수 있다.
-
분산 시스템에서 일관성을 유지하기 위해서는 희생이 따른다.
-
카산드라(Cassandra DB)의 일관성 레벨
-
가용성과 분할 허용성을 지원하는 카산드라는 최종 일관성을 지원한다.
-
또한 설정값을 조절하여 강한 일관성을 지원할 수 있다.
-
많은 NoSQL 솔루션은 읽기와 쓰기의 성능 향상을 위해 데이터를 메모리에 임시로 기록한 다음
클라이언트에 응답하고 백그라운드 쓰레드(혹은 프로세스)로 해당 데이터를 디스크에 기록한다. -
방금 전에 언급했듯이 이 경우에는 데이터 손실의 위험이 존재하게 되는데
카산드라와 HBase에서는 이러한 손실을 방지하기 위해
메모리에 저장하기 전에 커밋로그 및 WAL파일에 먼저 정보를 기록하는 방법을 사용하고 있다. -
Redis에도 AOF(Append Only File)라는 기능이 존재한다.
Availability
-
특정 노드가 장애가 나도 서비스가 가능해야 한다라는 의미를 가진다.
-
데이터 저장소에 대한 모든 동작(read, write 등)은 항상 성공적으로 리턴되어야 한다.
-
명확해 보이는 단어이기는 하지만 분산 시스템에서의 특징을 말하는 것이기 때문에
서비스가 가능하다와 성공적으로 리턴이라는 표현이 애매하다. -
얼마동안 기다리는 것 까지를 성공적이라고 할 수 있느냐에 대한 문제가 남아있다.
-
20시간정도 기다렸더니 리턴이 왔어! Availability가 있는 시스템이야! 라고 할 수 없기 때문이다.
-
다시한번 성공적으로 리턴 에 대해서 보면
모든 동작에 대해서 시스템이 Fail 이라는 리턴을 성공적으로 보내준다면
그것을 Availability가 있다고 해야 하느냐에 대해서도 애매하다. -
CAP를 설명하는 문서들 중 Fail 이라고 리턴을 하는 경우도 성공적인 리턴 이라고 설명하는 것을 보았다.
-
NoSQL은 클러스터 내에서 몇 개의 노드가 망가지더라도 정상적인 서비스가 가능하다.
-
몇몇 NoSQL은 가용성을 보장하기 위해 데이터 복제(Replication)을 사용한다.
-
동일한 데이터를 다중 노드에 중복 저장하여 그 중 몇 대의 노드가 고장나도 데이터가 유실되지 않도록 하는 방법이다.
-
데이터 중복 저장 방법에는 동일한 데이터를 가진 저장소를 하나 더 생성하는 Master-Slave 복제 방법과
데이터 단위로 중복 저장하는 Peer-to-Peer 복제 방법이 있다.
단일 고장점이란?
-
단일 고장점이란 시스템을 구성하는 개별 요소 중에서 하나의 요소가 망가졌을 때
시스템 전체를 멈추게 만드는 요소를 말한다. -
단일 고장점을 가진 NoSQL은 자체적으로 가용성을 지원하지 못하기 때문에
이를 지원하기 위해 별도의 솔루션을 함께 사용하기도 한다. -
단일 고장점을 가진 솔루션들은 분산 환경에서 전체 서비스가 중단되는
심각한 문제가 발생할 수 있기 때문에 기피 대상이다.
Tolerance to network Partitions
-
분할 허용성이란 지역적으로 분할된 네트워크 환경에서 동작하는 시스템에서
두 지역 간의 네트워크가 단절되거나 네트워크 데이터의 유실이 일어나더라도
각 지역 내의 시스템은 정상적으로 동작해야 함을 의미한다. -
원래는 Tolerance to network Partitions인데 보통은 Partition-tolerance라고도 한다.
-
즉 노드간에 통신 문제가 생겨서 메시지를 주고받지 못하는 상황이라도 동작해야 한다.
-
Availablity와의 차이점은 Availability는 특정 노드가 장애가 발생한 상황에 대한 것이고
-
Tolerance to network Partitions는 노드의 상태는 정상이지만
네트워크 등의 문제로 서로 간의 연결이 끊어진 상황에 대한 것이다.
NoSQL 종류
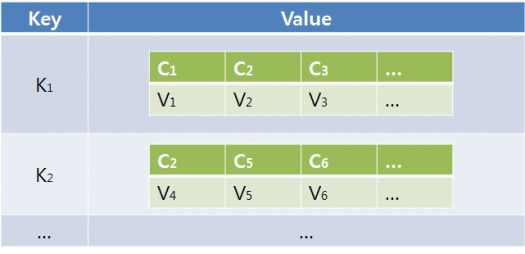
Key-Value Model
-
가장 기본적인 형태의 NoSQL이며 키 하나로 데이터 하나를 저장하고 조회할 수 있는 단일 Key-Value 구조를 갖는다.
-
키는 값에 접근하기 위한 용도로 사용되며, 값은 어떠한 형태의 데이터라도 담을 수 있다.
-
심지어는 이미지나 비디오도 가능하다.
-
또한 간단한 API를 제공하는 만큼 질의의 속도가 굉장히 빠른 편이다.
-
단순한 저장구조로 인하여 복잡한 조회 연산을 지원하지 않는다.
-
고속 읽기와 쓰기에 최적화된 경우가 많다.
-
사용자의 프로필 정보, 웹 서버 클러스터를 위한 세션 정보, 장바구니 정보, URL 단축 정보 저장 등에 사용한다.
-
하나의 서비스 요청에 다수의 데이터 조회 및 수정 연산이 발생하면
트랜잭션 처리가 불가능하여 데이터 정합성을 보장할 수 없다. -
Key-Value 모델을 사용하는 NoSQL 데이터베이스로는 Memcached, Riak, Redis, Amazon Dynamo DB, LevelDB 등이 있다.

Document Model
-
Key-Value 모델에서 한층 진화한 모델로 생각할 수 있다.
-
검색에 최적화되어 있는데, 이는 Key-Value 모델의 특징과 동일하다.
-
데이터는 키와 도큐먼트(Document)의 형태로 저장된다.
-
키는 문서에 대한 ID로 표현된다.
-
또한 저장된 문서를 컬렉션으로 관리하며 문서 저장과 동시에 문서 ID에 대한 인덱스를 생성한다.
-
문서 ID에 대한 인덱스를 사용하여 O(1)시간 안에 문서를 조회할 수 있다.
-
Key-Value 모델과 다른 점이라면 Value가 계층적인 형태인 도큐먼트로 저장된다는 것이다.
-
객체 지향에서의 객체와 유사하며 이들은 하나의 단위로 취급되어 저장된다.
-
다시 말해 하나의 객체를 여러 개의 테이블에 나눠 저장할 필요가 없어진다는 뜻이다.
-
또한 Document 모델에서는 도큐먼트 내의 Item을 이용한 쿼리가 가능하다.
-
다만 이를 위해서는 Xquery나 다른 도큐먼트 질의 언어가 필요하다.
-
도큐먼트 모델에서는 질의의 결과가 JSON이나 XML 형태로 출력되기 때문에
그 사용 방법이 RDBMS에서의 질의 결과를 사용하는 방법과 다르다. -
그렇기에 쿼리를 사용하는데 익숙해지기까지 다소 어려움이 있을 수 있다.
-
대부분의 문서 모델 NoSQL은 B트리 인덱스를 사용하여 2차 인덱스를 생성한다.
-
B트리는 크기가 커지면 커질수록 새로운 데이터를 입력하거나 삭제할 때 성능이 떨어지게 된다.
-
그렇기 때문에 읽기와 쓰기의 비율이 7:3 정도일 때 가장 좋은 성능을 보인다.
-
중앙 집중식 로그 저장, 타임라인 저장, 통계 정보 저장 등에 사용된다.
-
Document 모델을 사용하는 NoSQL 데이터베이스로는 MongoDB, CouchDB, MarkLogic 등이 있다.

Column Model
-
하나의 키에 여러 개의 컬럼 이름과 컬럼 값의 쌍으로 이루어진 데이터를 저장하고 조회한다.
-
모든 컬럼은 항상 타임 스탬프 값과 함께 저장된다.
-
컬럼형 NoSQL은 구글의 Big Table 영향을 받았다.
-
이러한 이유로 Row key, Column Key, Column Family 같은 Big Table 개념이 공통적으로 사용된다.
-
저장의 기본 단위는 컬럼으로 컬럼은 컬럼 이름과 컬럼 값, 타임스탬프로 구성된다.
-
이러한 컬럼들의 집합이 Row(Row)이며, Row키(Row key)는 각 Row를 유일하게 식별하는 값이다.
-
이러한 Row들의 집합은 키 스페이스(Key Space)가 된다.
-
대부분의 컬럼 모델 NoSQL은 쓰기와 읽기 중에 쓰기에 더 특화되어 있다.
-
데이터를 먼저 커밋 로그와 메모리에 저장한 후 응답하기 때문에 빠른 응답 속도를 제공한다.
-
그렇기 때문에 읽기 연산 대비 쓰기 연산이 많은 서비스나
빠른 시간 안에 대량의 데이터를 입력하고 조회하는 서비스를 구현할 때 가장 좋은 성능을 보인다. -
채팅 내용 저장, 실시간 분석을 위한 데이터 저장소 등의 서비스 구현에 적합하다.
-
클러스터링이 쉽게 이뤄지며 Time stamp가 존재해 값이 수정된 히스토리를 알 수 있다.
-
또한 값들은 일련의 바이너리 데이터로 존재하기 때문에 어떤 형태의 데이터라도 저장될 수 있다.
-
다만 위의 두 모델들과는 다르게 Blob 단위의 쿼리가 불가능하며 로우와 컬럼의 초기 디자인이 중요하다.
-
Schema Less이긴 하지만 새로운 필드를 만드는 데 드는 비용이 크기 때문에
사실상 결정된 스키마를 변경하는 것이 어렵다. -
Column-family 모델을 사용하는 NoSQL 데이터베이스로는 Google Big Table, HBase, Cassandra, Hypertable 등이 있다.
아직은 걸음마 단계이다.
-
오픈소스로 공개되어 있는 NoSQL은 굉장히 많다.
-
많은 기업들이 NoSQL을 도입하기 위해 여러가지 시도들을 하고 있다.
-
하지만 아직까지 주요 데이터 저장소로 RDBMS를 사용하는 경우가 거의 대부분인 것이 현실이다.
-
왜 그럴까?
-
많은 이유가 있을 수 있겠지만,
그 중 중요한 하나는 배포 중인 NoSQL들이 범용적으로 사용하기에는 아직 부족한점이 너무도 많다는 것이다. -
서비스를 구현하는데 반드시 필요한 것들이 있다.
-
바로 인덱싱과 트랜잭션이다.
-
이것들 없이도 어떻게든 잘 구현 할 수 있는 특수 목적의 시스템을 제외하면
이런 기능들은 제대로된 서비스를 만들기 위해서 반드시 필요하다. -
이런 기능들이 제공되지 않으면 범용적인 사용이 불가능하며,
충분히 추상화되지 못한 상태에서 구상적인 문제를 해결하기 위해 쓸데없는 시간을 보내게 된다. -
현재 배포되어 있는 NoSQL들은 이와 같은 기능이 아예 없거나 제한적이다.
-
Transaction의 경우 NoSQL상에서 분산 트랜잭션을 구현하기 위한 Transaction을 구현하기 위한 시도들이 있었다.
-
Elastras와 CloudTPS이다. 하지만 그다지 효용은 없었던 것 같다.
-
그런데 !!!
-
구글은 모든 문제를 해결하였다.
-
Transaction과 관련하여 구글이 2010년에 논문을 내놓았다.
-
Percolator인데 BigTable구조의 스토어에서 분산트랜잭션을 구현하는 방법에 대해 기술해 놓았다.
-
완벽하게 동작히며 선형 확장성도 있다.
-
이미 구글의 실제 돌아가는 시스템에서 성공적으로 사용되고 있다.
-
HBase상에서 돌아가는 분산트랜잭션인 HBaseSI를 소개하는 프리젠테이션에서는 자신들의 방법이 살짝 부족하긴 해도 알고봤더니 구글의 Percolator와 비슷한 방법이라고 자랑질을 할 정도이니 더 이상 언급하지 않아도 될 것 같다.
-
그리고 이미 구글의 클라우드 서비스인 AppEngine에서는 BigTable을 기본 데이터 저장소로 사용할 수 있도록 해주며, 인덱싱과 트랜잭션을 완벽하게 제공한다.
-
바로 구글의 Datastore 서비스인데, Megastore라는 시스템상에서 돌아간다.
-
이런 기능들이 제공되는 뿐만아니라 여러 데이터베이스간 분산 저장을 한다고하니 정말 대단하다.
결론
-
거의 대부분의 서비스에서는 NoSQL을 사용하지 않는다.
-
그리고 그 이유는 트랜잭션과 같은 일반적인 서비스 구현에 필요한 기능들이 전혀 준비되어 있지 않기 때문이다.
-
사실 트랜잭션이나 인덱싱이 필요하지 않거나 중요하지 않은 특수한 시스템을 구현한다고 한다면
NoSQL에서 제공되는 기능으로도 충분한 것이다. -
오히려 NoSQL을 사용하는 것이 시스템 구현에 있어서 편리한 부분이 있을 수 있다.
-
하지만 일반적인 서비스를 구현하기에 부족한 점이 너무나 많다.
-
하지만 구글의 경우 모든 것을 해결한 시스템을 BigTable상에 구현했으며 이미 몇 년동안 서비스하고 있다.
-
대부분의 사람들은 NoSQL이 RDBMS를 대체할 수 있을 것이라고는 생각하지 않는다.
-
그러기에는 RDBMS가 가진 장점이 너무나 명확하고
또한 많은 사람들이 RDBMS을 사용하는 데 익숙해져 있기 때문이다. -
그럼에도 불구하고 NoSQL이 각광받고 있는 까닭은 NoSQL만의 장점이 뚜렷하기 때문이다.
예를 들어
구매 내역이나 게임의 로그 같은 데이터들은 매 초마다 엄청난 양이 생성되지만 한번 저장되고 난 뒤에는 수정 될 일이 거의 없다.
이런 데이터들을 저장하는 데 데이터의 일관성을 보장하기 위해 ACID 트랜잭션을 지원할 필요는 없을 것이다.
거기다 생성되는 데이터의 양도 많기 때문에 장비의 성능에도 상당한 영향을 미칠 것이다.
NoSQL은 이러한 데이터들을 효율적으로 저장할 수 있다.
여러 대의 장비에 빠른 속도로 저장이 가능하며,
데이터의 양이 누적되더라도 얼마든지 수평적 확장이 가능하기 때문이다.
실제로 페이스북이나 트위터 같은 소셜 네트워크 서비스에서는 게시글들을 저장하는 데 NoSQL 데이터베이스를 사용하고 있다.
매 초에 수백 기가 ~ 수 테라 바이트씩 생성되는 데이터들을 RDBMS를 사용해 저장한다면,
글 작성 버튼을 누른 후
글이 중앙 데이터베이스에 저장되기까지 한참을 기다려야 글을 성공적으로 게시할 수 있을 것이다.
하지만 NoSQL의 분산 데이터베이스를 사용한다면
부하가 분산되기 때문에 우리가 글쓰기 버튼을 누르고 한참을 기다릴 필요가 없게 된다.
하지만 데이터의 일관성이 보장되어야 하거나 여러번의 조인 연산이 필요한 데이터라면
NoSQL을 사용하는 것 보다 RDBMS를 사용하는 것이 좋을 것이다.
NoSQL은 RDBMS를 대체하기 위한 데이터베이스가 아니라
상호 보완할 수 있는 데이터베이스이며
따라서 목적에 맞게 사용하는 것이 중요하다.