- ACID 준수와 CAP 정리
- CAP를 활용한 데이터베이스 선택
- 캐싱 기술
- 콘텐츠 분산 네트워크(CDN)
- 복원력 설계하기
- 분산 스토리지 솔루션
- 하둡 분산 파일 시스템
- Refernece
이 글은 강의 내용을 토대로 작성하였습니다.
ACID 준수와 CAP 정리
-
일관성 (Consistency)
= Write 이후 Read 시 바로 값을 조회할 수 있느냐?
-
가용성 (Availability)
= 단일 고장 점(single point of failure, SPOF)이 존재하는가?
-
분할 허용성 (Partition Tolerance)
= 수평 스케일링이 쉽게 가능한가?
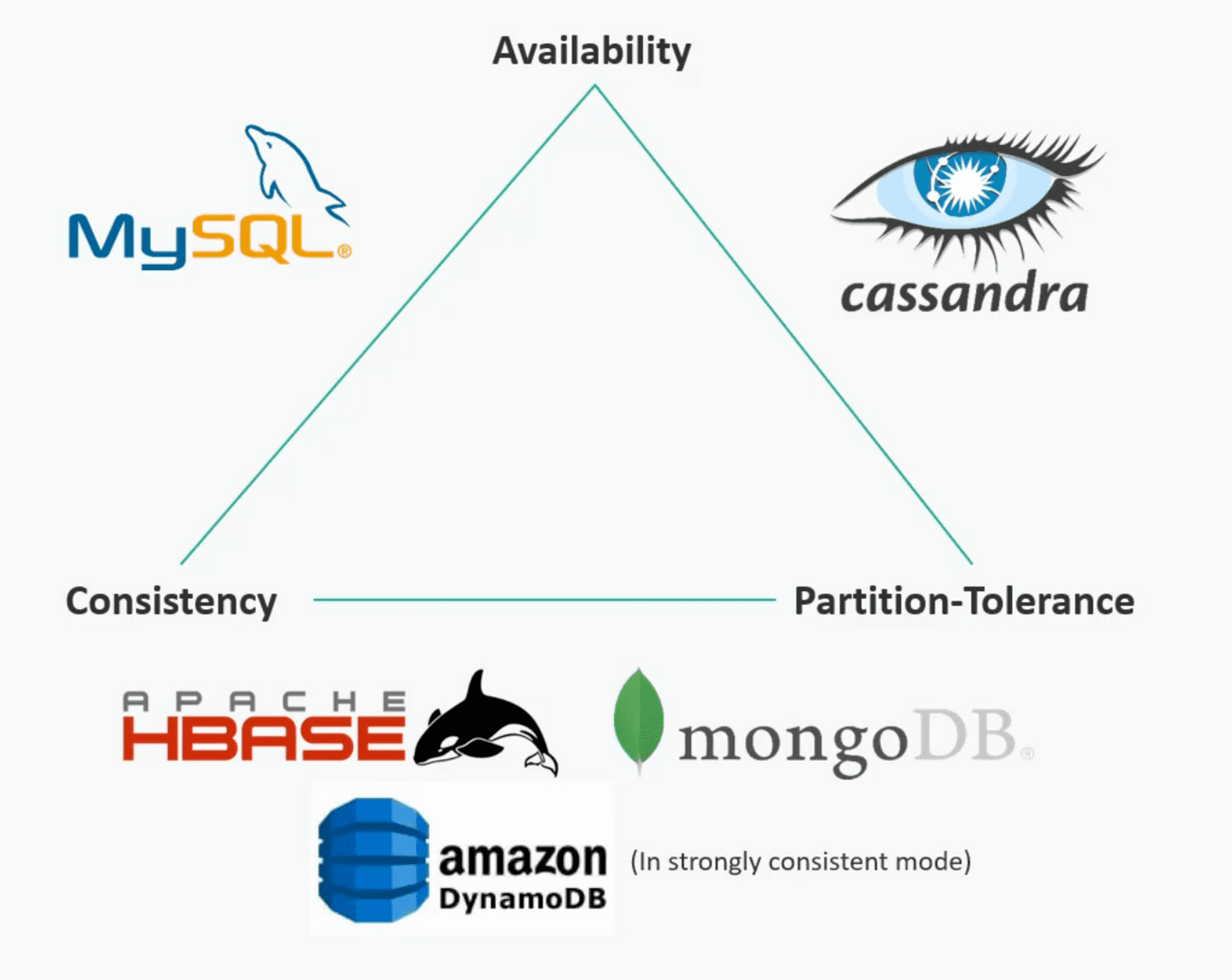
CAP를 활용한 데이터베이스 선택
몽고 DB

- 트레이드오프 : Availability
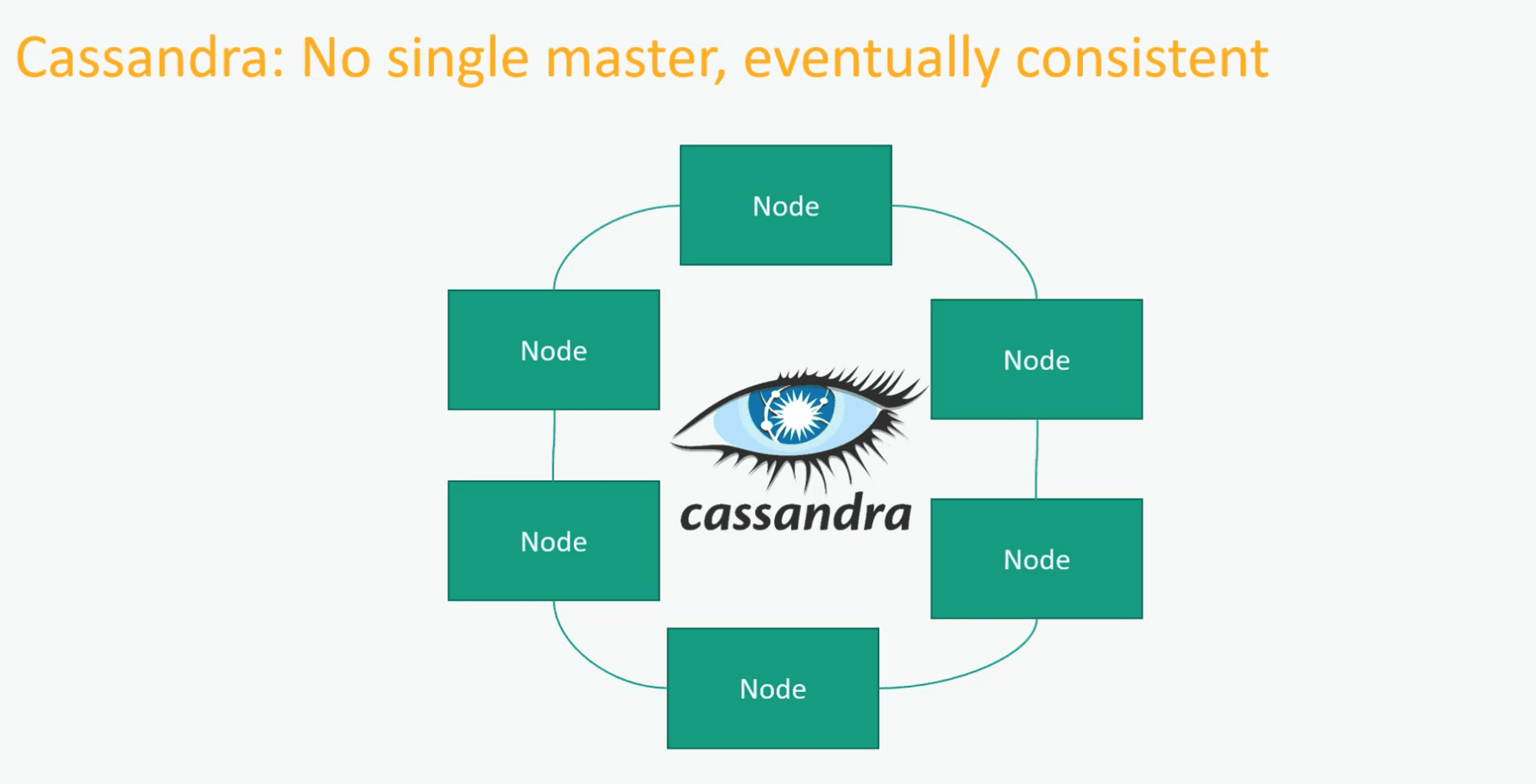
카산드라 DB
-
트레이드오프 : Consistency
-
단일 마스터 노드 존재 X
모든 노드가 죽어야지 가용성에 문제가 발생했음을 인지할 수 있음
-
데이터 복제
모든 노드에 복사
그러므로 100% 일관성 보장 X
= 모든 노드에 값이 복사되기 전에 복사가 되지 않은 노드에 Read 요청 시 데이터 불일치 발생
만약 면접에서 NoSQL DB를 선택해야 한다면?
-
이런 질문을 해보자
C, A, P 중 중요한 부분이 어떤 건지?
중요한 부분은 무엇인가?
일관성인가, 가용성인가?
아니면 파티션 수용성인가?
가용성이 중요하다면, 얼마나 중요한가?
몇 초간의 정지는 괜찮은가?
만약 괜찮다고 답변하셨다면 정말로 정지가 몇 초 정도에
불과하다면 가용성을 트레이드오프할 수 있습니다.
- 면접에서 DB 선택 시 트레이드오프에 대한 언급을 하면 점수를 따낼 수 있다.
캐싱 기술

핫스팟 문제
-
캐시의 Key는 일반적으로 공통된 로직을 적용
= 데이터의 분산이 고르지 않을 수 있음
-
해결 방법
특정 Key는 공통 로직이 아닌 따로 관리
ex) 화이트리스트
초기 캐시 문제 (Cold Start)
-
캐시 레이어가 재시작된다면?
해당 레이어에는 값이 없다.
= 모든 요청이 DB를 통한다.
= 장애 발생 가능성이 높아짐
-
해결 방법
실제로 운영을 하기 전에 미리 캐시를 적재하는 과정을 거친다.
= Warm Up을 시켜놓는다.
콘텐츠 분산 네트워크(CDN)
CDN은 비싸다.
- 그러므로 정말 신중하게 고려해서 정적 데이터를 선정해야 한다.
복원력 설계하기
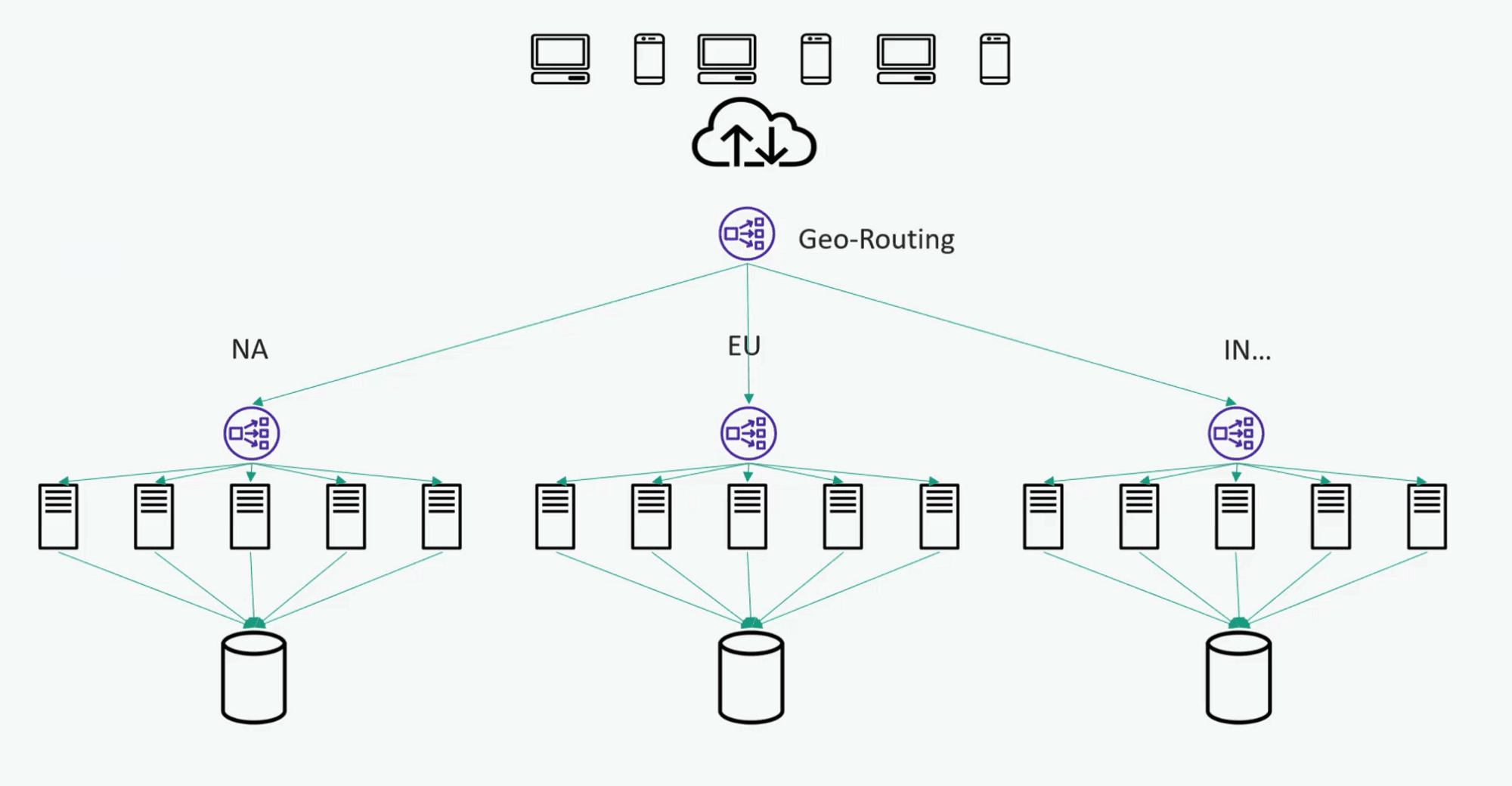
위치 기반 라우팅
-
한 지역에 장애 발생 시
자동으로 해당 지역으로 트래픽 송신 X
최대한 가까운 지역으로 라우팅 하여 서비스 제공
-
고려 사항
특정 지역의 용량은 생각보다 커야 한다.
Why? 타 지역의 트래픽까지 감당할 수 있어야 함
면접에서는 이 부분을 강조하는 게 중요
오버 프로비저닝
-
무조건 “위치 기반으로 합니다.”가 아니라
오버 프로비저닝이라는 옵션도 알고 있음을 어필하면 좋음
-
오버 프로비저닝이란 스케일 아웃처럼 더 많은 돈을 투자해 하드웨어를 구축하는 것을 뜻함
-
근데 잠깐 장애가 발생해도 괜찮은 서비스라면 굳이 오버 프로비저닝을 할 필요 X
그냥 타 지역으로 라우팅 하는 게 비용 측면에서 저렴
분산 스토리지 솔루션
빅데이터란?
- 분석 전에 전처리가 필요하거나 비정형 데이터 또는 미가공 데이터를 의미
SLA (Service Level Agreement)

-
시스템의 내구성에 대한 백분위수의 계약
ex) 99.999_999_999_99% 내구성이란 0.000_000_000_01의 확률로 데이터를 잃을 수 있다는 뜻
즉 SLA 값은 좋은 결과물을 낼 수 있는 확률을 뜻함
ex) 9가 3개인(99.9%) 지연 시간이 100ms라고 하면
이는 곧 99.9%로 이 요청이 100ms 안에 반환된다는 뜻
-
눈속임 조심
99%라고 하면 좋아 보이지만
365일 기준으로 보면 3.65일 동안 장애가 발생한다는 뜻
-
그래서 더 높은 가용성이 필요
예를 들면 99.9999%라면 연간 Down Time이 30초가 나옴
-
만약 어떤 SLA을 이행할지에 대한 질문을 받았다면?
고객이 허용할 수 있는 수준이 얼마인지 질문해야 함
하둡 분산 파일 시스템
HDFS (Hadoop Distributed File System) Architecture

-
HDFS 파일을 일정한 크기의 블록으로 나눔
대략 128MB
-
데이터 블록을 전체 클러스터에 복제
단 동일한 Rack에 백업 X
같은 곳에 저장하는 건 멍청한 짓
-
데이터 위치 조회
ex) HDFS에 접속해서 특정 파일의 콘텐츠를 복구하려 한다면?
해당 파일이 어디에 저장되어 있으며 어디에서 찾을 수 있는지에 대한 정보가 필요
그 정보를 알려주는 역할은 바로 Name Node (= Master Node)
-
Name Node
모든 운영 작업을 조정
클라이언트가 Name Node를 선택하고 특정 데이터 요구 시
이 요청에 대해 클라이언트 서버에서 가장 가까운 사본이 존재하는 곳을 응답
이렇게 하면 데이터 복구 시 최상의 성능을 뽑아낼 수 있음
Why?
가장 빠르게 접근 가능한 블록을 안내하기 때문
-
Metadata Store
블록의 위치 등에 대한 정보를 보관
Metadata Store도 백업 호스트가 존재할 수 있음
-
SPOF
Name Node가 1개이다.
그래서 HA 구조로 설정해서 복원력을 높이는 게 중요
-
Client
Name Node와 통신하여 가장 근처에 있는 Replica에서 데이터를 조회