이 글은 책 내용을 토대로 작성하였습니다.
목차
스트림
스트림 처리의 정의
-
n분 주기로 동작을 하거나 특정일에 동작하는 고정된 시간 개념을 버리고
이벤트가 발생할 때마다 처리한다는 게 스트림 처리의 정의이다.
이벤트 스트림 전송
메시징 시스템
-
새로운 이벤트 발생 시 소비자가 인지할 수 있도록 돕는 일반적인 방법은 메시징 시스템이다.
-
이러한 발행/구독(Publish/Subscribe) 모델을 사용하는 시스템은 다음과 같은 고민을 해봐야 한다.
Case 1
"생산자의 메시지 생성 속도 > 소비자의 메시지 소비 속도"와 같은 상황이라면 어떻게 해야 할까?
이런 경우 3가지 선택지가 있다.
1. 시스템은 메시지를 버린다.
2. 큐에 메시지를 버퍼링한다.
3. 배압(Backpressure, 흐름 제어)처리를 한다.
(= 생산자가 메시지를 더는 보내지 못하게 막는다.)
Case 2
노드가 죽거나 일시적으로 오프라인이 된다면 어떻게 될까?
손실되는 메시지가 있을까?
DB를 사용할 때처럼 지속성을 갖추려면
디스크에 기록하거나 복제본을 생성하거나 둘 모두를 해야 한다.
그러므로 비용이 든다.
- 스트림 시스템에서는 토픽(Topic)으로 관련 이벤트를 묶는다.
메시지 브로커
-
많은 메시지 시스템은 생산자 -> 소비자에게 직접 메시지를 전달한다.
하지만 이런 방식은 메시지 유실 가능성이 크다.
특히 소비자가 오프라인 상태라면 메시지를 전달받지 못하게 된다.
-
위 문제의 해결 방법으로 메시지 브로커(메시지 큐)와 같은 중간 노드를 둘 수 있다.
-
메시지 브로커는 서버로 구동되고
생산자와 소비자는 서버의 클라이언트로 접속하여
생산자는 브로커로 메시지를 전송 / 소비자는 브로커에서 메시지를 읽게 된다.
메시지 브로커 vs DB
- 메시지 브로커 <-> DB의 비슷한 듯 다른 특징에 대해 알아보자.
데이터 생명주기
DB는 명시적으로 데이터 삭제 요청이 있기 전까지 데이터를 보관한다.
반면 메시지 브로커 대부분은 소비자에게 데이터 전송이 성공할 경우 자동으로 삭제한다.
그러므로 오랜 기간 데이터를 저장하는 용도로 메시지 브로커의 사용은 적절하지 않다.
작업 용량 (Capacity)
메시지 브로커는 대부분 메시지를 빨리 지우므로 작업 용량이 상당히 작다.
즉 큐 크기가 작다.
만약 소비자의 소비 속도가 느려서
메시지 브로커가 많은 메시지를 버퍼링해야 한다면
메모리 -> 디스크로 내보낼 수도 있고
개별 메시지 처리 시간이 길어지고 전체 처리량이 저하된다.
데이터 변화 추적
DB는 요청 시점의 스냅 샷을 기준으로 데이터를 반환한다.
그래서 데이터 변화를 폴링하지 않는다면 앞선 결과가 최신 데이터인지 알 수 없다.
반면 메시지 브로커는 특정 스냅 샷 질의를 지원하지 않지만
데이터가 변하면 클라이언트에게 새로운 메시지가 생겼다는 알림을 줄 수 있다.
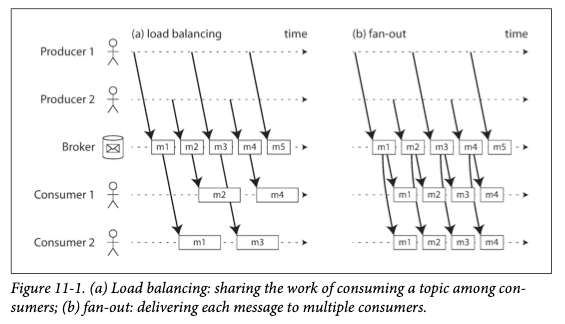
n명의 소비자
- n명의 소비자가 같은 토픽에서 메시지를 읽을 때 사용하는 주요 패턴 2가지를 알아보자.
로드 밸런싱
-
메시지 브로커는 랜덤으로 소비자를 선정해 메시지를 전달한다.
-
이런 방식은 메시지 처리 비용이 비싸 처리를 병렬화하기 위해 소비자를 추가하고 싶을 때 유용하다.
팬 아웃
-
각 메시지는 모든 소비자에게 전달된다.
-
팬 아웃 방식을 사용하면 여러 독립적인 소비자가
브로드캐스팅된 동일한 메시지를 서로 간섭 없이 받을 수 있다.
로드 밸런싱 + 팬 아웃
-
상황에 따라 2가지 패턴을 함께 사용할 수 있다.
예를 들어 2개의 소비자 그룹에서 하나의 토픽을 구독하고
각 그룹은 모든 메시지를 받지만
그룹 내에서는 각각 메시지를 하나의 노드만 받게 하는 식이다.
확인 응답과 재전송
-
소비자는 언제라도 장애가 발생할 수 있다.
브로커가 메시지를 소비자에게 전달했지만
소비자가 메시지를 처리하지 못하거나 부분적으로 처리 중 장애가 발생할 수 있다.
-
정상적으로 처리되지 못한 메시지를
재처리하기 위해 소비자는 브로커에게 다시 메시지를 달라고 요청을 보냈는데
만약 브로커가 메시지를 소비자에게 보내면서 바로 큐에서 삭제했다면
해당 메시지는 다시 받을 수 없게 된다.
-
브로커는 이런 의도치 않은 상황을 방지하고자
소비자가 메시지를 받았는지 확인 후 메시지를 삭제하기 위해 확인 응답을 요구한다.
-
그래서 클라이언트는 메시지 처리가 끝나면
브로커가 큐에서 메시지를 제거할 수 있게 브로커에게 명시적으로 알려야 한다.
-
부하를 균일하게 분산시켜야 하는 구조에서는
이런 재전송 행위는 메시지 순서에 영향을 미친다.
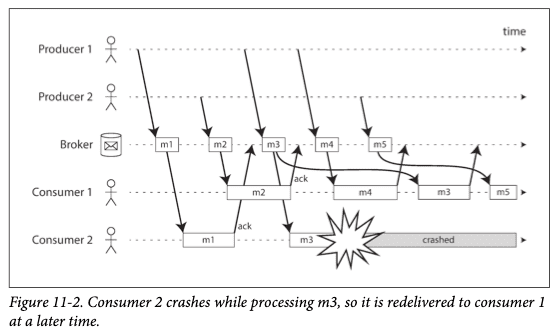
소비자 2가 메시지 m3를 처리하던 중 장애가 발생했다.
브로커는 m3의 확인 응답을 받지 못해 소비자 1에게 재전송을 하게 되고
소비자 1은 메시지 m4를 처리하다 그다음 메시지로 m3를 받게 된다.
그 결과 소비자 1은 m4->m3->m5 순서로 메시지를 처리한다.
즉 메시지 m3, m4는 생산자 1이 보낸 순서와 다르게 전달된다.
-
부하를 균일하게 분산시키는 구조에서 메시지 재전송을 조합하면
필연적으로 메시지 순서가 변경될 가능성이 있다.
-
만약 균일하게 분산시키지 않는 구조라면
소비자마다 독립된 큐를 사용하여 메시지가 임의로 변경되는 문제를 피할 순 있다.