Prologue
-
1편에서는 DB와 Redis를 사용하여 MQ를 구현하는 방법에 대해 알아봤다.
DB와 Redis만으로도 충분히 MQ의 목적을 살릴 수 있지만
그보다 MQ에 특화된 솔루션인 RabbitMQ와 Kafka에 대해 알아보자.
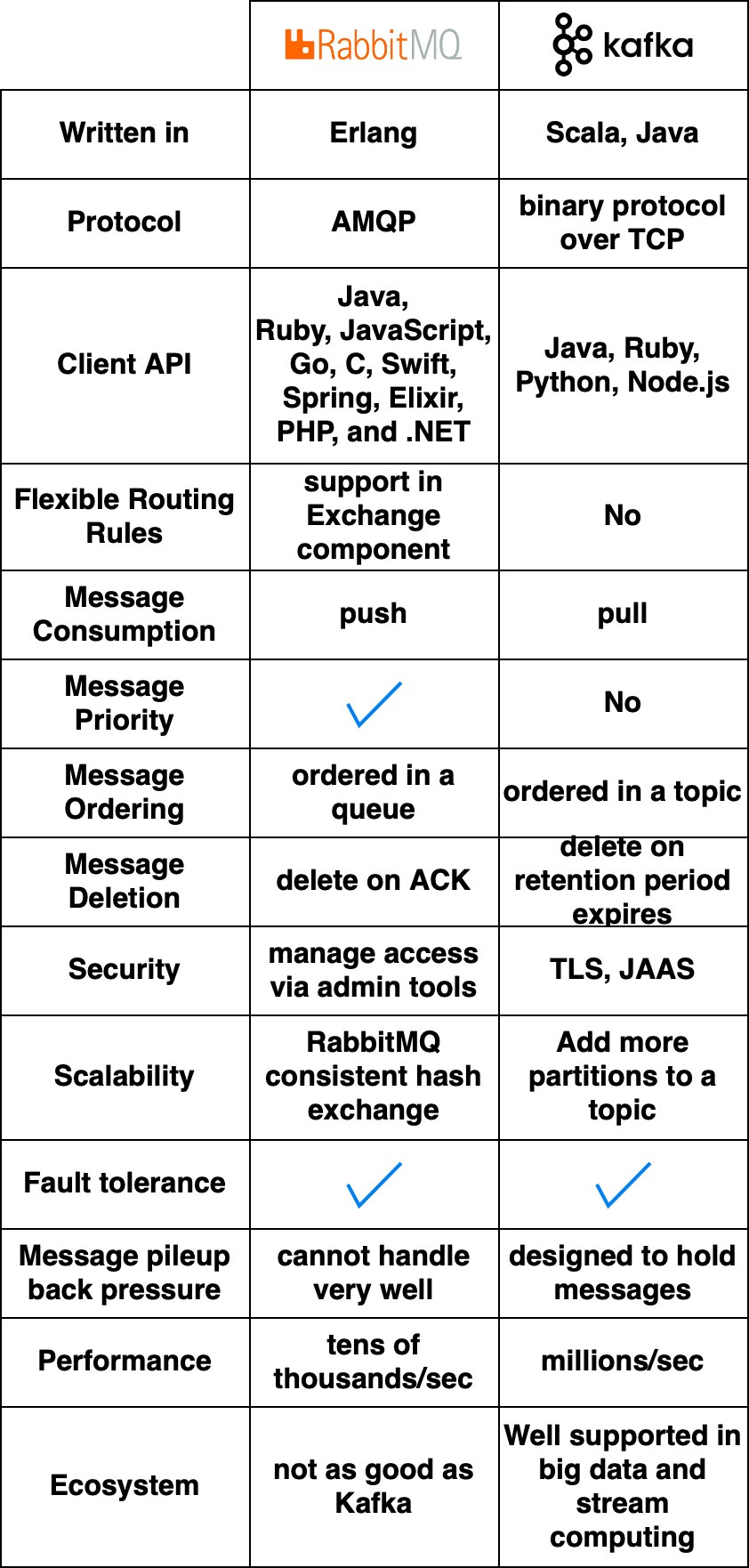
RabbitMQ vs. Kafka
-
RabbitMQ는 Messaging Middleware처럼 동작한다.
컨슈머에게 메시지를 Push 하고 컨슈머의 확인 응답을 받으면 메시지를 삭제한다.
이런 방식으로 메시지가 한 번 소비되면 삭제되어
다른 컨슈머가 동일한 메시지를 받지 중복 컨슘을 방지한다.
-
Kafka는 원래 대규모 로그 처리를 위해 구축되었다.
메시지가 만료될 때까지 메시지를 보관하며
컨슈머가 원하는 소비자가 원하는 속도로 메시지를 Pull 할 수 있다.
Languages and APIs
-
RabbitMQ는 Erlang으로 작성되었고 핵심 코드 수정이 어렵다.
매우 다양한 클라이언트 API 및 라이브러리를 지원한다.
-
Kafka는 Scala와 Java로 작성되었고
Python, Ruby, Node.js와 같은 언어에 대한 클라이언트 API 및 라이브러리를 지원한다.
Performance and Scalability
-
RabbitMQ는 초당 수만 개의 메시지를 처리한다.
하지만 H/W를 좋게 하더라도 처리량은 그다지 높아지지 않는다.
-
Kafka는 높은 확장성으로 초당 수백만 개의 메시지를 처리할 수 있다.
Ecosystem
-
최근에는 Big Data 및 Stream 애플리케이션에서 기본적으로 Kafka를 사용한다.
또한 개발 커뮤니티 또한 RabbitMQ에 비해 Kafka가 더 활성화되어있다.
Message Queue Use Cases
Log Processing and Analysis
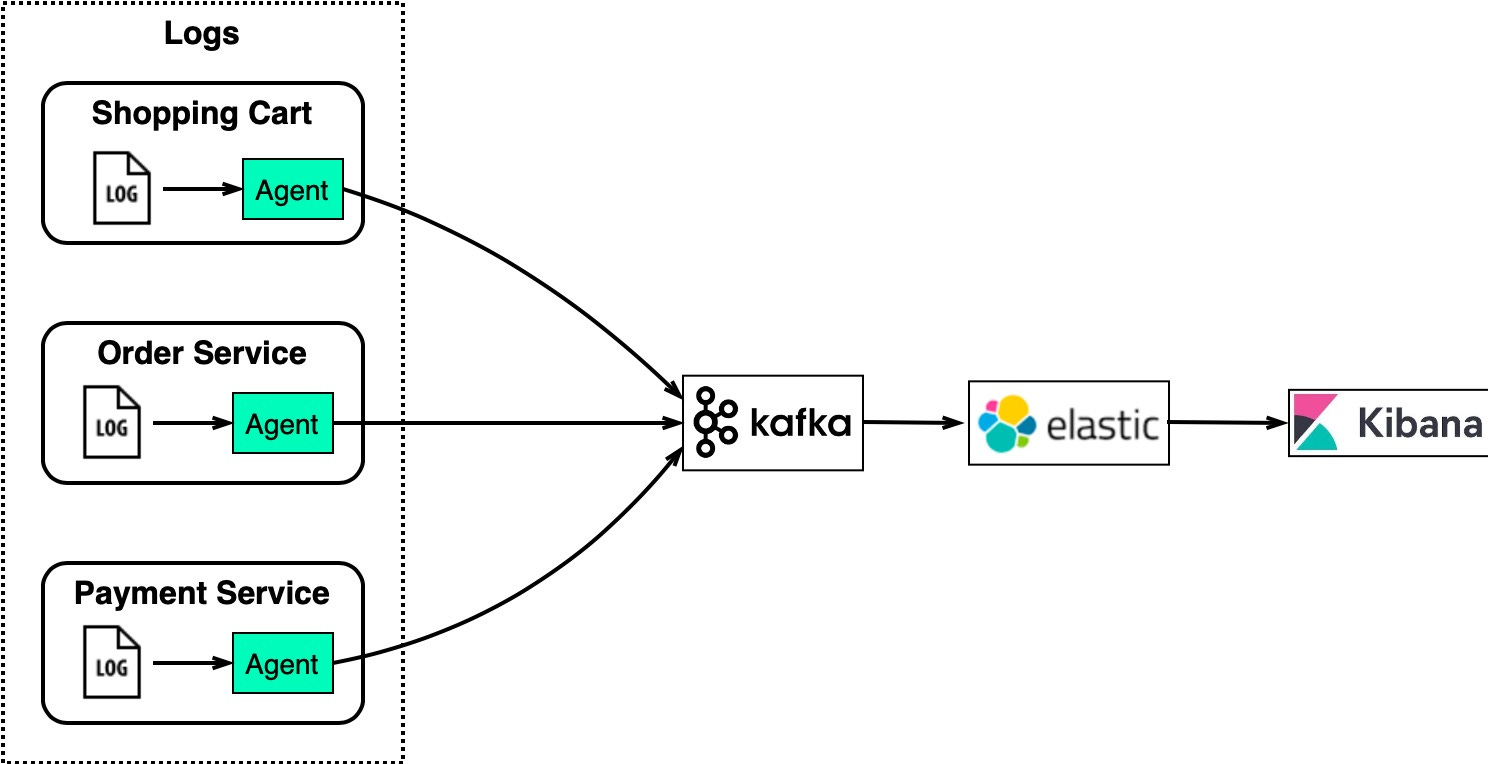
-
eCommerce 사이트의 경우
고객의 로그를 분석하여 상품 추천 등 데이터로 활용을 한다.
-
위 다이어그램은 ELK 스택을 사용하는 일반적인 아키텍처이다.
- LogStash - 로그 수집 에이전트 - Kafka - 분산 메시지 큐 - ElasticSearch - 전체 텍스트 검색을 위한 로그 인덱싱 - Kibana - 로그 검색 및 시각화를 위한 UI -
Kafka는 각 인스턴스에서 대용량 로그를 효율적으로 수집하고
ElasticSearch는 Kafka가 수집한 로그를 인덱싱하여 빠른 텍스트 검색을 할 수 있게 해 준다.
그리고 Kibana는 ElasticSearch에 올라간 데이터에 대해 검색 및 시각화 UI를 제공한다.
Data Streaming for Recommendations
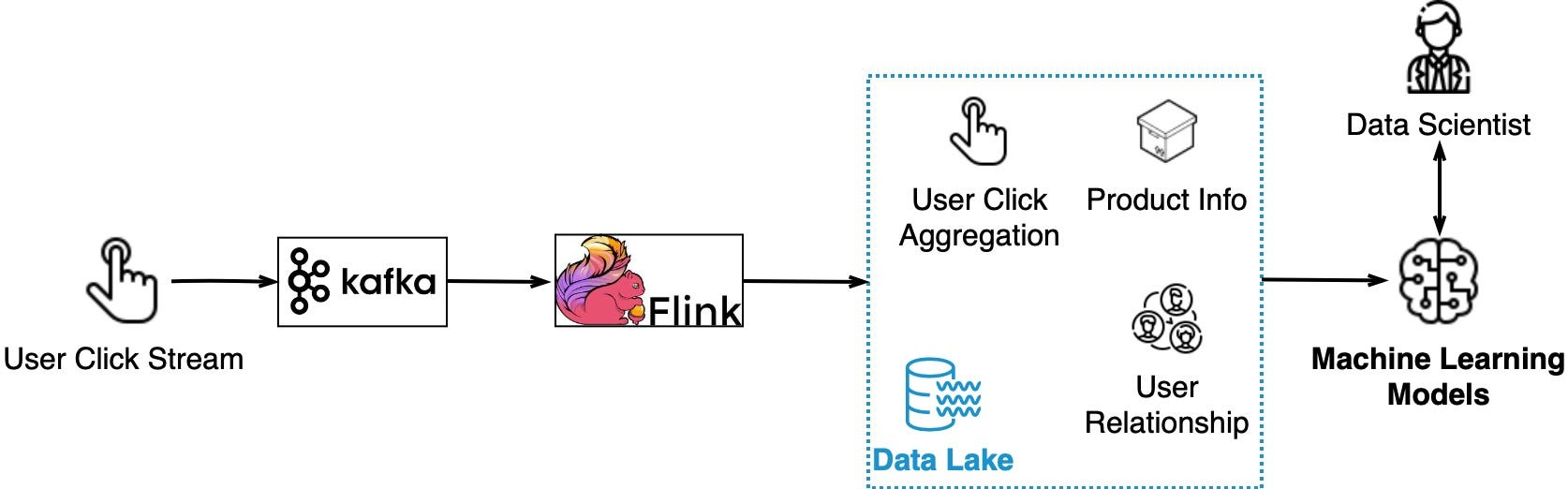
-
유저가 어떤 제품을 클릭하면
Click Stream은 Kafka에 의해 수집되고
Flink는 Click Stream 데이터를 집계한다.
-
그렇게 수집된 데이터는 Data Lake에서 적절하게 제품과 고객 간의 관계를 형성하고
Machine Learning 학습 데이터로도 사용되어
고객에게 제품을 추천하는데 도움을 준다.
-
결과적으로 위 과정을 통해
사용자 편의성을 증가시키는 구조를 갖게 된다.
System Monitoring and Alerting
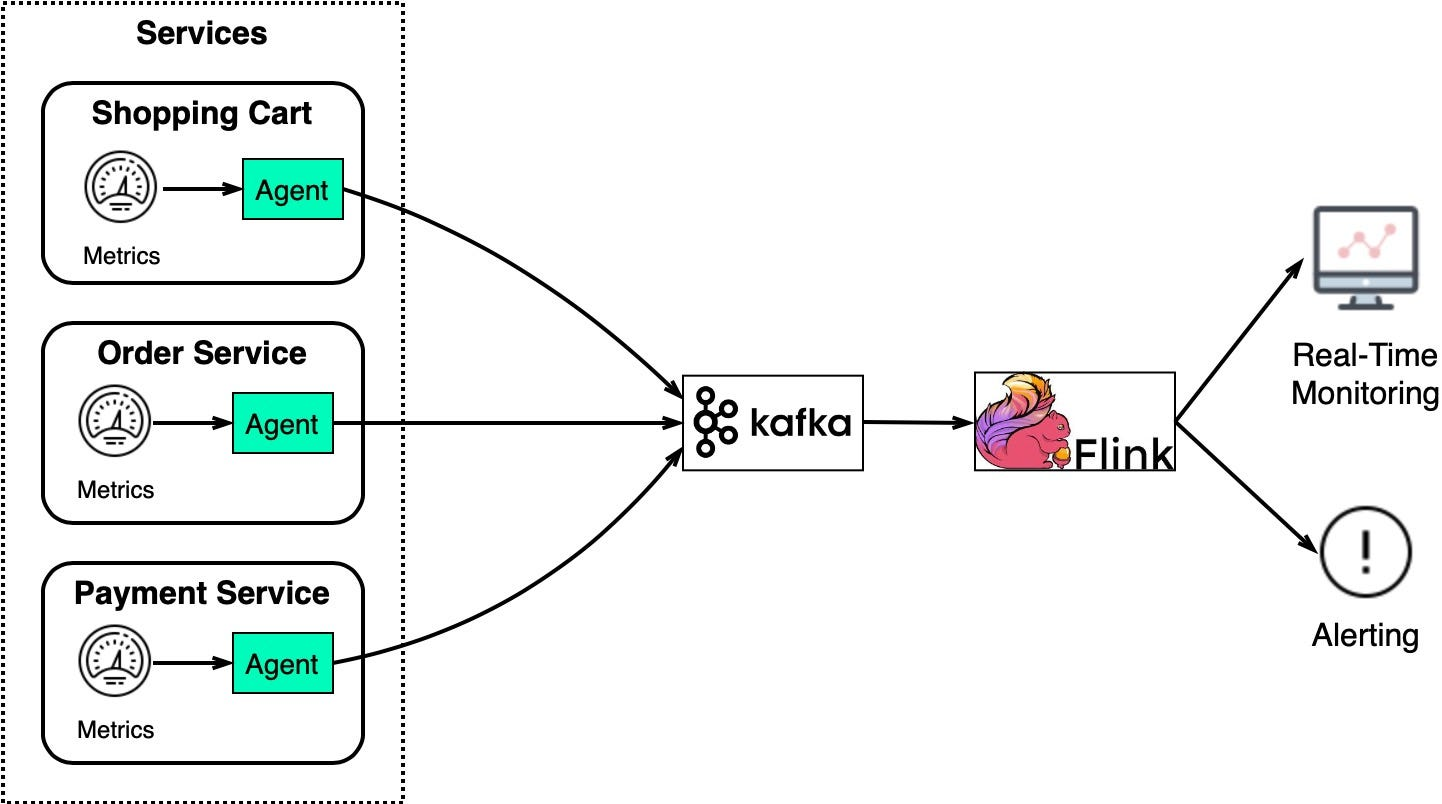
-
Log Processing and Analysis와 비슷하게
Monitoring과 Troubleshooting을 위해 System Metric 정보를 수집한다.
-
2개의 UseCase 차이는
Metric은 구조화된 데이터라면 Log는 비구조화된 텍스트이다.
-
Metric 데이터는 Kafka와 Flink로 전송되고
이렇게 수집된 데이터는 Real Time monitoring dashboard 및 Alerting System에 사용된다.
-
Metric 데이터는 다양한 수준으로 수집되고
그로 인해 전체 시스템을 보다 완벽하게 모니터링할 수 있게 만든다.
- Host level: CPU usage, memory usage, disk capacity, swap usage, I/O, network status
- Process level: pid, threads, open file descriptors
- Application level: throughput, latency, etc
Delayed Messages
-
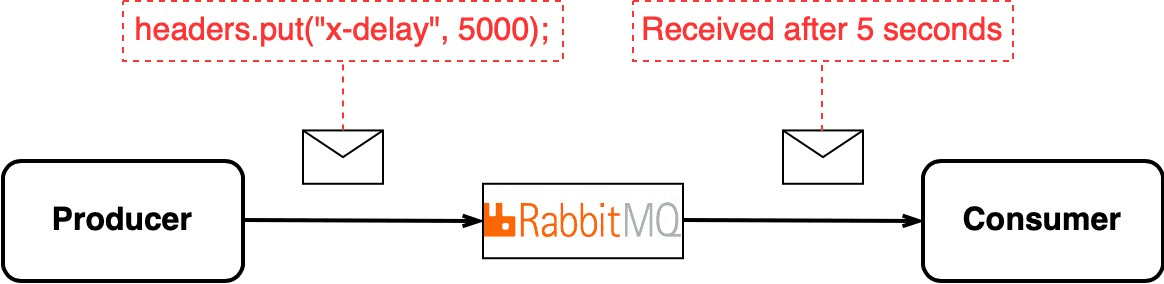
때로는 특정 메시지를 지연시키고 싶을 수 있다.
-
RabbitMQ는 메시지 헤더에 특정 값을 세팅하면 지연 기능을 사용할 수 있다.
-
반면 Kafka는 메시지를 실시간으로 전송하는 데에
중점을 두고 있으므로 지연시키는 기능은 명시적으로 내장되어 있지 않다.
-
그렇다고 지연 기능을 위해 RabbitMQ을 도입하는 건 멍청한 선택이다.
Kafka에서 지연 기능 사용 방법
출처 : Chat GPT
타임스탬프와 함께 메시지 전송
-
메시지에 전송 시간을 포함하여
컨슈머가 메시지를 처리하기전에 로직을 태워서 요구 사항을 충족시킨다.
## 프로듀서 메시지 전송 시
해당 메시지의 속성으로 타임스탬프를 추가하고
컨슈머는 이를 확인하여 일정 시간이 지난 후에만 메시지를 처리하도록 한다.
## 메시지 생성 (프로듀서)
메시지 생성 시 타임스탬프 필드에 현재 시간 또는 특정 시간을 기록하여 메시지를 생성한다.
{
"key": "value",
"timestamp": 1640000000,
"other_field": "other_value"
}
## 메시지 처리 (컨슈머)
컨슈머는 메시지의 타임스탬프를 보고 일정 시간이 지났는지 여부를 확인한다.
즉 지정된 시간이 경과한 메시지만을 처리하도록 컨슈머 로직을 구현한다.
Topic을 활용한 Delay Queue
-
즉시 처리해야 하는 토픽과 지연시켜 처리해야 하는 토픽을 생성하여
상황에 맞는 요구 사항을 충족시킬 수 있다.
## Immediate Topic 생성 (2개의 파티션)
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 2 --topic immediate-topic
## Delayed Topic 생성 (1개의 파티션)
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic delayed-topic
Apache Kafka Streams 또는 Kafka Connect를 사용한 처리
-
Kafka Streams 또는 Kafka Connect와 같은
Kafka의 스트리밍 라이브러리를 사용하여
메시지를 가져와서 지연시키는 작업을 수행할 수 있다.
추가 레이어 또는 서비스 도입
-
기존 Kafka 시스템에
추가적인 레이어 또는 서비스를 도입하여 지연 메시지를 처리할 수 있다.
ex) 메시지를 지연시키고 필요한 시간이 경과하면 다른 토픽으로 전송한다.
Change Data Capture
-
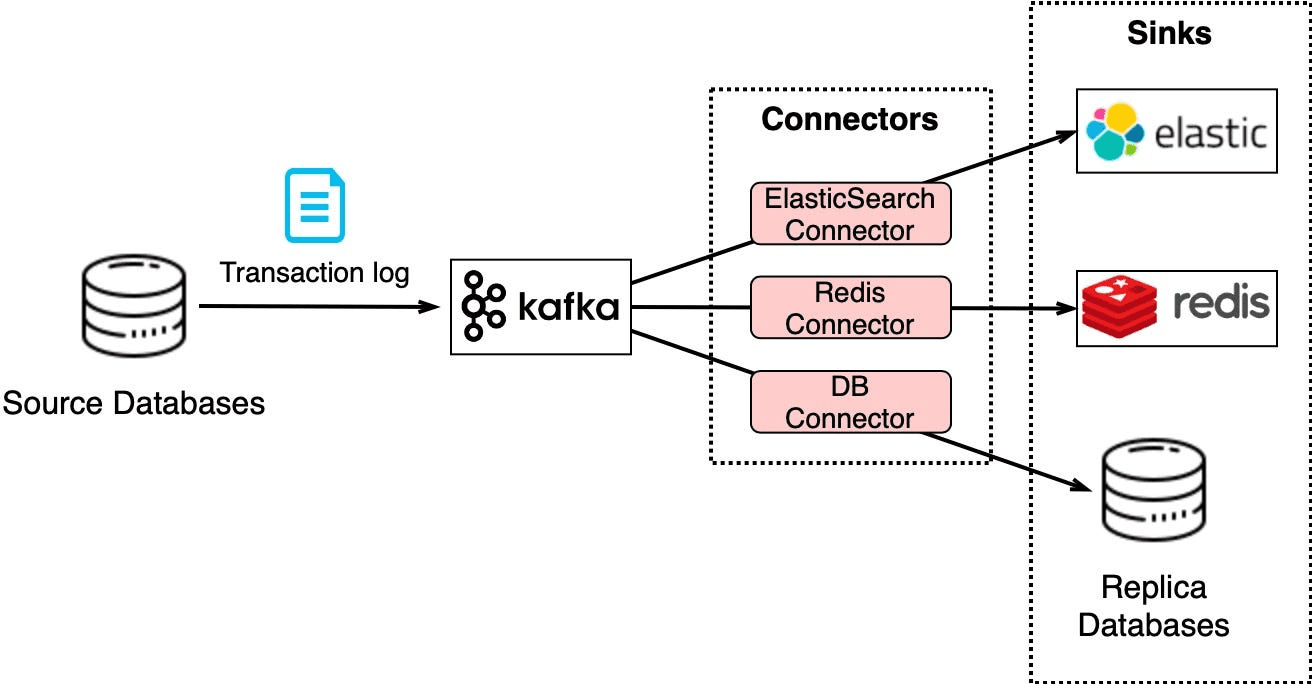
CDC(Change Data Capture)란
다른 시스템에 Replication 또는 Cache/Index 업데이트를 위해
DB 변경 사항을 Streaming 하는 개념을 뜻한다.
-
위그림을 보면 알 수 있듯이
Transaction Log는 Kafka로 전송되고
ElasticSearch, Redis 및 Replication DB는
그 목적에 맞게 데이터를 가공해 사용한다.
-
이러한 아키텍처는 데이터를 최신 상태로 유지하고 Horizontal Scalability를 쉽게 만든다.
예를 들어 또 다른 시스템을 추가하고자 한다면
Kafka Connector를 사용하여 스트리밍 하기만 하면 된다.
그래서 Kafka를 사용한 CDC는 굉장히 유연한 구조를 갖게 된다.
Application Migration
-
Legacy Services를 개선하는 것은 굉장히 어렵다.
그러나 MQ와 같은 미들웨어를 사용하면 위험을 줄일 수 있다.
-
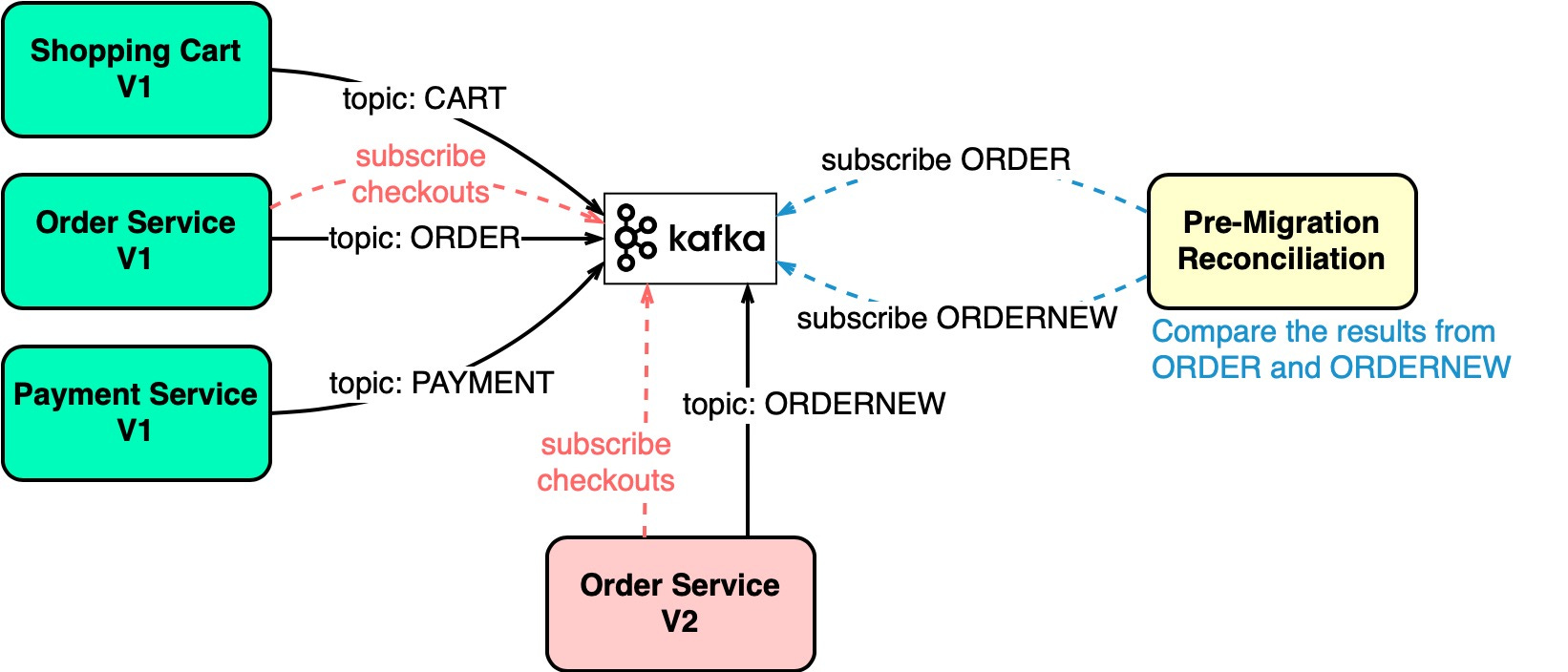
예를 들어 위 그림에서 Order Service를 개선하기 위해
기존 Order Service는 ORDER라는 Topic에 메시지를 전송하고
신규 Order Service는 ODERNEW라는 Topic에 메시지를 전송한다.
-
그리고 Pre-Migration Reconciliation은 ORDER와 ORDERNEW 값을 비교하여
만약 그 결과가 같다면 신규 Order Service는 문제가 없다고 판단할 수 있다.
-
정리하자면 Kafka Topic 개념을 활용하여
기존 Services와 신규 Services를 병렬로 운영하며
신규 Services에 대한 유효성을 검증을 손쉽게 할 수 있는 구조를 만들 수 있다.
-
즉 MQ를 사용하면 Legacy Services의 Migration Risk를 낮출 수 있다.
Summary
-
1편에 이어 이번 글에서도 Message Queue에 대해 알아봤다.
-
시스템이 더 크고 복잡하다면 Kafka 혹은 RabbitMQ를 고려할 수 있으며
만약 Delay Message 기능이 주요한 목적이라면
RabbitMQ를 사용하는 것도 좋은 선택지가 될 수 있다.
하지만 최근 트렌드는 아무래도 Kafka가 압도적이긴 하다. -
그 외 MQ를 사용한 다양한 Use Case도 알아봤다.
-
어떠한 기술이 무조건 정답은 아니므로
현재 상황을 보고 적절한 솔루션을 선택하도록 하자.