꾸준함이 실력입니다.
One Two be super Developer-
Redis를 MessageQueue로 활용하는 방법들의 장/단점 분석
Prologue
-
이전에 포스팅 한 “Redis를 MessageQueue로 활용하는 방법“글에서
Redis를 MessageQueue로 사용하는 3가지 방법에 대해 알아봤다.
-
사실 각 개념으로 보면 다 비슷해보이는 기능이라
언제 어떻게 다르게 사용해야하는거지?라는 생각이 들었고
그래서 각 방법별로 비교해보는 글을 작성하기로 하였다.
-
-
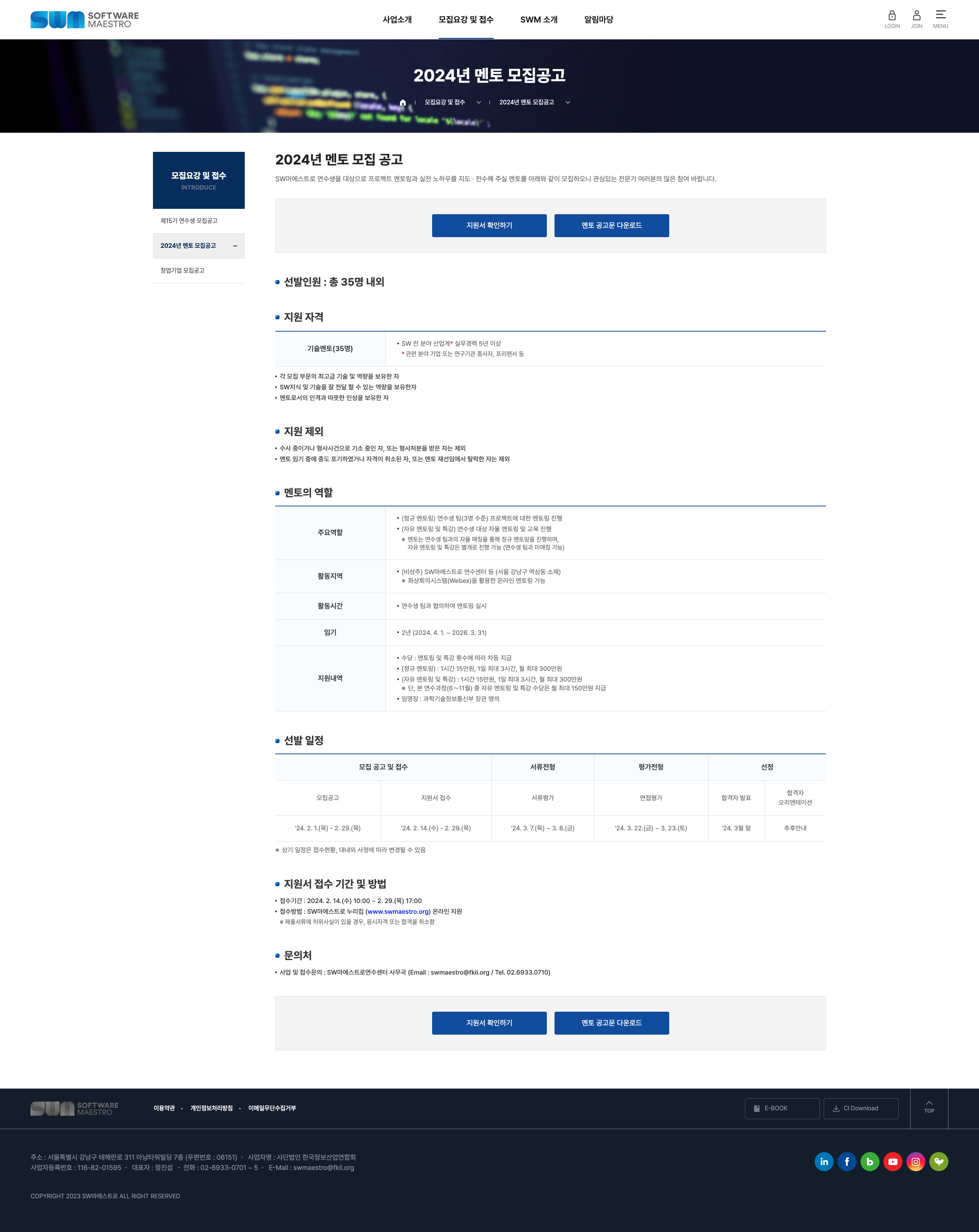
2024년 소프트웨어 마에스트로(Software Maestro) 멘토 지원 및 합격 후기
Prologue
-
Software Maestro에 멘토로 지원을 하였다.
-
사실 작년에 지원해보려 했는데 경력이 만 5년이 넘지 않으면
시스템상으로 지원이 불가능하여 내년을 기약하자 했고 만 5년이 지난 올해 바로 지원을 하였다.
-
-
좋은 코드 vs 나쁜 코드 (Good Code vs. Bad Code)
-
LeetCode : 155. Min Stack
Min Stack
Problem
Design a stack that supports push, pop, top, and retrieving the minimum element in constant time. Implement the MinStack class: MinStack() initializes the stack object. void push(int val) pushes the element val onto the stack. void pop() removes the element on the top of the stack. int top() gets the top element of the stack. int getMin() retrieves the minimum element in the stack. You must implement a solution with O(1) time complexity for each function.
-
Production 환경에서 Redis를 사용하는 가장 효과적인 6가지 방법 - Website Analytics, Flash Sale
연재 글 목록
-
Production 환경에서 Redis를 사용하는 가장 효과적인 6가지 방법 - Cache, Session Store
-
Production 환경에서 Redis를 사용하는 가장 효과적인 6가지 방법 - Leaderboard, Message Queue
-
Production 환경에서 Redis를 사용하는 가장 효과적인 6가지 방법 - Website Analytics, Flash Sale
Prologue
- 이번 글에서는 Redis를 활용한 Website Analytics, Flash Sale 사례를 살펴본다.
-
-
LeetCode : 576. Out of Boundary Paths
576. Out of Boundary Paths
Problem
There is an m x n grid with a ball. The ball is initially at the position [startRow, startColumn]. You are allowed to move the ball to one of the four adjacent cells in the grid (possibly out of the grid crossing the grid boundary). You can apply at most maxMove moves to the ball. Given the five integers m, n, maxMove, startRow, startColumn, return the number of paths to move the ball out of the grid boundary. Since the answer can be very large, return it modulo 109 + 7.
Recent Posts
- Cursor가 매일 수십억 건의 AI 코드 완성을 처리하는 방식
- A 레코드와 CNAME 레코드는 뭐가 다른걸까?
- 분산 시스템에서 순서가 보장되지 않은 이벤트를 다루는 전략
- DU(Disk Usage) 명령어를 아시나요?
- 2PC(Two-Phase Commit)란 무엇일까?
- DIG(Domain Information Groper) 명령어를 아시나요?
- 샤딩과 파티셔닝, 그 차이에 대하여
- LeetCode : 692. Top K Frequent Words
- Redis 서버에 접속중인 Client 목록 확인 방법
- LeetCode : 1299. Replace Elements with Greatest Element on Right Side
Categories
- Conference 11
- AlgorithmSkill 39
- DB 24
- Algorithm 175
- Crawling 1
- Node.js 15
- Linux 6
- AWS 11
- E.T.C 51
- Competition 5
- Python 26
- BlockChain 36
- MachineLearning 19
- 파일처리 14
- OS 12
- Server 31
- Docker 1
- Web 1
- JavaScript 18
- Network 39
- Git 6
- Technology 64
- DataStructure 1
- C/C++ 1
- HTTP 14
- Java 38
- Redis 9
- Retrospective 7
- Spring 72
- SpringBoot 16
- Kafka 26
- CleanCode 12
- TIL 4
- Blog 7
- Nginx 6
- MyBatis 6
- Regex 4
- EffectiveJava 2
- Spock 1
- Junit5 4
- Intellij 1
- CLI 1
- LeetCode 203
- MySQL 1
- JavaOptimizing 6
- Feign 1
- Karate 2
- Github 8
- SystemDesign 23
- Gradle 3
- Logback 3
- Kotlin 7
- CleanArchitecture 6
- Tech 6