문자열 인코딩 개념
-
문자열 인코딩이란
2진법을 사용하는 컴퓨터가
인간의 언어를 일정한 규칙에 따라 2진수로 변환하는 방식이다.
컴퓨터는 ‘안녕하세요’와 같은 문장을 그대로 읽고 처리할 수 없기 때문이다.
-
그래서 컴퓨터는
2진수와 문자를 1:1로 대응하는 규칙을 통해 2진수로 문자를 처리한다.
ex) ( 2진수 : 0100 0001 ) : ( 문자 : A )
Q. 인터넷에서 글자가 깨지거나 보이지 않는 문제는 왜 발생하는 걸까?
-
컴퓨터가 처음 등장했을 때
모든 프로그램은 영어와 일부 특수 문자만 지원했다.
그러나 시간이 지나 많은 국가가 컴퓨터를 사용하기 시작했고
국가별로 사용하는 언어를 표현하고자
독자적인 규칙을 만들기 시작했다.
참고로 한국에서는 독자적인 인코딩 방식인 EUC-KR을 만들었다.
-
독자적인 규칙을 만드는 움직임은
모든 언어를 같은 규칙으로 표현할 수 있는 유니코드 방식이 등장하면서 통일되었다.
-
그러나 모든 개발 환경이 유니코드를 동일하게 처리하지 않아
개발자는 서로 호환되지 않는 유니코드 문자열 인코딩 방식(UTF-8, UTF-16, UTF-32) 중 하나를 택해야 한다.
문자 집합 vs 문자열 인코딩
문자 집합
-
사용할 수 있는 문자들의 집합
ex) 유니코드, ISO-8859, ASCII 등
문자열 인코딩
-
문자를 코드로 표현하는 방식
ex) 유니코드라는 문자 집합 을 표현하는 문자열 인코딩은 UTF-8, UTF-16, UTF-32 등이 있다.
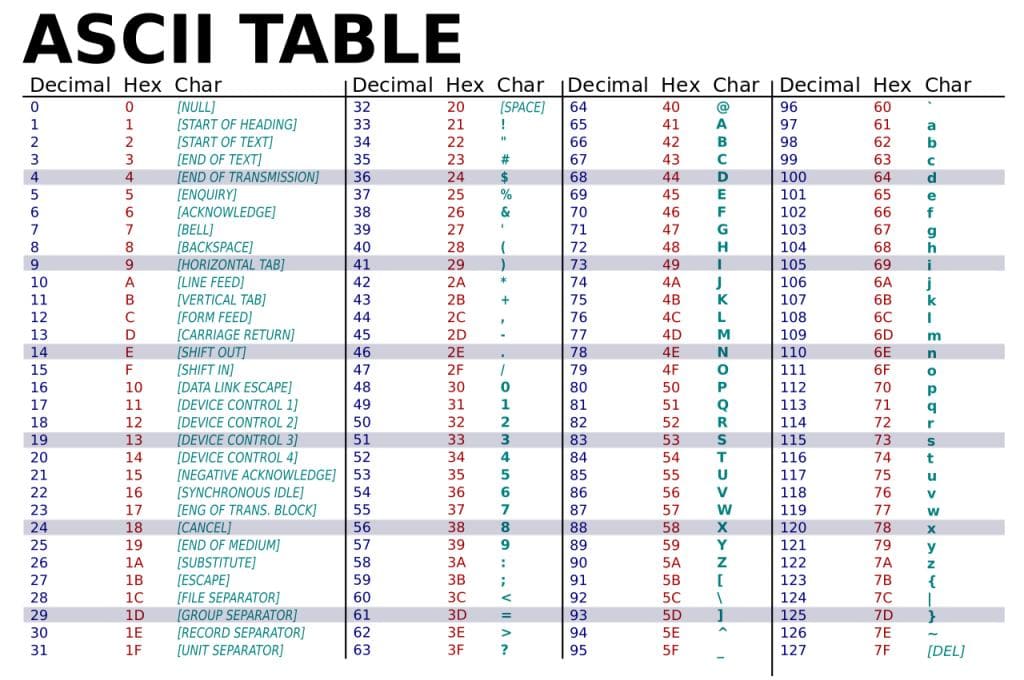
아스키 코드(ASCII)
-
처음으로 표준을 정립한 문자열 인코딩 방식으로 아직도 많이 사용된다.
-
사용할 수 있는 문자의 종류에는
대/소문자, 공백 및 특수 문자들이 있으며
문자를 표현할 때는 0 ~ 127까지
총 128개의 숫자를 사용한다.
-
그림에서 알 수 있듯이
아스키 코드는 영어를 제외한 다른 언어를 표현할 수 없다.
그래서 각 나라에서 아스키코드 대신
독자적인 문자 집합과 인코딩 방식을 만들었다.
-
아스키코드에 대한 자세한 개념은 아스키코드(ASCII Code)을 참고하자.
EUC-KR
-
한국에서는 EUC-KR 문자 집합을 만들었다.
한국어 문자 집합으로
문자 하나를 표현하기 위해 2바이트를 사용한다.
단 아스키코드 문자를 표현할 때는
1바이트를 사용하기 때문에 아스키코드와 호환이 된다.
EUC-KR 특징

2바이트 저장
-
좌측에 있는 코드(b0a0, b0b0 등)를 기준으로
오른쪽으로 한 칸씩 이동할 때마다 1바이트를 더한다.
ex) ‘가’ 문자는 b0a0 코드 줄의 2번째 칸에 있어 1바이트를 더해 b0a1로 표현한다.
b0a1는 0xb0, 0xa1로 나뉘어
총 2바이트를 사용하게 된다.
완성형 코드
-
모든 글자가 완성된 형태로만 존재하는 완성형 코드이다.
따라서 조합해 문자를 만들 수 없으므로 표현할 수 없는 한글이 일부 존재하지만
그 문자는 잘 사용되지 않는다.
지원 언어
-
EUC-KR에는 한글뿐만 아니라
숫자, 특수 기호, 영문, 한문, 일어가 존재한다.
UTF-8, UTF-16
-
유니코드 문자열 인코딩 방식(UTF-8, UTF-16, UTF-32)에 대해서는
유니코드와 UTF-8 / UTF-16 글을 참고하자.