Prologue
- 이번 글 시리즈는 Index에 대해 정리를 해보려 한다.글에서는 Index의 기초에 대해 알아본다.
Basics of Indexing
-
일반적으로 관계형 DB의 인덱스는
B+Tree로 Disk에 저장되고
이로 인해 효율적인 검색이 가능해진다.
(참고 : 관계형 DB의 경우 B-Tree의 변형인 B+Tree를 사용하는 경우가 많다.)
-
인덱스를 설정하는 것은
빠른 쿼리 응답과 업데이트 비용 간의 균형을 적절하게 맞출 필요가 있다.
-
Narrow 인덱스 설정은
(= 적은 수의 컬럼을 사용하는 인덱스)
디스크 공간과 유지 관리 비용을 절약하고
Wide 인덱스는 넓은 범위의 쿼리에 적합하다.
-
가장 간단한 형태의 인덱스는
Binary Search를 사용하여 $O(log_2 N)$ 시간 복잡도로
검색을 수행할 수 있도록 하는 정렬된 테이블이 있다.
Clustered Index
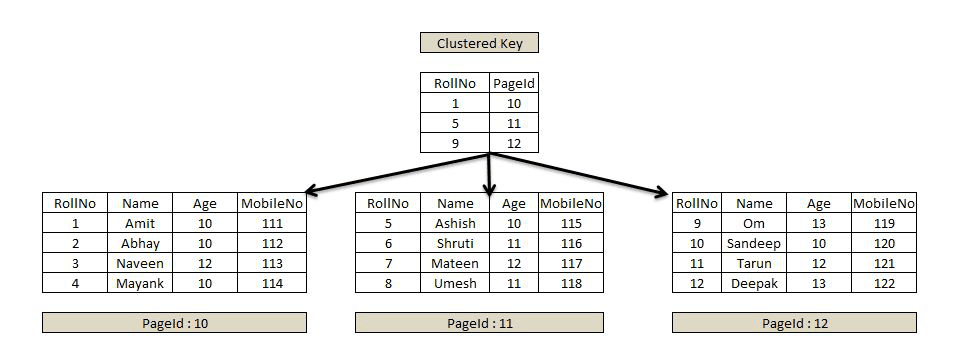
개념 및 특징
-
(일반적으로는) 데이터 저장 시
Random 혹은 요청 순서 등의 방식으로 저장을 하게 되는데
Clustered Index를 사용하는 테이블은 그렇지 않다.
-
Clustered Index를 사용하는 테이블은
Index 순서에 맞춰 Disk에 데이터를 정렬시켜 관리한다.
(= Index와 Disk의 순서를 맞춘다.)
-
이러한 이유로 Clustered Index는 1개만 존재한다.
(Clustered Index가 n개 존재 시 Index와 Disk의 순서를 맞출 수 없다.)
단점
-
Clustered Index를 추가 혹은 변경하면
Disk에도 영향이 끼치므로 시간이 많이 걸릴 수 있다.
Clustered Key
-
정렬 시 기준이 되는 컬럼 혹은 n개의 복합 컬럼을 Clustered Key라 한다.
(= 특정 컬럼을 기준으로 Clustered Index Table을 생성한다.)
-
Key는 Unique하고 Sequential한 컬럼을 선택하는 것이 좋다.
-
대부분 DB에서는
명시적으로 Clustered Index를 정의하지 않으면
PK로 설정된 컬럼을 기준으로 Clustered Index를 생성한다.
예외 - PostgreSQL
-
PostgreSQL와 같은 DB는 위에서 언급한 특성을 따르지 않는다.
-
PostgreSQL는
데이터가 Clustered Index 혹은 다른 Index를 기반으로 정렬되지 않고
추가된 순서대로 저장된다.
-
대신 특정 Index와 일치하도록
Disk의 물리적 데이터를 재정렬하는 데 사용할 수 있는 CLUSTER 명령을 제공한다.
-
하지만 데이터가 추가되거나 변경 시
자동으로 유지되지 않으므로 항상 신뢰하면 안 되고
순서를 유지하려면 지속적으로 CLUSTER 명령을 재실행해야 한다.
이해를 높이는데 도움이 되는 추천 글
Non-clustered Index
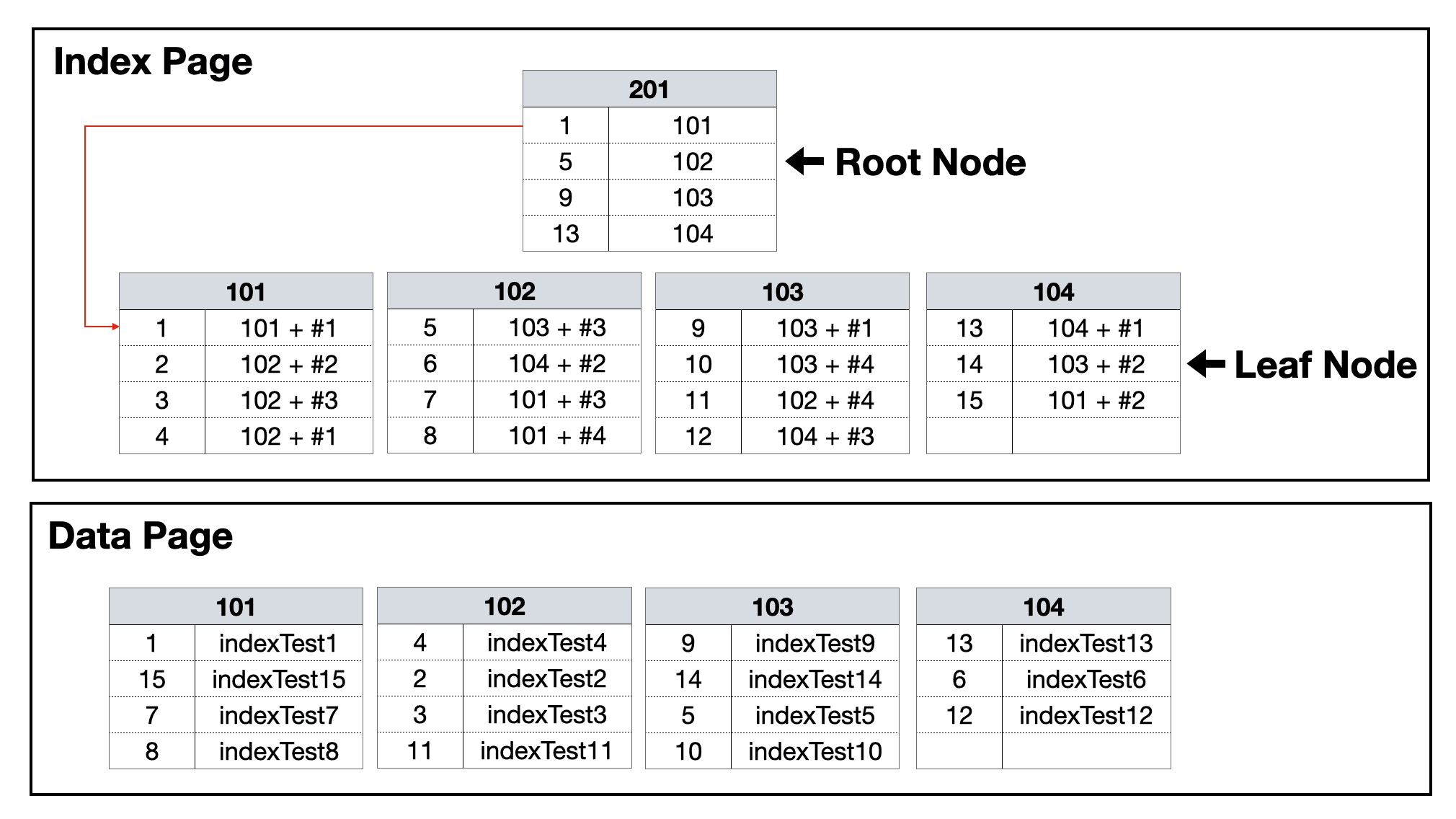
개념 및 비유
-
책 뒷면을 보면 특정 단어가 어떤 페이지에 나오는지 정리해서 볼 수 있다.
Non-clustered Index는 책 뒷면에 있는 Index와 같다.
Index 순서 != Data Page 순서
-
실제로 데이터가 저장되어 있는 Data Page의 순서와
Non-clustered Index의 순서는 같지 않다.
데이터를 찾기 위한 접근 Count
-
Non-clustered Index를 사용하면
실제 데이터에 접근하기 위해선 최소 2번의 Disk 접근이 필요하다.
(만약 Clustered Index였다면 1번의 Disk 접근만으로 실제 데이터 접근이 가능하다.)
1. 찾고자 하는 값의 Data Page 주소를 알기 위한 Index Page 접근 및 탐색
2. Index Leaf Node에서 확인 한 실제 Data Page로 접근
장점
-
물리적으로 Disk 정렬을 하지 않으므로
n개의 Non-clustered Index를 가질 수 있다.
-
그러므로 다양한 유형의 쿼리에 유용하다.
단점
-
Read 속도를 높일 수 있지만
테이블에서 데이터 수정 시
각 Index를 업데이트해야 하므로 Write 속도가 느릴 수 있다.
이해를 높이는데 도움이 되는 추천 글
Summary
-
글이 길어지면 호흡도 길어지고 집중도 떨어지고
부담스러워서 완독하기가 너무 힘들다고 생각하므로
글을 쪼개서 다음 편에는 Index Types에 대해 알아본다.