Prologue
-
저번 글에 이어 Index Type에 대해 알아본다.
-
몇 가지 유형의 Index는 모든 행을 스캔하지 않고도
효율적인 방법을 제공하여 데이터 검색 속도를 높일 수 있다.
Understanding Index Types
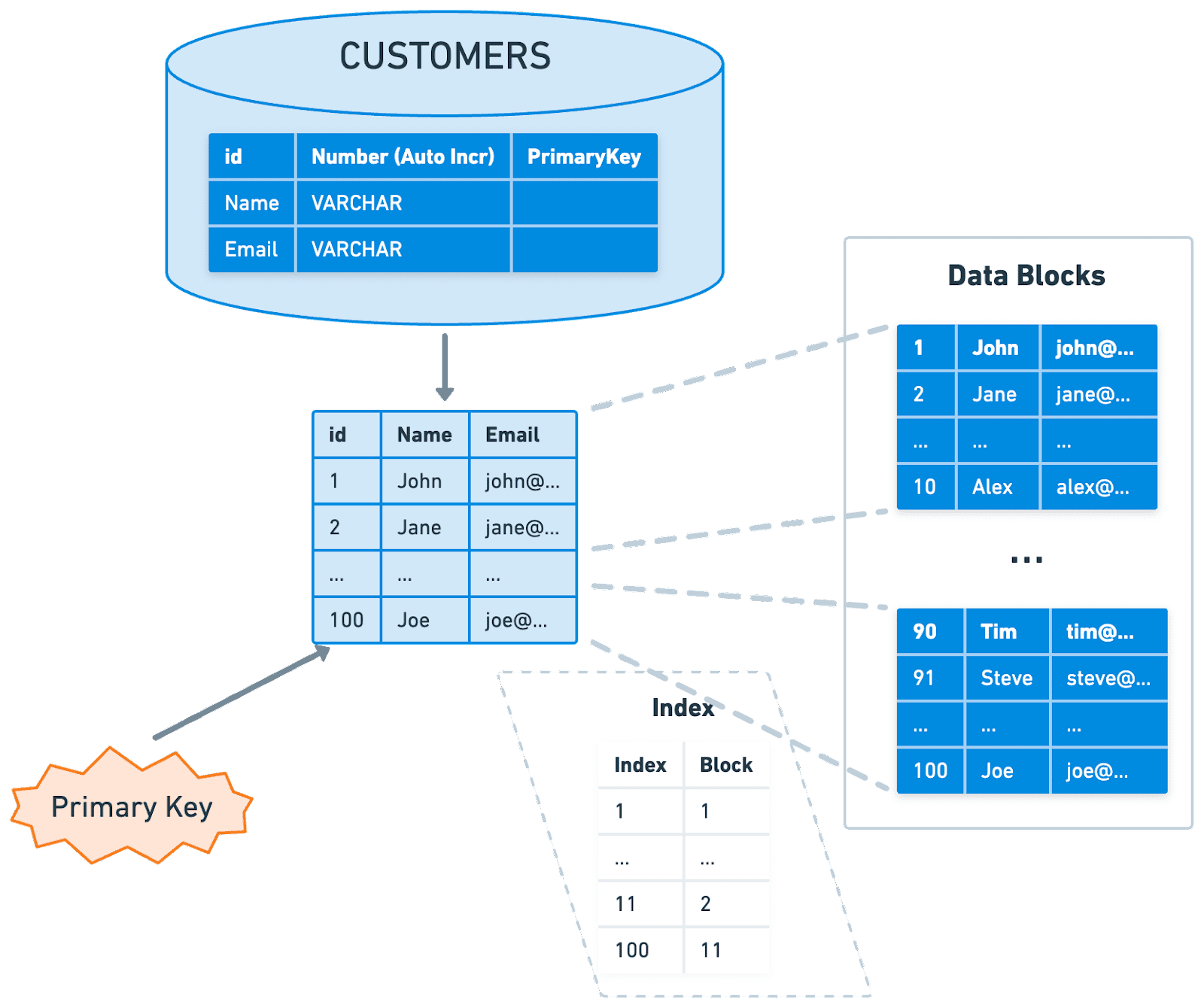
Primary Index
-
Clustered Index에서 이야기했듯이
일반적으로 PK를 기준으로 Clustered Index Table이 생성이 되고
Disk에서의 물리적인 순서 또한 PK를 기준으로 정렬되어 보관된다.
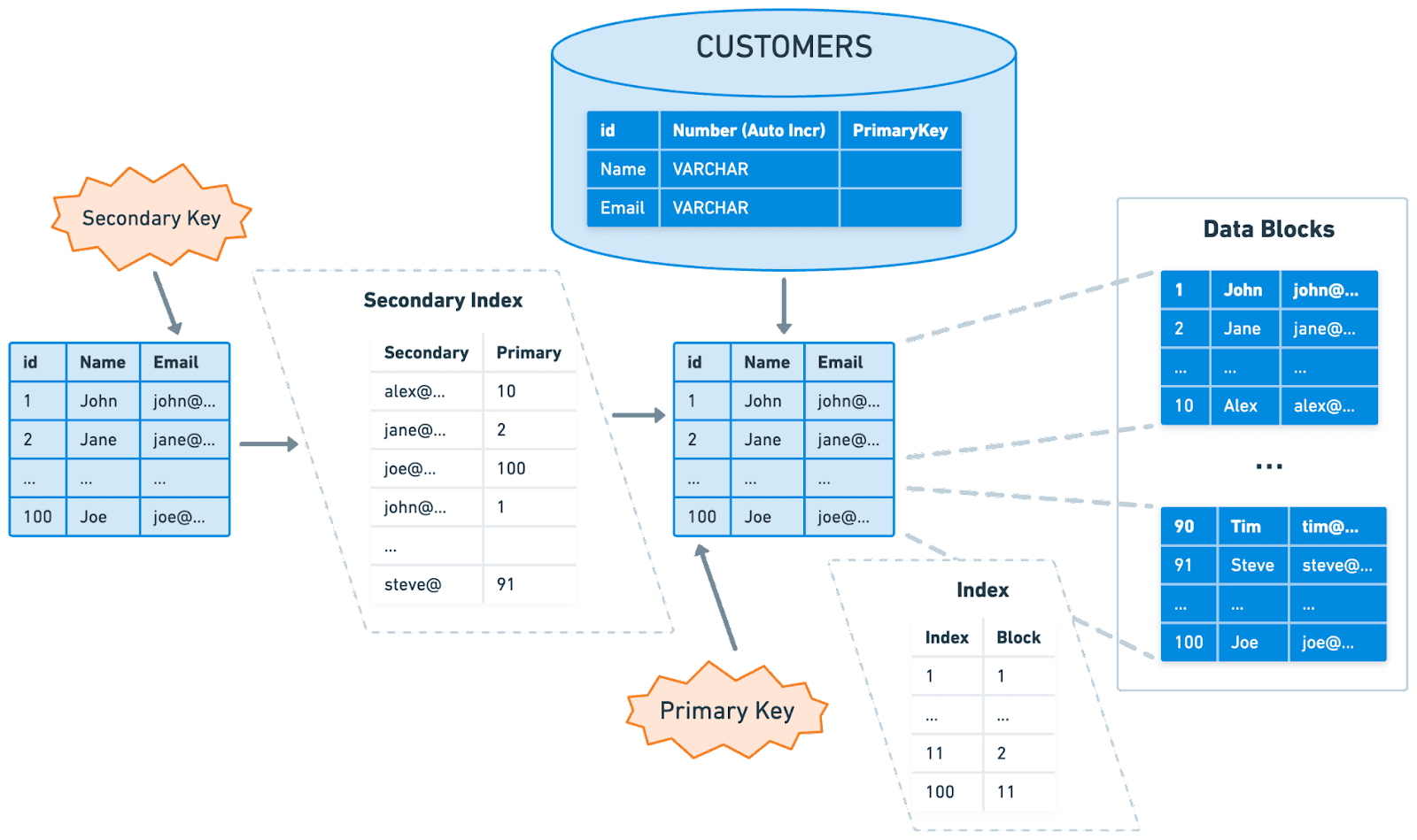
Secondary Index
-
PK가 아닌 특정 컬럼을 기준으로
데이터를 필터링하거나 정렬하는 쿼리에 대해선
Secondary Index를 활용하는 것이 좋다.
-
Secondary Index는 테이블의
물리적인 순서는 건드리지 않고
테이블에서 특정 값의 주소값을 참조하는
Non-clustered Index 형태를 갖게 된다.
언제 사용해야 할까?
- Read가 많은 상황에서는 적절하게 Index를 설정하는 것이 좋다.
단점
- Write 작업 발생 시 해당 데이터를 포함하는 모든 Index를 업데이트해야 하므로 느리다.
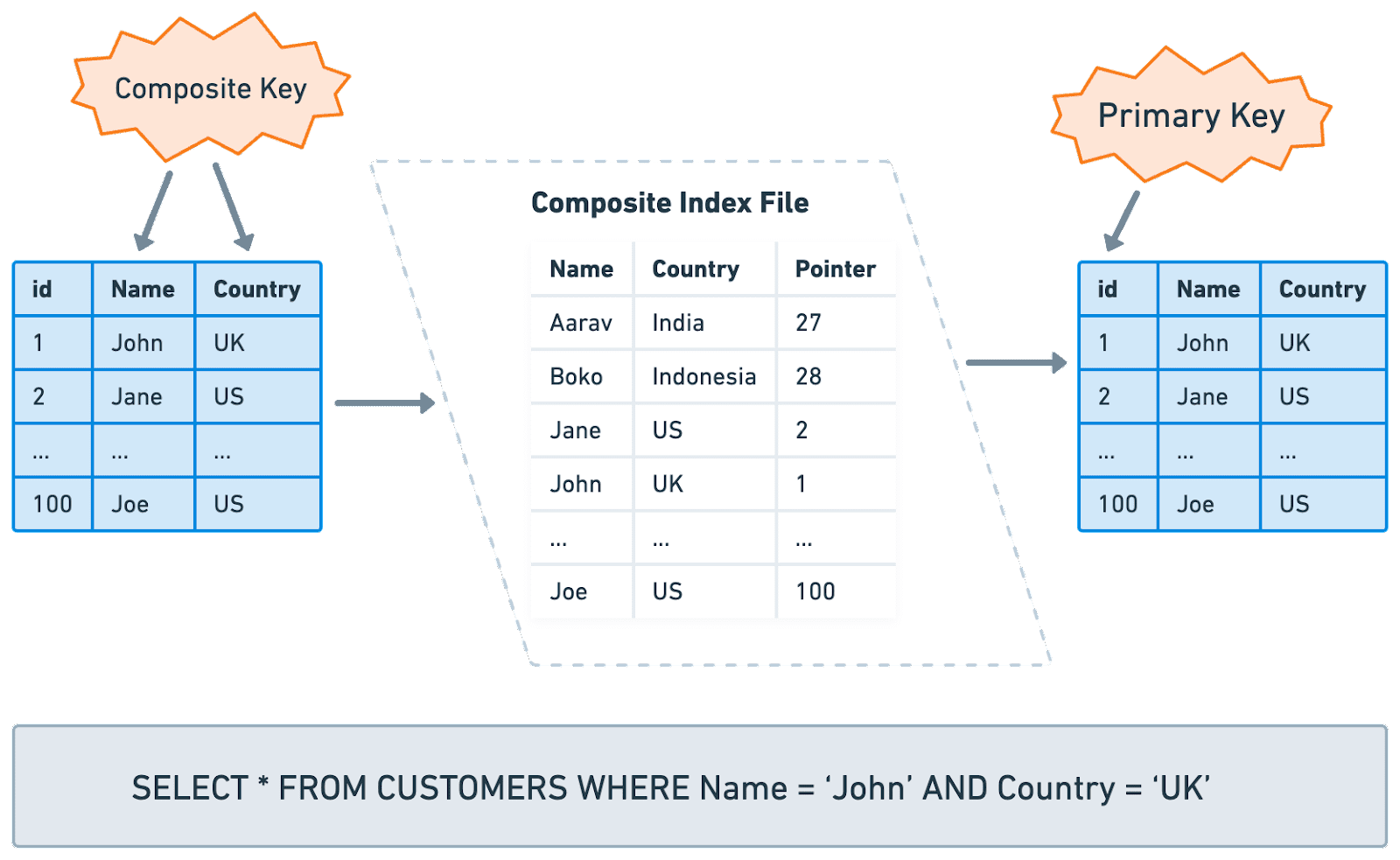
Composite Index
-
2개 이상의 컬럼으로 Index를 설정하면 Composite Index이라 부른다.
-
예를 위 쿼리가 많이 실행한다면
“Name” 과 “Country”를 각각 별도로 Index를 만들기 보단
2개 컬럼을 묶은 Composite Index을 만드는 게 효율적이다.
Index 컬럼 순서
-
Composite Index에서 컬럼 순서는 매우 중요하다.
-
“Name”을 기준으로 정렬이 되어있으므로
“Name”과 “Country”를 모두 포함하는 쿼리와 “name”만 포함하는 쿼리엔 유용하지만
“Country”만 포함하는 쿼리에는 효율적이지 않다.
-
따라서 Composite Index 생성 시
데이터의 범위를 가장 많이 좁힐 수 있는 컬럼이 가장 먼저 오도록 해야 한다.
주의 사항
-
Composite Index에 많은 컬럼을 포함하면 당연히 더 많은 공간을 차지한다.
그러므로 향상된 쿼리 성능의 이점과
저장 공간 사용량 증가에 따른 비용 간의 균형을 찾는 것이 중요하다.
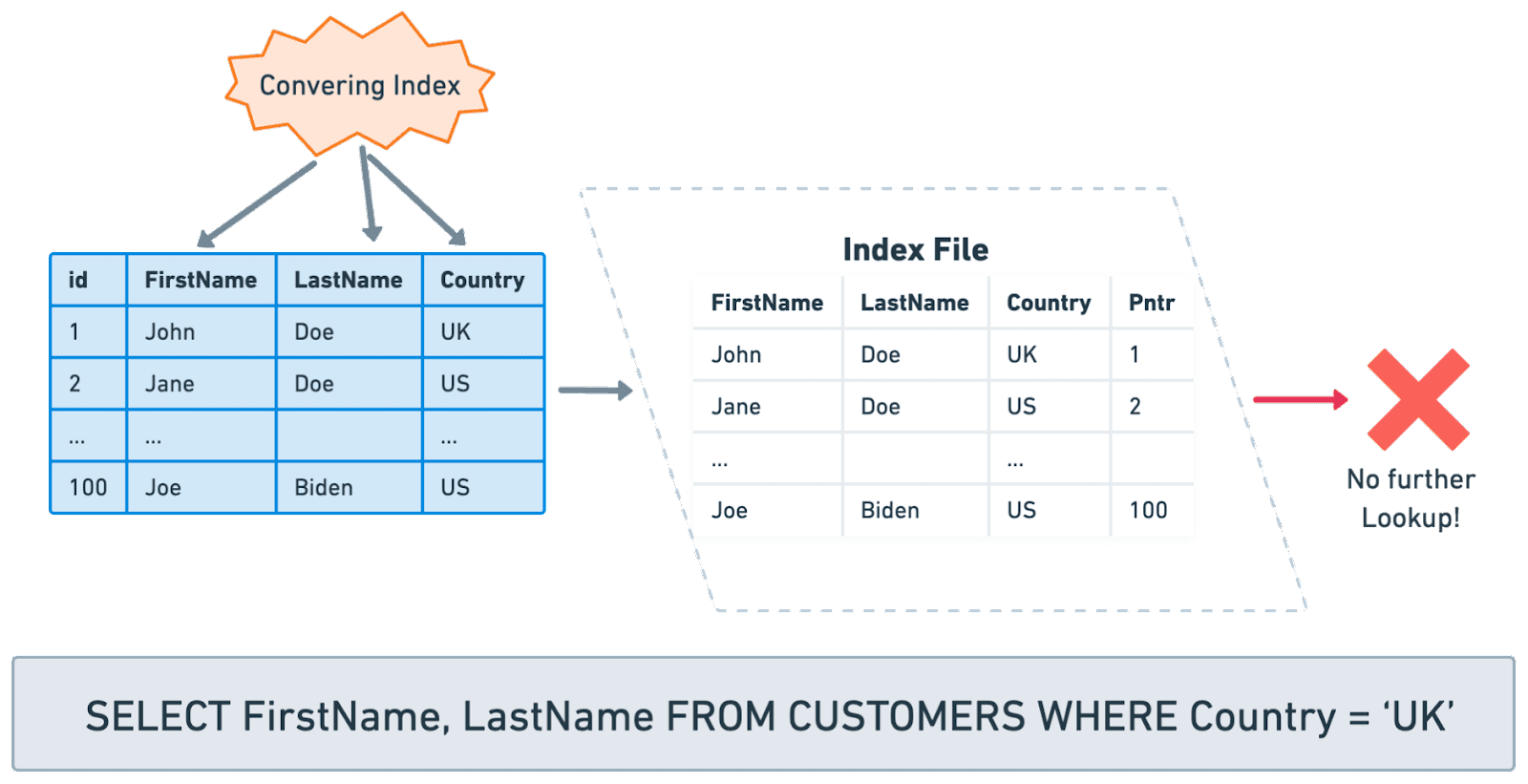
Covering Index
-
Covering Index는 쿼리 성능 최적화를 하는 또 다른 기술이다.
-
만약 Query에서 사용하는 컬럼들이
전부 Covering Index Table에 있다면
굳이 Disk로 접근을 하지 않고 Index Table에서 처리가 가능하다.
이러한 구조의 Index Table을 Covering Index라 부른다.
장점
- Disk I/O 작업을 줄일 수 있다.
단점
- Write 작업 시 부하가 생긴다.
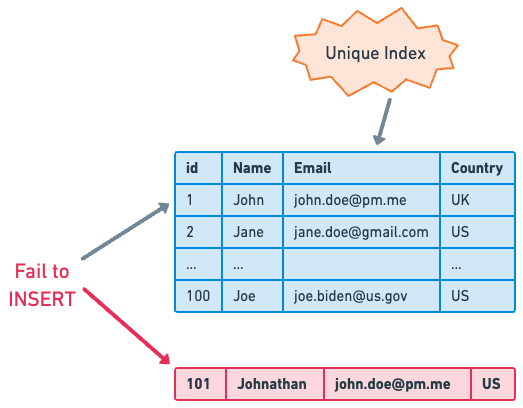
Unique Index
-
이름에서 알 수 있듯이 Index 값의 고유성을 보장해 주는 Index Tool이다.
-
위 사진에서 Email이 Unique Index이므로
새로 추가할 row에 john.doe@pm.me 값은 중복이 되어 추가할 수 없다.
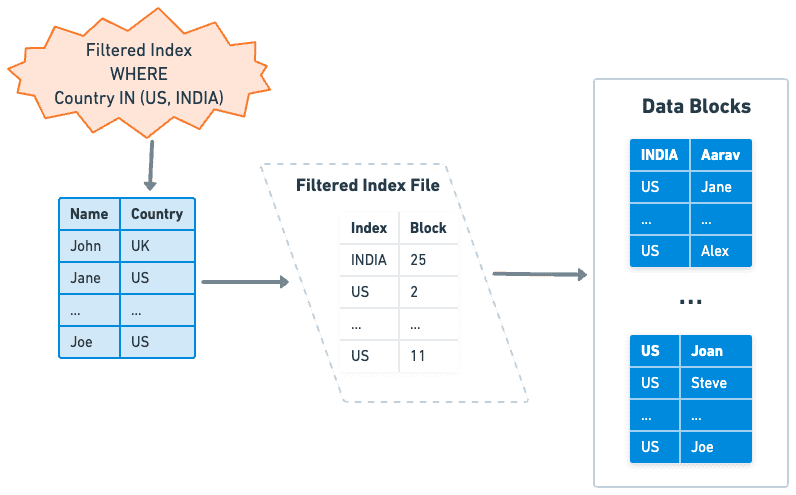
Filtered Index
-
Filtered Index는 일부 DB에서
Partial Index 또는 Conditional Index라고 불리는 특수한 유형의 Index이다.
-
데이터 하위 집합에 필터를 적용하여
특정 범위 또는 값 집합에 대한 인덱스를 생성할 수 있다.
Example
Case 1
-
UK와 INDIA에 대해서만 요청이 많이 들어온다면
UK와 INDIA만 Filtered Index를 생성하여 효율성을 높일 수 있다.
Case 2
-
데이터 타입이 [활성, 비활성, 중지, 일지중지]가 있는데
특정 상태가 ‘활성(Active)’인 값만 검색하는 경우
데이터의 모든 타입에 Index를 생성하는 것보다
상태가 ‘활성’인 행들만을 대상으로
Index를 생성하면 검색 속도가 빨라진다.
한계
-
모든 RDB에서 지원하는 게 아니라 일부에서만 지원한다.
Microsoft SQL Server 및 PostgreSQL은 지원하지만 MySQL은 지원하지 않는다.
Summary
-
글이 길어지면 호흡도 길어지고 집중도 떨어지고
부담스러워서 완독하기가 너무 힘들다고 생각하므로
글을 쪼개서 다음 편에는 Specialized Indexes에 대해 알아본다.