Prologue
-
저번 글에 이어 Specialized Indexes에 대해 알아본다.
-
Specialized Indexes는 단어 뜻 그대로
매우 특별한 상황에 맞춰진 몇 가지 특화된 Index 유형이다.
-
보편적으로 사용할 수는 없지만 특정 상황에서 유용하다.
지금까지 살펴본 Index와 달리
이러한 특수 Index 중 다수는 B+ 트리의 지원을 받지 않는다.
Specialized Indexes
Bitmap Index
-
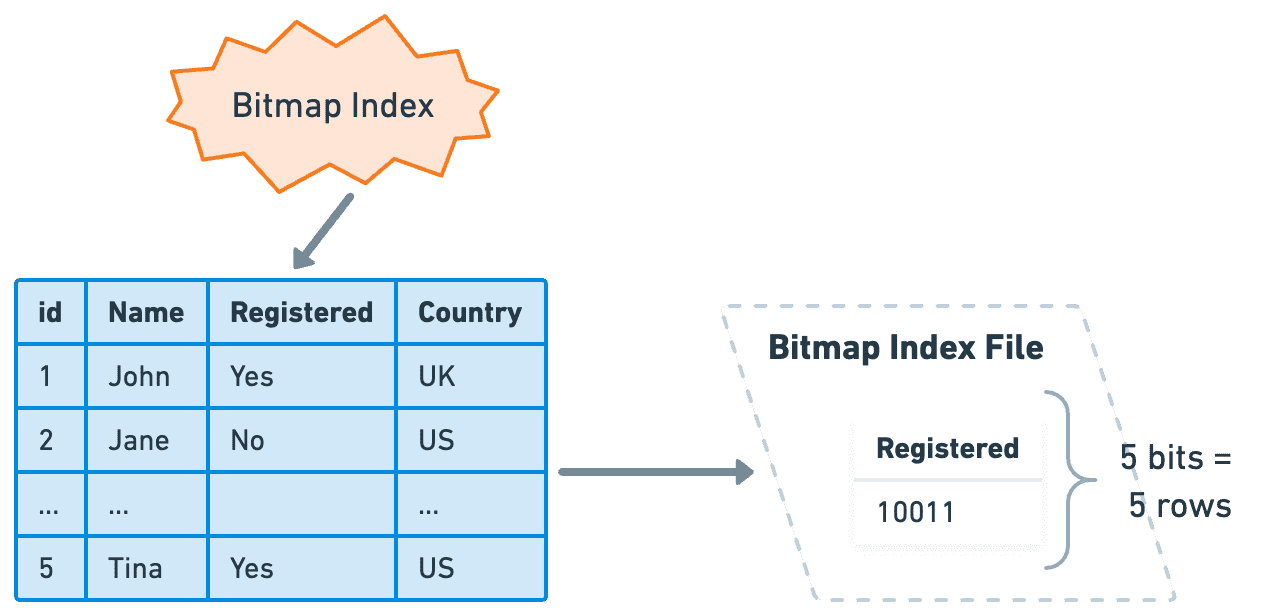
Bitmap Index은 Bitmap을 사용하는 특수한 유형의 DB Index이다.
-
이는 낮은 Cardinality 값이라고도 알려진
제한된 수의 고유 값이 있는 열을 처리할 때 특히 유용하다.
ex) “결혼 상태”, “예/아니요”
Bit Count
-
각 고유 값은 자체 Bitmap을 가지며
여기서 Bit 수는 Row 수랑 동일하다.
만약 Row에 해당 값이 있으면 1로 설정되고 없으면 0으로 설정한다.
장점
-
Bit 연산(AND, OR, NOT 등)을 사용하므로
복잡한 쿼리를 효율적으로 처리할 수 있다.
단점
-
Read 작업에는 빠르고 좋지만
Update 작업을 하려면 Bitmap의 Bit를 변경해야 하므로 Write 작업은 느리다.
-
만약 Bit로 표현해야 하는 유형이 많다면
지속적으로 수정을 해야 하므로
자주 변경되지 않는 정적 데이터 또는 읽기 작업이 많은 데이터에 적합하다.
사용 가능/불가능 DB
-
모든 DB가 Bitmap Index를 지원하지 않는다.
Oracle Database, IBM Db2 및 Microsoft SQL Server은 지원하지만
MySQL 및 PostgreSQL은 지원하지 않는다.
Spatial Index
-
Spatial(=공간) Index는 지리적 좌표, 다각형 또는 3차원 객체와 같은
다차원에 대해 Index 작업을 하는 특수한 유형 중 하나다.
공간과 관련된 쿼리
-
가장 가까운 이웃 검색 또는 범위 검색과 같은
공간과 관련된 쿼리 속도를 높이기 위해 설계되었다.
-
참고로 공간 데이터는 Index가 없다면
데이터 특성상 많은 계산 비용이 든다.
Spatial Index 자료 구조
-
B-tree와 같은 기존 인덱싱 방법은
주로 1차원 데이터를 처리하도록 설계되었기 때문에
공간 데이터를 처리할 때 부족한 경우가 많다.
-
그래서 R-tree나 Quad-tree와 같은 공간 인덱스는
다차원 데이터를 효율적으로 저장하고 검색할 수 있도록 최적화되어 있다.
R-tree
-
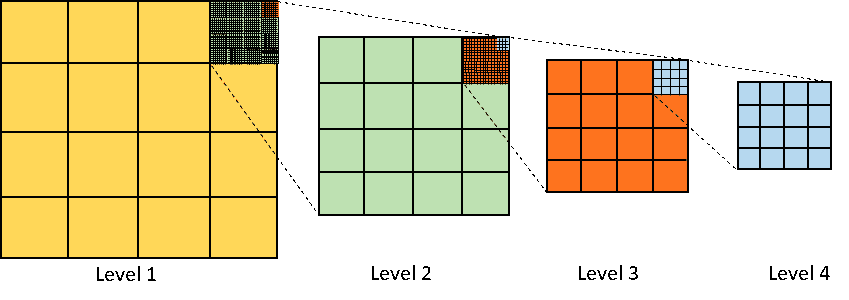
가장 일반적으로 사용되는 R-tree의 내부를 살펴보면
각 노드는 본인이 품고 있는 하위 노드의 모든 데이터를 가진다.
-
같은 Level에서 노드 간 경계는 겹칠 수 있다.
-
Spatial 쿼리 요청이 들어오면
R-tree는 검색하고자 하는 내용이 포함되어 있는
사각형 모양의 박스와 아닌 박스를 구분하여
불필요한 박스는 검색에서 제외시킴으로써
모든 행을 검색하지 않고 효율적으로 처리할 수 있게 한다.
R-tree 사용 예
-
특정 지점 반경 내의 모든 위치 찾기
특정 위치에서 가장 가까운 장소 지점 찾기
사용 가능 DB
-
공간 인덱스는 많은 DB가 지원한다.
ex) MySQL, PostgreSQL(PostGIS 확장 포함), Oracle Database, Microsoft SQL Server
Full-text Index
-
Full-text Index는 Text 타입의 컬럼에 대한
검색을 효율적으로 처리하기 위해 설계되었다.
-
일반적인 Index는 검색하고자 하는 값이
컬럼에 있는 값과 정확하게 일치한 경우에 효과적이지
부분적으로 일치하는지 찾기 위한 검색에는 효과적이지 않다.
-
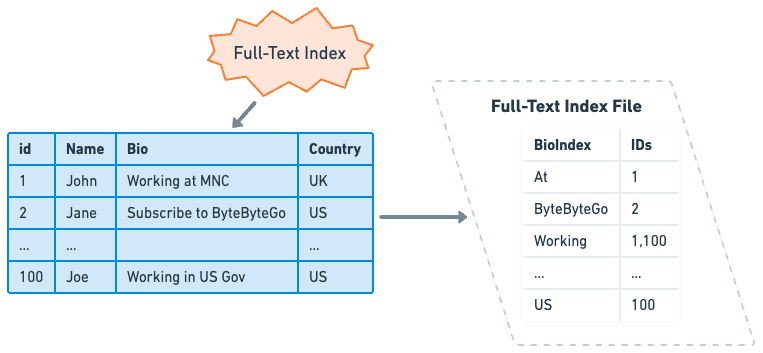
그래서 Full-text Index는
텍스트를 개별 토큰으로 나눈 값과
문서에서 해당 토큰의 위치 정보를 묶어 Index로 생성한다.
Inverted Index
-
Full-text Index는 Inverted Index라는 기술을 사용한다.
-
텍스트 문서 집합에 있는 각 단어들을 키(key)로 사용하고
해당 단어가 나타나는 문서들의 목록을 값(value)으로 가지는 데이터 구조이다.
문서 1: "apple orange banana"
문서 2: "apple peach"
문서 3: "orange peach"
- 위 문서들을 이용하여 Inverted Index를 생성하면 다음과 같다.
apple: 문서 1, 문서 2
orange: 문서 1, 문서 3
banana: 문서 1
peach: 문서 2, 문서 3
-
이렇게 각 단어가 어떤 문서에 등장하는지를 나타내는 Index 만들어 놓으면
검색 시에 해당 단어가 포함된 문서를 빠르게 찾을 수 있다.
-
스키마 관점에서 Inverted Index를 정의하면
페이지 중심 스키마(페이지->단어)를
키워드 중심 스키마(단어->페이지)로 표현하다고 말할 수 있다.
-
그러므로 다양한 단어가 포함된
복잡한 검색 쿼리를 처리하는 특히 효과적이다.
사용 가능한 DB
-
MySQL, PostgreSQL, Oracle Database 및 Microsoft SQL Server와 같은 여러 RDB가 지원한다.
(특정 구문과 기능은 시스템마다 다를 수 있다.)
-
예를 들어 MySQL은 MyISAM 및 InnoDB 스토리지 엔진에서 Full-text Index를 지원한다.
Elasticsearch
- Elasticsearch와 같은 검색에 특화된 엔진에서도 Full-text Index는 중요하다.
Trade Off
-
Full-text Index는 텍스트 검색 성능을 크게 향상시킬 수 있지만
상당한 저장 공간을 소비하고
Insert 및 Update 작업 발생 시 부하가 생긴다는 점을 인지하고 사용해야 한다.
Hash Index
-
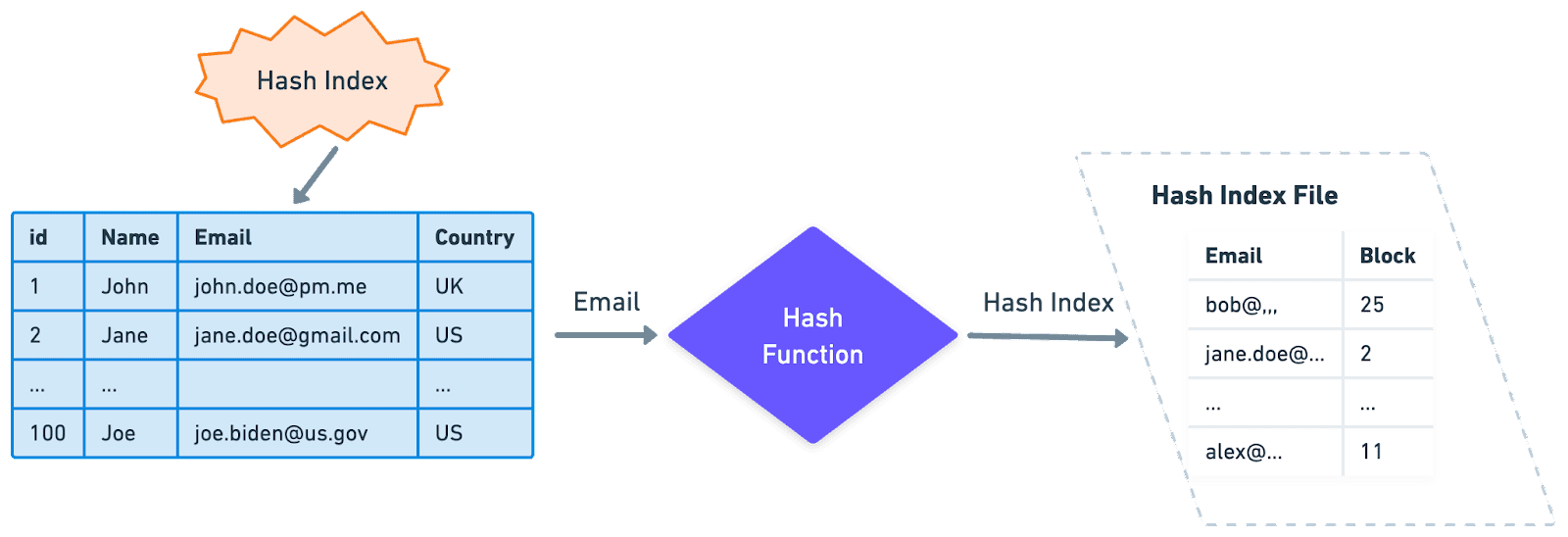
Hash Index는 해시 함수를 사용하여
Key를 Index의 특정 위치에 매핑하여
효율적으로 데이터 검색을 돕는 Index 타입이다.
Hash Index 원리
-
해시 함수는 각 고유 키 값에 대해 고유한 해시 값을 생성하고
그 해시 값은 데이터 레코드에 대한 포인터로 사용된다.
장점
-
순차적 스캔을 수행하거나 B-트리 경로를 따를 필요 없이
DB가 검색 키의 해시를 직접 계산하고
해당 레코드를 즉시 찾을 수 있으므로 검색 작업을 매우 빠르게 처리할 수 있다.
제한 사항
-
범위 기반 쿼리에 적합하지 않다.
-
Hash Index가 키를 정렬된 순서로 저장하지 않기 때문에
”<” 또는 “>”와 같이 키 위치에 의존하는 작업에는 효율적이지 않다.
Summary
-
총 3편에 걸쳐 Index에 대해 알아봤다.
이정도 내용이면 어디가서 Index에 대해 이해하고 있다고 말하는데 부족하진 않을 거 같다.
어렴풋하게 알고 있던 Index 개념에 대해 이번 기회에 제대로 정리해보고
추가로 더 궁금한 개념에 대해서는 공부를 해보는 걸 추천한다.