꾸준함이 실력입니다.
One Two be super Developer-
LeetCode : 3. Longest Substring Without Repeating Characters
3. Longest Substring Without Repeating Characters
Problem
Given a string s, find the length of the longest substring without repeating characters.
-
[3편] DB 인덱스 전략 톺아보기 (Database Indexing Strategies) :: Specialized Indexes
Prologue
-
저번 글에 이어 Specialized Indexes에 대해 알아본다.
-
Specialized Indexes는 단어 뜻 그대로
매우 특별한 상황에 맞춰진 몇 가지 특화된 Index 유형이다.
-
보편적으로 사용할 수는 없지만 특정 상황에서 유용하다.
지금까지 살펴본 Index와 달리
이러한 특수 Index 중 다수는 B+ 트리의 지원을 받지 않는다.
-
-
LeetCode : 57. Insert Interval
57. Insert Interval
Problem
You are given an array of non-overlapping intervals intervals where intervals[i] = [starti, endi] represent the start and the end of the ith interval and intervals is sorted in ascending order by starti. You are also given an interval newInterval = [start, end] that represents the start and end of another interval. Insert newInterval into intervals such that intervals is still sorted in ascending order by starti and intervals still does not have any overlapping intervals (merge overlapping intervals if necessary). Return intervals after the insertion.
-
LeetCode : 542. 01 Matrix
542. 01 Matrix
Problem
Given an m x n binary matrix mat, return the distance of the nearest 0 for each cell. The distance between two adjacent cells is 1.
-
[2편] DB 인덱스 전략 톺아보기 (Database Indexing Strategies) :: Understanding Index Types
Prologue
-
저번 글에 이어 Index Type에 대해 알아본다.
-
몇 가지 유형의 Index는 모든 행을 스캔하지 않고도
효율적인 방법을 제공하여 데이터 검색 속도를 높일 수 있다.
Understanding Index Types
Primary Index
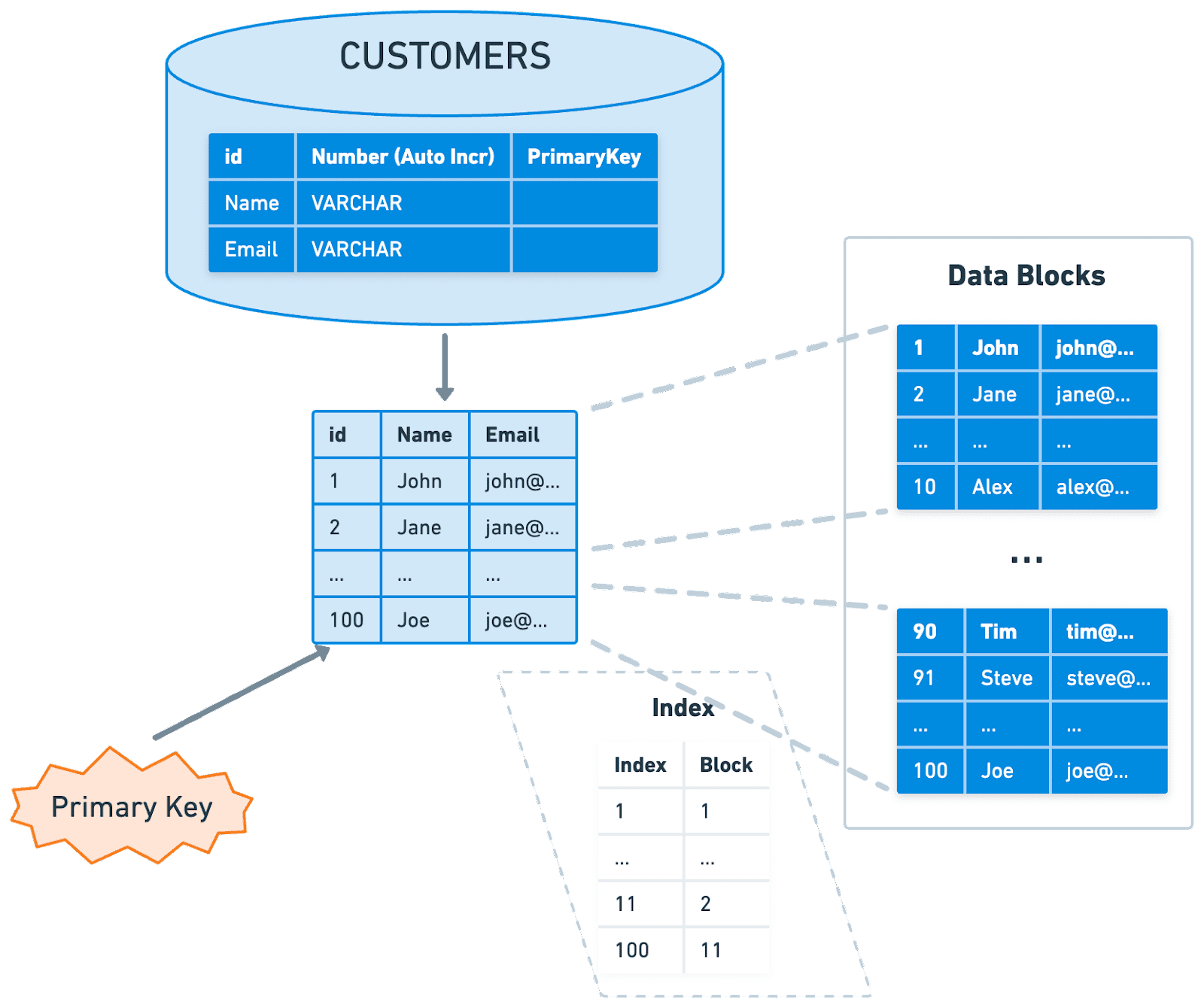
-
Clustered Index에서 이야기했듯이
일반적으로 PK를 기준으로 Clustered Index Table이 생성이 되고
Disk에서의 물리적인 순서 또한 PK를 기준으로 정렬되어 보관된다.
Secondary Index
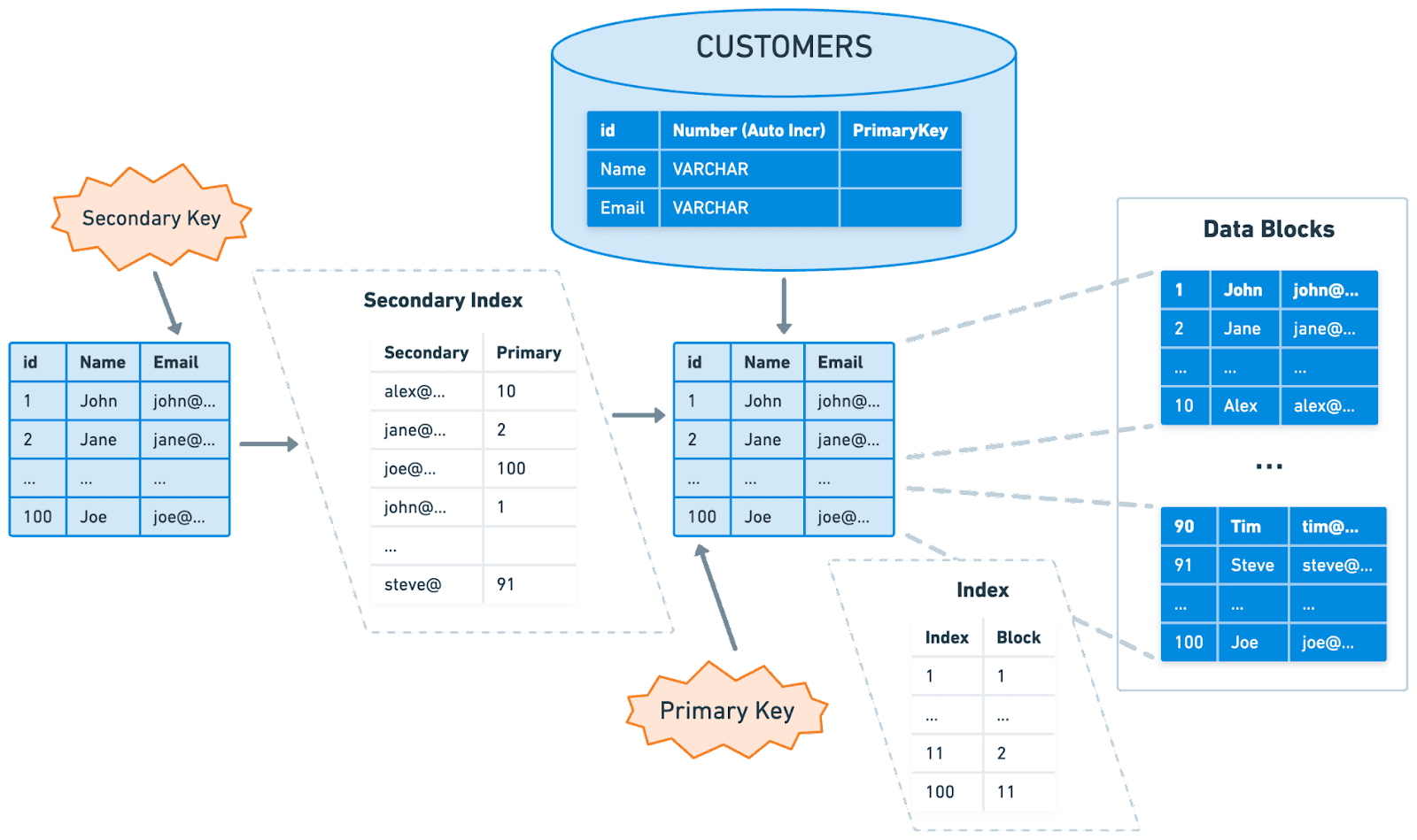
-
PK가 아닌 특정 컬럼을 기준으로
데이터를 필터링하거나 정렬하는 쿼리에 대해선
Secondary Index를 활용하는 것이 좋다.
-
Secondary Index는 테이블의
물리적인 순서는 건드리지 않고
테이블에서 특정 값의 주소값을 참조하는
Non-clustered Index 형태를 갖게 된다.
언제 사용해야 할까?
- Read가 많은 상황에서는 적절하게 Index를 설정하는 것이 좋다.
단점
- Write 작업 발생 시 해당 데이터를 포함하는 모든 Index를 업데이트해야 하므로 느리다.
-
-
[1편] DB 인덱스 전략 톺아보기 (Database Indexing Strategies) :: Basics of Indexing
Recent Posts
- Cursor가 매일 수십억 건의 AI 코드 완성을 처리하는 방식
- A 레코드와 CNAME 레코드는 뭐가 다른걸까?
- 분산 시스템에서 순서가 보장되지 않은 이벤트를 다루는 전략
- DU(Disk Usage) 명령어를 아시나요?
- 2PC(Two-Phase Commit)란 무엇일까?
- DIG(Domain Information Groper) 명령어를 아시나요?
- 샤딩과 파티셔닝, 그 차이에 대하여
- LeetCode : 692. Top K Frequent Words
- Redis 서버에 접속중인 Client 목록 확인 방법
- LeetCode : 1299. Replace Elements with Greatest Element on Right Side
Categories
- Conference 11
- AlgorithmSkill 39
- DB 24
- Algorithm 175
- Crawling 1
- Node.js 15
- Linux 6
- AWS 11
- E.T.C 51
- Competition 5
- Python 26
- BlockChain 36
- MachineLearning 19
- 파일처리 14
- OS 12
- Server 31
- Docker 1
- Web 1
- JavaScript 18
- Network 39
- Git 6
- Technology 64
- DataStructure 1
- C/C++ 1
- HTTP 14
- Java 38
- Redis 9
- Retrospective 7
- Spring 72
- SpringBoot 16
- Kafka 26
- CleanCode 12
- TIL 4
- Blog 7
- Nginx 6
- MyBatis 6
- Regex 4
- EffectiveJava 2
- Spock 1
- Junit5 4
- Intellij 1
- CLI 1
- LeetCode 203
- MySQL 1
- JavaOptimizing 6
- Feign 1
- Karate 2
- Github 8
- SystemDesign 23
- Gradle 3
- Logback 3
- Kotlin 7
- CleanArchitecture 6
- Tech 6