이 글은 책 내용을 토대로 작성하였습니다.
목차
DB를 강력하게 만드는 데이터 구조
-
많은 DB는 내부적으로
추가 전용(Append-Only) 데이터 파일인 로그(Log)를 사용한다.
참고로 여기서 말하는 로그란 연속된 추가 전용 레코드를 뜻한다.
-
일반적으로 DB에서는
특정 키의 값을 효율적으로 찾기 위해 인덱스(Index)를 사용한다.
-
앞으로 다양한 인덱스 구조를 살펴보고
여러 인덱스 구조를 비교하는 방법에 대해 알아본다.
-
인덱스는 저장소 시스템에서 중요한 트레이드오프다.
인덱스를 잘 선택했다면 읽기 속도가 향상되지만
모든 인덱스는 쓰기 속도를 떨어뜨린다.
-
이런 이유로 DB는 자동으로 모든 것을 인덱싱하지 않고
개발자가 수동으로 인덱스 설정을 하도록 한다.
그래야 적은 오버헤드로 최고의 효율을 안겨줄 수 있다.
해시 인덱스
-
단순히 특정 파일에 데이터를 추가하는 방식으로
저장소를 구성한다고 가정할 경우
가장 간단한 인덱싱 전략은 다음과 같다.
-
“키를 데이터 파일의 바이트 오프셋에 매핑해 인메모리 해시 맵을 유지”
그러므로 만약 파일에 새로운 키-값을 추가하면 해시맵도 같이 갱신되어야 한다.
// 여기서 바이트 오프셋이란 값을 바로 찾을 수 있는 위치를 뜻한다.
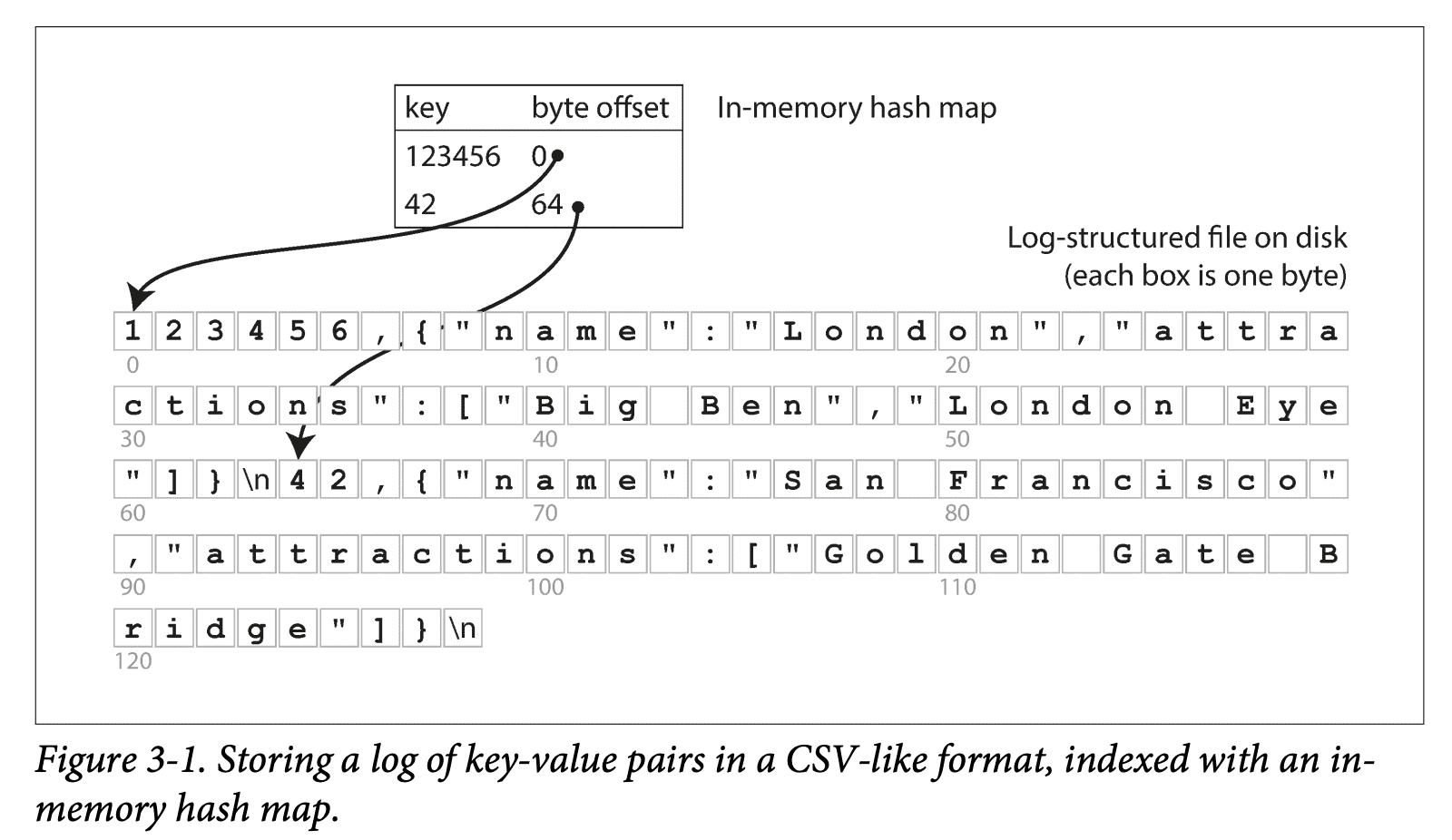
비트캐스크
-
비트캐스크는 이러한 방식을 사용하며
해시 맵을 전부 메모리에 유지하므로
사용 가능한 램(RAM)에 모든 키가 저장된다는 조건을 전제로 고성능 R/W를 보장한다.
-
값은 한 번의 디스크 탐색으로 디스크에서 적재할 수 있으므로
사용 가능한 메모리보다 더 많은 공간을 사용할 수 있다.
-
만약 데이터 파일 일부가
이미 파일 시스템 캐시에 있다면 읽기에 디스크 I/O도 필요 없어진다.
-
비트캐스크 같은 저장소 엔진은
각 키의 값이 자주 갱신되는 상황에 매우 적합하다.
-
예를 들어 “키 = 동영상 URL” / “값 = 비디오 재생 횟수”라면
쓰기는 아주 많지만 고유 키는 그렇게 크지 않다.
즉 키당 쓰기 수가 많지만 메모리에 모든 키를 보관할 수 있다.
세그먼트
-
그런데 지금까지 설명한 것처럼
파일에 항상 추가만 한다면 결국 디스크 공간이 부족해진다.
-
이런 문제를 해결하기 위해
특정 크기의 세그먼트(Segment)로 로그를 나누는 방식을 사용한다.
-
특정 크기에 도달하면 세그먼트 파일을 닫고
새로운 세그먼트 파일에 쓰기를 수행한다.
-
그리고 좀 더 효율적으로 관리하기 위해
로그 파일에서 중복된 키는 버리고
최신의 값만 유지하는 컴팩션(Compaction)을 수행하기도 한다.

-
게다가 컴팩션은 보통 세그먼트를 더 작게 만들기 때문에
컴팩션 수행 시 동시에 여러 세그먼트들을 병할 할 수 있다.
-
세그먼트가 쓰여진 후에는
절대 변경할 수 없으므로 병합할 세그먼트는 새로운 파일로 만든다.
-
고정된 세그먼트의 병합과 컴팩션은
백그라운드 스레드에서 수행할 수 있으므로
컴팩션 과정 중 이전 세그먼트 파일을 사용해
R/W 요청 처리를 정상적으로 수행할 수 있다.
-
병합 과정이 끝난 이후 Read 요청은
이전 세그먼트 대신 새로 병합한 세그먼트를 사용하고
이전 세그먼트 파일을 삭제한다.
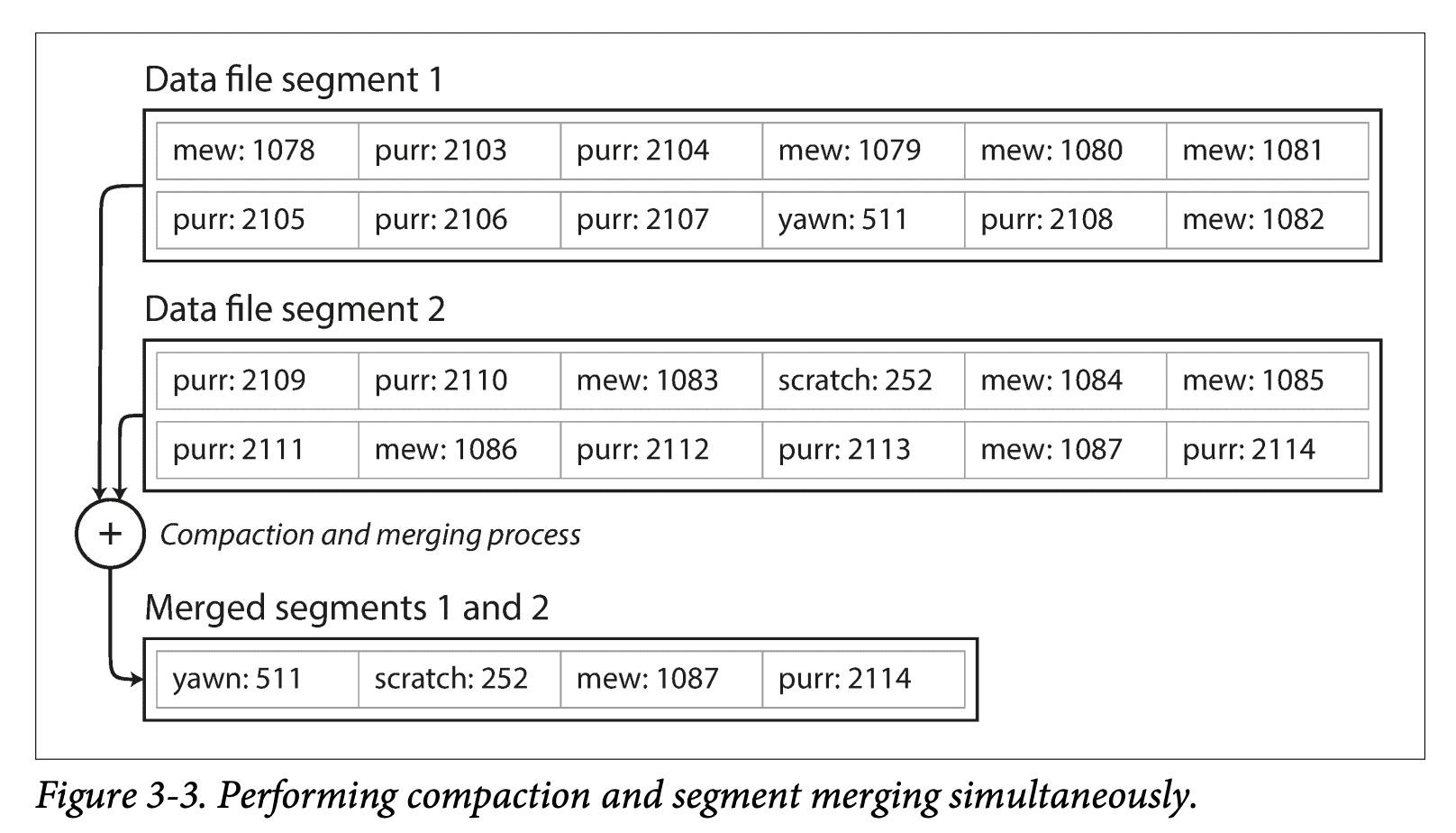
-
이제 각 세그먼트는 키를 파일 오프셋에 매핑한 자체 인메모리 해시 테이블을 갖는다.
그리고 병합 과정을 통해 세그먼트 수를 적게 유지하므로
조회 시 많은 해시 맵을 확인할 필요가 없어진다.
-
그러므로 특정 키 값을 찾으려면
최신 세그먼트 해시 맵을 먼저 확인 후
없다면 두 번째 최신 세그먼트 등을 확인한다.
-
하지만 이런 해시 테이블 전략에도 제한 사항이 존재한다.
제한 사항
-
해시 테이블은 메모리에 저장해야 하므로
키가 너무 많으면 문제가 된다.
-
원친적으로 디스크에 해시 맵을 유지할 수 있지만
불행하게도 디스크 상의 해시 맵에 좋은 성능을 기대하기는 어렵다.
키를 실시간으로 덮어쓰는 게 더 효율적이지 않을까?
-
같은 키에 대해 즉각적으로 덮어쓰는 게 아니라
추가를 하는 방식은 비효율적으로 보일 수 있지만 나름 좋은 설계 방법이다.
추가 방식이 좋은 설계인 이유
-
추가와 세그먼트 병합은 순차적인 쓰기 작업이므로
보통 무작위 쓰기보다 훨씬 빠르다.
-
세그먼트 파일이 추가 전용이나 불변이면
동시성과 고장 복구는 훨씬 간단하다.
-
예를 들어 값을 덮어쓰는 동안 DB가 죽는 경우에 대해 걱정할 필요가 없다.
이전 값 부분과 새로운 값 부분을 포함한 파일을 나누어 함께 남겨두기 때문이다.