이 글은 책 내용을 토대로 작성하였습니다.
목차
SS테이블과 LSM 트리
-
각 로그 구조화 저장소 세그먼트는 키-값 쌍의 연속이며
순차적으로 데이터가 생성되므로 나중의 값이 가장 최신의 값이다.
-
이 점만 제외하면 파일에서 키-값 쌍의 순서는 문제가 되지 않는다.
-
이제 세그먼트 파일의 형식에 간단한 변경 사항 한 가지를 적용해 보자.
변경 요구사항은 일련의 키-값 쌍을 키로 정렬하는 것이다.
순차적으로 로그를 쌓기 때문에 위 요구사항은 불가능할 거 같지만 가능하다.
-
이처럼 키로 정렬된 형식을
정렬된 문자열 테이블(Sorted String Table, SS테이블)이라 부른다.
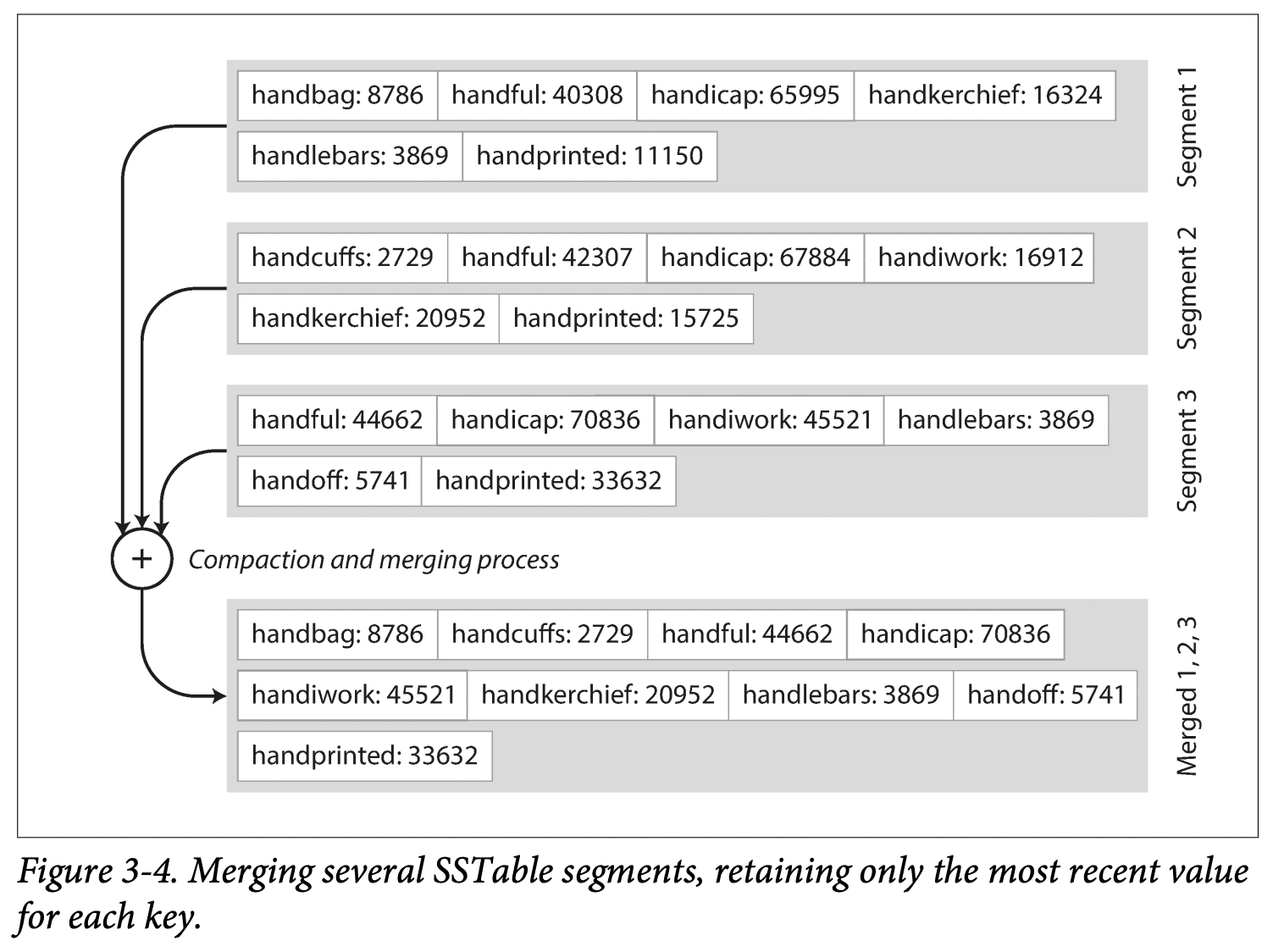
각 키는 병합된 세그먼트 파일 내에 1번만 나타나야 한다.
SS테이블은 해시 인덱싱을 가진 로그 세그먼트보다 몇 가지 큰 장점이 있다.
한마디로 정리하자면 찾고자 하는 키가 존재할 범위를 예상하고
해당 영역에서만 값을 조회하여 찾을 수 있다.
-
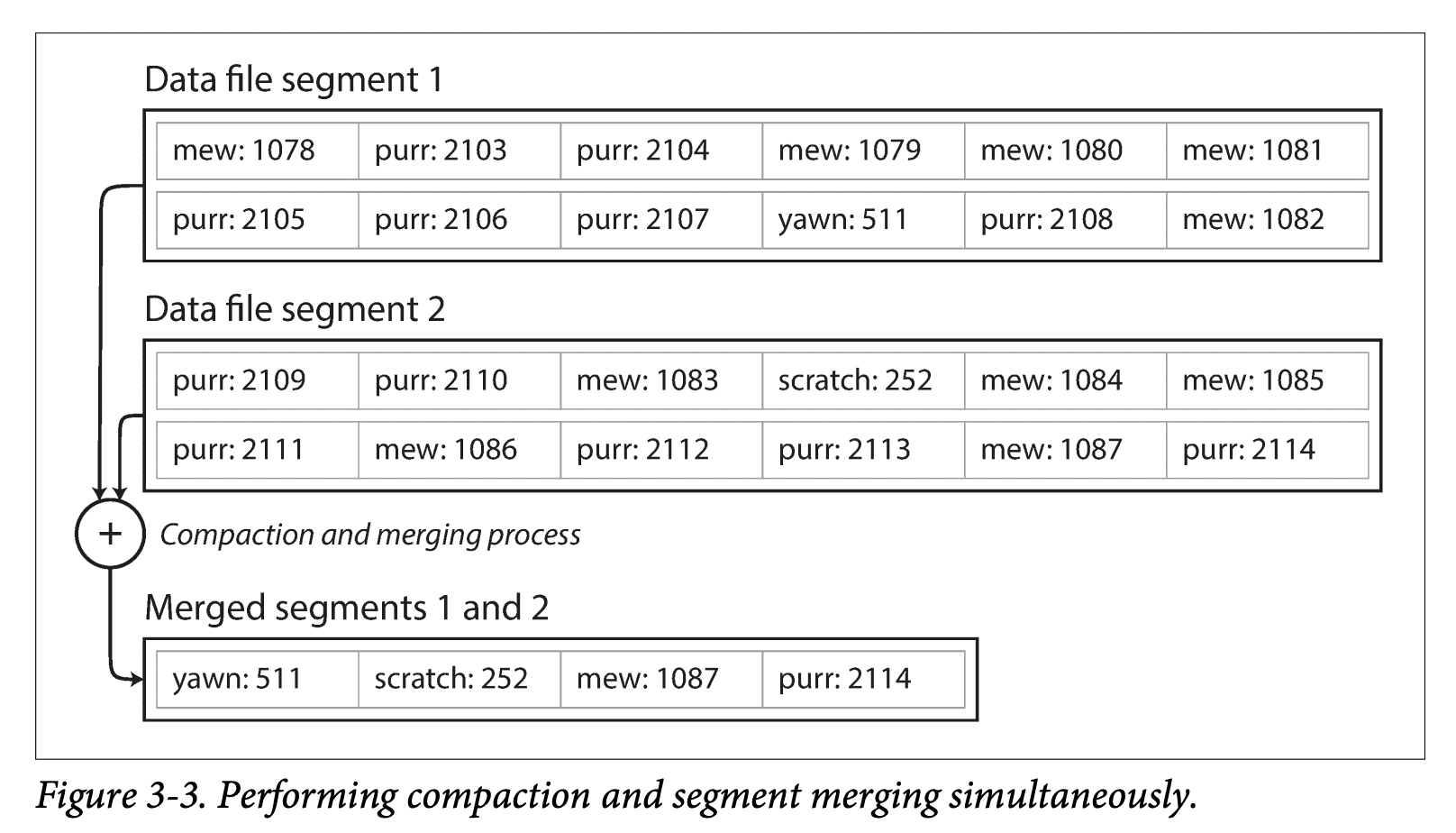
병합 정렬 알고리즘을 사용하여 새로운 세그먼트 파일을 생성한다.
-
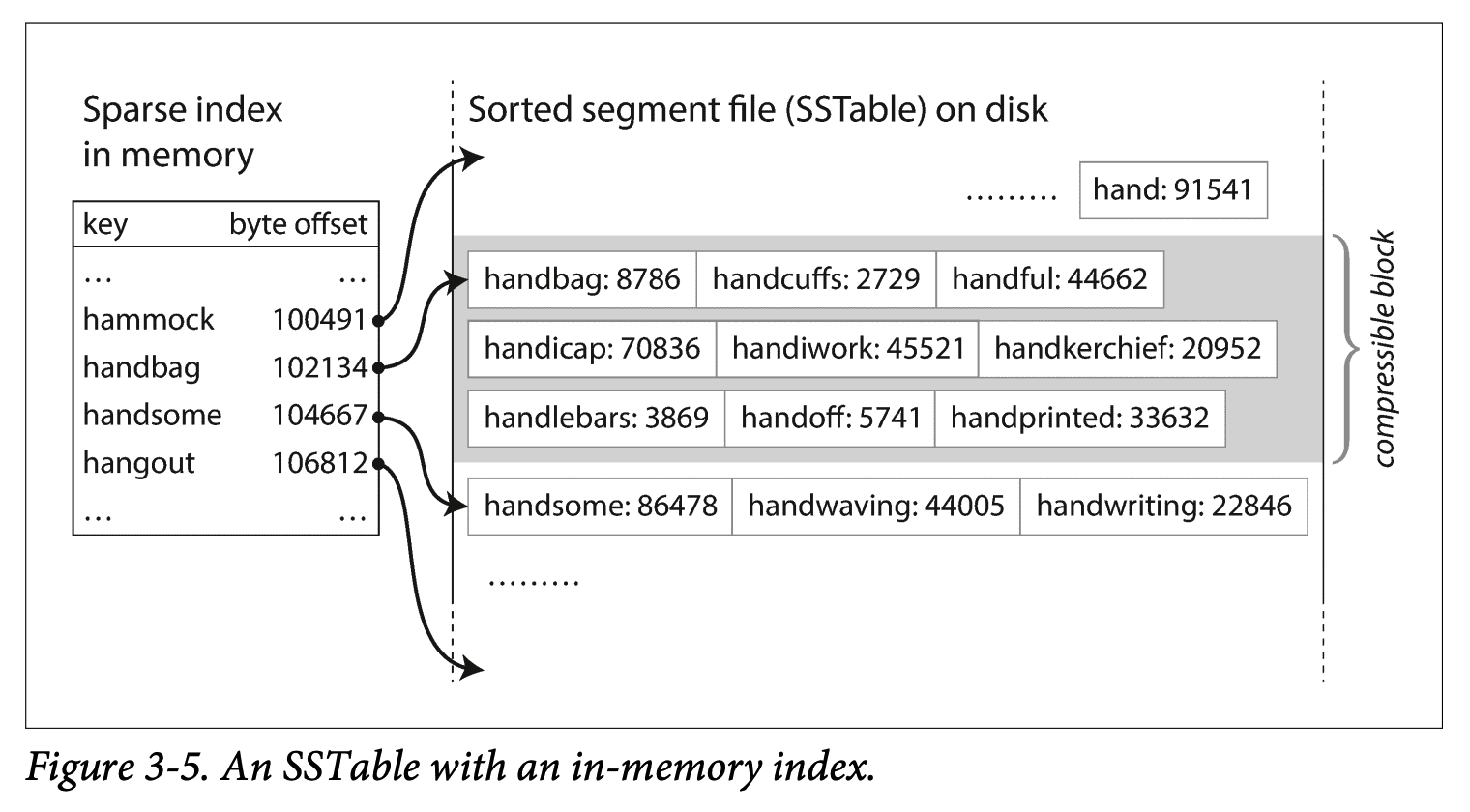
특정 키를 찾기 위해 더이상 모든 키의 인덱스를 관리할 필요가 없다.
-
예를 들어 handiwork 키를 찾으려면
handbag과 handsome 키의 오프셋을 알고 정렬이 이미 되어있으므로
handiwork는 두 키 사이에 있음을 알 수 있다.
-
즉 handbag 오프셋으로 이동해 handiwork가 나올 때까지 스캔하면 된다.
-
물론 일부 키에 대한 오프셋을 알려주는 인덱스 테이블은 여전히 필요하다.
하지만 일부만 관리하면 된다는 장점이 있다.
-
읽기 요청은 요청 범위 내 여러 키-값 쌍을 스캔해야 하므로
해당 레코드들을 블록으로 그룹화하고 디스크에 쓰기 전에 압축한다.
-
그러면 인덱스 테이블에 각 항목은 압축된 블록의 시작을 가리키게 된다.
압축을 함으로써 디스크 공간 절약 + I/O 대역폭 사용 감소라는 장점이 생긴다.
SS테이블 생성과 유지
-
유입되는 쓰기는 임의 순서로 발생하는데
데이터를 키로 정렬하려면 어떻게 해야 할까?
-
디스크 상에 정렬된 구조를 유지하는 일은 가능하지만 (ex. B-tree)
메모리에 유지하는 편이 훨씬 쉽다. (ex. 레드 블랙트리, AVL 트리)
-
이런 데이터 구조를 이용하면
임의 순서로 키를 삽입하더라도 정렬된 상태로 데이터 유지가 가능하다.
-
그러면 저장소 엔진을 다음과 같이 만들 수 있다.
저장소 엔진 동작 순서
-
쓰기 요청이 들어오면 인메모리 균형트리 데이터 구조 (ex. 레드 블랙트리)에 추가한다.
트리가 이미 키로 정렬된 키-값 쌍을 유지하므로 효율적으로 수행할 수 있다.
이런 인메모리 트리는 멤테이블(Memtable)이라고도 한다.
-
새로운 SS테이블 파일은 DB에서 가장 최신 세그먼트가 된다.
SS테이블을 디스크에 기록하는 동안 쓰기는 새로운 멤테이블 인스턴스에 기록한다.
-
읽기 요청을 제공하려면 먼저 멤테이블에서 키를 찾는다.
그 다음 디스크 상의 가장 최신 세그먼트 -> 두 번째 오래된 세그먼트 -> N 번째 세그먼트 순서로 찾는다.
-
그리고 중간중간 백그라운드로 병합과 컴팩션 과정을 수행한다.
문제점
-
만약 DB가 고장 나면
아직 디스크에 기록되지 않고 멤테이블에 있는 가장 최신의 쓰기 작업 데이터는 손실된다.
-
이런 문제를 해결하기 위해
매번 쓰기를 즉시 추가할 수 있게 분리된 로그를 디스크 상에 유지해야 한다.
-
이 로그는 손상 후 멤테이블 복원 시에만 필요하므로
순서가 정렬되지 않아도 문제가 되지 않으며
멤테이블을 SS테이블로 기록하고 나면
디스크에 저장된 데이터를 삭제해버리면 된다.
( SS테이블 = 디스크 상에 정렬된 세그먼트 파일 )
성능 최적화
-
많은 세부 사항이 저장소 엔진의 성능을 높혀준다.
예를 들어 LSM 트리 알고리즘은 DB에 존재하지 않는 키를 찾는 경우 느릴 수 있다.
-
존재하지 않는 키를 찾는 경우
실제로 멤테이블을 확인 후 가장 오래된 세그먼트까지 거슬러 올라가야 하기 때문이다.
-
이런 종류의 접근을 최적화하기 위해 저장소 엔진은
보통 블룸 필터(Bloom Filter)를 추가로 사용한다.
블룸 필터는 키가 DB에 존재하지 않음을 알려줘서 불필요한 디스크 읽기를 절약할 수 있다.
병합 순서 및 시기 전략
- SS테이블을 압축하고 병합하는 순서와 시기를 결정하는 전략도 있다.
크기 계층 (Size Tiered)
-
사이즈 계층 컴팩션은 상대적으로 더 새롭고 작은 SS테이블을
상대적으로 오래됐고 큰 SS테이블에 연이어 병합한다.
( ex. 카산드라, HBase )
레벨 컴팩션 (Level Compaction)
-
레벨 컴팩션은 키 범위를 더 작은 SS테이블로 나누고
오래된 데이터는 개별 레벨로 이동하므로
컴팩션을 점진적으로 진행해 디스크 공간을 덜 사용한다.
( ex. 카산드라, 레벨DB, 록스DB )