이 글은 책 내용을 토대로 작성하였습니다.
목차
Goal
- 파티셔닝 글 시리즈에서는 다음과 같은 부분들을 살펴본다.
-
대용량 데이터셋을 파티셔닝하는 방법
-
인덱싱과 파티셔닝의 상호작용 방법
-
클러스터에 노드 추가/삭제 시 재균형화 과정
-
DB가 어떻게 요청을 올바른 파티션에 전달 및 질의를 하는지 그 실행 과정에 대학 학습
파티션 재균형화
- 운영을 하다 보면 DB에 변화가 생긴다.
질의 처리량이 증가해서 늘어난 부하를 처리하기 위해 CPU를 추가하고 싶다.
데이터셋 크기가 증가해서 데이터셋 저장에 사용할 디스크와 램을 추가하고 싶다.
장비에 장애가 발생해서 그 장비가 담당하던 역할을 다른 장비가 넘겨받아야 한다.
-
이런 변화가 생기면 데이터와 요청이 한 노드에서 다른 노드로 옮겨져야 한다.
클러스터에서 한 노드가 담당하던 부하를 다른 노드로 옮기는 과정을 재균형화(Rebalancing)라고 한다.
재균형화 최소 조건
-
재균형화 후 부하가 클러스터 내에 있는 노드들 사이에 균등하게 분배돼야 한다.
-
재균형화 도중에도 DB는 R/W 요청을 받아들여야 한다.
-
재균형화가 빨리 실행되고 네트워크와 디스크 I/O 부하를 최소화할 수 있도록
노드들 사이에 데이터가 필요 이상으로 옮겨져서는 안 된다.
재균형화 전략
해시값에 모드 N 연산
-
해시값에 모드 N 연산을 사용하여
그 나머지 값을 활용해 파티션을 노드에 할당하는 방법은 사용해선 안 된다.
-
모드 N 방식의 문제는
노드 개수 N이 바뀌면 대부분 키가 노드 사이에 옮겨져야 한다는 점이다.
-
예를 들어 hash(key) = 123456이라고 하자.
처음에 노드가 10대라면 이 키는 노드 6에 할당된다.
( 123456 % 10 = 6 )
-
노드가 11대로 늘어나면 이 키는 노드 3으로 옮겨져야 하고
( 123456 % 11 = 3 )
노드가 12대로 늘어나면 이 키는 노드 0으로 옮겨져야 한다.
( 123456 % 12 = 0 )
-
이렇게 키가 자주 이동하면 재균형화 비용이 지나치게 커진다.
즉 데이터를 필요 이상으로 이동하지 않는 방법이 필요하다.
파티션 개수 고정
-
다행스럽게도 간단한 해결책이 있다.
파티션을 노드 대수보다 많이 만들고
각 노드에 여러 파티션을 할당하는 것이다.
-
예를 들어 노드 10대로 구성된 클러스터에서 실행되는 DB는
처음부터 파티션을 1,000개로 쪼개서
각 노드마다 약 100개의 파티션을 할당할 수 있다.
-
이런 재균형화 방법은 리악, 엘라스틱서치, 카우치베이스, 볼드모트에서 사용된다.
클러스터에 노드 추가/제거 시
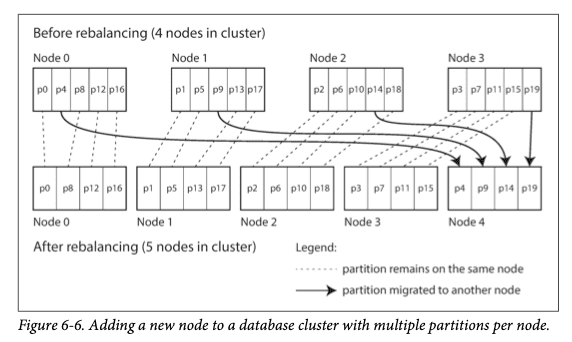
-
클러스터에 노드가 추가되면
새 노드는 파티션이 다시 균일하게 분배될 때까지
기존 노드에서 파티션 몇 개를 뺏어올 수 있다.
-
노드가 제거되면 이 과정이 반대로 실행된다.
-
파티션은 노드 사이에서 통째로 이동하기만 한다.
파티션 개수는 바뀌지 않고 파티션에 할당된 키도 변경되지 않는다.
-
유일한 변화는 노드에 어떤 파티션이 할당되는가 뿐이다.
-
파티션 할당 변경은 즉시 반영되지 않고
네트워크를 통해 대량의 데이터를 전송해야 하므로 시간이 걸린다.
따라서 데이터 전송이 진행 중인 동안에 R/W 요청은 기존에 할당된 파티션을 사용한다.
주의할 점
-
이 방식을 사용할 때는
보통 DB가 처음 구축될 때
파티션 개수가 고정되고 이후에 변하지 않음을 가정한다.
-
이론적으로는 파티션을 쪼개거나 합치는 게 가능하지만
파티션 개수가 고정되면 운영이 단순해지므로
고정 파티션을 사용하는 DB는 파티션 분할을 지원하지 않는 경우가 많다.
-
따라서 처음 설정된 파티션 개수가
사용 가능한 노드 대수의 최대치가 되므로
미래에 증가할 것을 예상하여 적당한 값으로 선택해야 한다.
-
그러나 개별 파티션도 관리 오버헤드가 있으므로
너무 큰 수를 선택하면 역효과를 낳을 수 있다.
정리
-
전체 데이터셋의 크기 변동이 심하다면 적절한 파티션 개수를 정하기 어렵다.
-
예를 들어 처음에는 데이터셋이 작지만 시간이 지나면서 훨씬 커질 수 있다.
-
각 파티션에는 전체 데이터의 고정된 비율이 포함되므로
개별 파티션 크기는 클러스터의 전체 데이터 크기에 비례해서 증가한다.
파티션이 너무 크면 재균형화를 실행할 때와 노드 장애로부터 복구할 때 비용이 크다.
-
그러나 파티션이 너무 작으면 오버헤드가 너무 커진다.
파티션 크기가 너무 크지도 너무 작지도 않고 적당해야 성능이 가장 좋지만
파티션 개수는 고정돼 있고 데이터셋 크기는 변한다면 적절한 크기를 정하기 어려울 수 있다.
동적 파티셔닝
-
키 범위 파티셔닝을 사용하는 DB에서는
파티션 경계와 개수가 고정돼 있으면 매우 불편하다.
-
왜냐하면 파티션 경계를 잘못 지정하면
모든 데이터가 한 파티션에 저장되고 나머지 파티션은 빌 수도 있기 때문이다.
-
이런 이유로 HBase처럼 키 범위 파티셔닝을 사용하는 DB에서는
파티션을 동적으로 만든다.
동적 파티셔닝 동작 과정
-
파티션 크기가 설정된 값을 넘어서면
파티션을 2개로 쪼개고
기존 파티션이 가진 데이터도 절반씩 나눠 갖게 한다.
-
반대로 데이터가 많이 삭제되어 파티션 크기가 임곗값 아래로 떨어지면
인접한 파티션과 합쳐질 수 있다.
노드와 파티션간의 관계
-
파티션 개수가 고정된 경우와 마찬가지로
각 파티션은 노드 하나에 할당되고
각 노드는 여러 파티션을 담당할 수 있다.
-
큰 파티션이 쪼개진 후 부하의 균형을 맞추기 위해
분할된 파티션 중 하나가 다른 노드로 이동될 수 있다.
-
HBase의 경우 기분 분산 파일 시스템인 HDFS를 통해 파티션 파일이 전송된다.
장점
-
동적 파티셔닝은 파티션 개수가 전체 데이터 용량에 맞춰 조정된다는 이점이 있다.
데이터양이 적으면 파티션 개수가 적어도 되므로 오버헤드도 작다.
데이터 양이 많아지면 개별 파티션의 크기는 설정된 최대치로 제한된다.
함정
-
데이터가 비어있는 DB는 파티션 경계를 어디로 정해야 하는지에 관한 사전 정보가 없으므로
시작할 때는 파티션이 1개라는 함정이 있다.
-
데이터 셋이 작아서
첫 번째 파티션이 분할될 정도로 데이터가 쌓이기 전까지는
모든 쓰기 요청이 하나의 노드에서 실행되고 다른 노드들은 유휴 상태에 머물게 된다.
-
이런 문제를 해결하기 위해
HBase와 몽고DB에서는 빈 DB에
초기 파티션 집합을 설정할 수 있는 기능을 제공하고
이러한 개념을 사전 분할(Pre-Splitting)이라고 부른다.
참고
-
동적 파티셔닝은 키 범위 파티셔닝에만 적합한 것은 아니고
해시 파티셔닝에도 똑같이 사용될 수 있다.
-
몽고DB는 2.4 버전부터 키 범위 파티셔닝과 해시 파티셔닝을 모두 지원하고
두 경우 모두 파티션을 동적으로 나눈다.
노드 비례 파티셔닝
-
동적 파티셔닝에서는 파티션 분할과 병합을 통해
개별 파티션 크기가 어떤 고정된 최솟값과 최댓값 사이에 유지되게 하므로
파티션 개수가 데이터셋 크기에 비례한다.
-
반면 파티션 개수를 고정하면 개별 파티션의 크기가 데이터셋 크기에 비례한다.
(= 데이터가 많아지면 해당 파티션의 크기는 커진다.)
두 경우 모두 파티션 개수는 노드 대수와 독립적이다.
파티션과 노드 대수의 관계
-
파티션 개수가 노드 대수에 비례하게 한다.
즉 노드당 할당되는 파티션 개수를 고정한다.
-
이 경우 노드 대수가 변함없는 동안은
개별 파티션 크기가 데이터셋 크기에 비례해서 증가하지만
노드 대수를 늘리면 파티션 크기는 다시 작아진다.
-
일반적으로 데이터 용량이 클수록 데이터를 저장할 노드도 많이 필요하므로
이 방법을 쓰면 개별 파티션 크기도 상당히 안정적으로 유지된다.
새 노드가 클러스터에 추가될 경우
-
새 노드가 클러스터에 추가되면
고정된 개수의 파티션을 무작위로 선택해 분할하여
절반은 그대로 두고 다른 절반은 새 노드에 할당한다.
-
파티션을 랜덤으로 선택해 균등하지 않은 분할이 생길 수 있지만
여러 파티션에 대해 평균적으로 보면
새 노드는 기존 노드들이 담당하던 부하에서 균등한 몫을 할당받게 된다.
// 카산드라 3.0에는 불균등한 분할을 회피할 수 있는 대안적인 재균형화 알고리즘이 추가됐다.
운영 관점
자동 vs 수동 재균형화
-
재균형화는 자동으로 실행될까? 아니면 수동으로 실행해야 할까?
-
완전 자동 재균형화와 완전 수동 재균형화 사이에는 중간 지점이 있다.
-
예를 들어 카우치베이스, 리악, 볼드모트는
자동으로 파티션 할당을 제안하지만 반영되려면 관리자가 확정해야 한다.
완전 자동 재균형화
-
완전 자동 재균형화는 일상적인 유지보수에 손이 덜 가므로 편리할 수 있다.
하지만 예측하기 어렵다.
-
재균형화는 요청 경로를 재설정해야 하고
대량의 데이터를 노드 사이에 이동해야 하므로 비용이 큰 연산이다.
-
주의 깊게 처리하지 않으면 네트워크나 노드에 과부하가 걸릴 수 있고
재균형화가 진행 중인 동안에 실행되는 다른 요청의 성능이 저하될 수 있다.
최악의 상황
-
이런 자동화는 자동 장애 감지와 조합되면 위험해질 수도 있다.
-
예를 들어 1대 노드에 과부하가 걸려
일시적으로 요청에 대한 응답이 느려졌다고 하자.
-
다른 노드들은 과부하 걸린 노드가 죽었다고 간주하고
해당 노드로부터 부하를 다른 곳으로 옮기기 위해
자동으로 클러스터를 재균형화하려고 한다.
-
그러면 과부하 걸린 노드 + 다른 노드들 + 네트워크에 부하를 더해서
상황이 더 안 좋아지고 연쇄 장애가 발생할 가능성도 있다.
책 글쓴이의 생각
-
이런 이유로 재균형화 과정에서 사람이 개입하는 게 좋을 수 있다.
-
완전 자동 처리보다는 느릴 수 있지만
운영상 예상치 못한 일을 방지하는 데 도움이 될 수 있기 때문이다.