이 글은 책 내용을 토대로 작성하였습니다.
목차
Goal
- 파티셔닝 글 시리즈에서는 다음과 같은 부분들을 살펴본다.
-
대용량 데이터셋을 파티셔닝하는 방법
-
인덱싱과 파티셔닝의 상호작용 방법
-
클러스터에 노드 추가/삭제 시 재균형화 과정
-
DB가 어떻게 요청을 올바른 파티션에 전달 및 질의를 하는지 그 실행 과정에 대학 학습
파티셔닝과 보조 인덱스
-
이전 글에서 다룬 파티셔닝 방식은 키-값 데이터 모델에 의존한다.
레코드를 기본키를 통해서만 접근한다면 키로부터 파티션을 결정하고
이를 사용해 해당 키를 담당하는 파티션으로 R/W 요청을 전달할 수 있다.
-
보조 인덱스가 연관되면 상황은 복잡해진다.
보조 인덱스는 보통 레코드를 유일하게 식별하는 용도가 아니라
특정한 값이 발생한 항목을 검색하는 수단이다.
-
사용자 123이 실행한 액션을 모두 찾거나
hogwash라는 단어를 포함하는 글을 모두 찾거나
빨간색 자동차를 모두 찾는 등의 작업에 사용한다.
-
보조 인덱스는 관계형 DB의 핵심 요소이며 문서 DB에서도 흔하다.
-
많은 키-값 저장소(ex. HBase, 볼드모토)에서는
구현 복잡도가 추가되는 것을 피하려고
보조 인덱스를 지원하지 않지만
보조 인덱스는 데이터 모델링에 매우 유용하므로
일부 저장소(ex. 리악)에서는 이를 추가하기 시작했다.
-
그리고 솔라나 엘라스틱서치 같은 검색 서버에게는 보조 인덱스는 중요한 기능이다.
-
보조 인덱스는 파티션에 깔끔하게 대응되지 않는 문제점이 있지만
그럼에도 보조 인덱스가 있는 DB를 파티셔닝하는 데 널리 쓰이는 2가지 방법이 있다.
1. 문서 기반 파티셔닝
2. 용어 기반 파티셔닝
문서 기준 보조 인덱스 파티셔닝
-
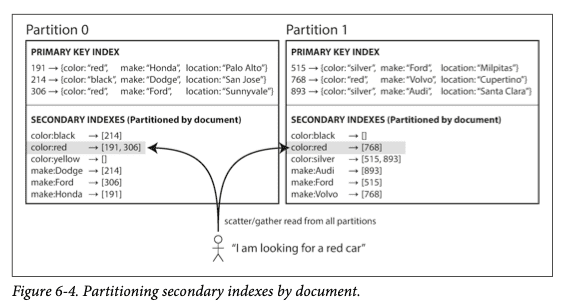
예를 들어 중고차를 판매하는 웹사이트를 운영한다고 하자.
각 항목에는 문서 ID라고 부르는 고유 ID가 있고
DB를 문서 ID 기준으로 파티셔닝한다.
( 고유 ID가 [0 ~ 499]는 파티션 0에 ID가 [500 ~ 999]는 파티션 1에 할당 )
-
사용자들이 차를 검색 시 색상과 제조사로 필터링할 수 있게 하려면
color와 maker에 보조 인덱스를 만들어야 한다.
-
예를 들어 빨간색 자동차가 DB에 추가되면
DB 파티션은 자동으로 그것을 color:red 인덱스 항목에 해당하는 고유 ID를 추가한다.
지역 인덱스 (Local Index)
-
이런 인덱스 방법을 사용하면
각 파티션은 자신의 보조 인덱스를 유지하면서
완전히 독립적으로 동작하며
그 파티션에 속하는 문서만 담당한다.
즉 다른 파티션에 어떤 데이터가 저장되는지는 신경 쓰지 않는다.
-
그래서 DB에 문서 추가/삭제/갱신 등의 쓰기 작업을 실행할 때는
쓰려고 하는 문서 ID를 포함하는 파티션만 다루면 된다.
-
이러한 이유로 문서 파티셔닝 인덱스는 지역 인덱스(Local Index)라고 부른다.
주의할 점
-
문서 기준으로 파티셔닝된 인덱스를 사용해서 Read 시 주의할 점이 있다.
문서 ID에 뭔가 특별한 작업을 하지 않는다면
특정 색상 혹은 제조사가 만든 자동차가 같은 파티션에 저장되리라는 보장이 없다.
-
그림 6-4에서 빨간색 자동차는 파티션 0에도 있고 파티션 1에도 있다.
따라서 빨간색 자동차를 찾고 싶다면 모든 파티션으로 질의를 보내야 한다.
스캐터/개더 (Scatter/Gather)
-
파티셔닝된 DB에 이런 식으로 질의를 보내는 방법을 스캐터/개더(Scatter/Gather)라고 부른다.
-
여러 파티션에 질의를 병렬 실행하더라도 스캐터/개더는 지연 시간 증폭이 발생하기 쉽다.
그럼에도 보조 인덱스를 문서 기준으로 파티셔닝하는 경우가 많다.
ex) 몽고DB, 리악, 카산드라, 엘라스틱서치, 솔라클라우드, 볼트DB
용어 기준 보조 인덱스 파티셔닝
전역 인덱스 (Global Index)
-
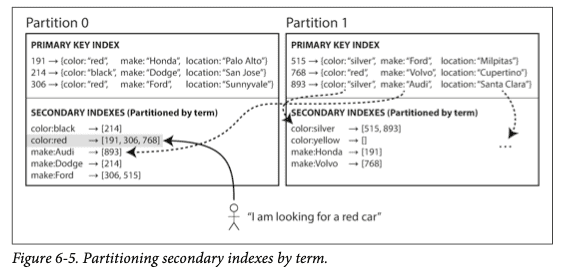
각 파티션이 자신만의 지역 인덱스를 갖게 하는 대신
모든 파티션의 데이터를 담당하는 전역 인덱스를 만들 수도 있다.
-
그러나 한 노드에만 인덱스를 저장할 수는 없다.
해당 노드가 병목이 되어 파티셔닝의 목적을 해치기 때문이다.
-
전역 인덱스도 파티셔닝해야 하지만 기본키 인덱스와는 다른 식으로 할 수 있다.
-
위 그림을 보면 모든 파티션에 있는
빨간색 자동차 정보는 color:red 항목에 저장되지만
a부터 r까지의 글자로 시작하는 color 인덱스는 파티션 0에
s부터 z까지의 글자로 시작하는 color 인덱스는파티션 1에 저장되도록 파티셔닝된다.
ex) black, red는 파티션 0 / silver, yellow는 파티션 1
-
이처럼 용어 자체를 인덱스로 잡게 되면
범위 스캔에 유용하지만 핫스팟이 발생할 수 있고
용어의 해시값을 사용해 파티셔닝하면 부하가 좀 더 고르게 분산된다.
위 내용 관련해선 키-값 데이터 파티셔닝 글을 참고하자.
장점
-
클라이언트는 모든 파티션에 스캐터/개더를 실행할 필요 없이
원하는 용어를 포함하는 파티션으로만 요청을 보내면 되므로
문서 파티셔닝에 비해 전역 인덱스가 갖는 이점은 읽기가 효율적이라는 것이다.
단점
-
전역 인덱스는 쓰기가 느리고 복잡하다는 단점이 있다.
단일 문서를 쓸 때 해당 인덱스는 여러 파티션에 영향을 줄 수 있기 때문이다.
( 문서에 있는 모든 용어가 다른 노드에 있는 다른 파티션에 속할 수도 있다. )
인덱스의 실시간 동기화
-
이상적인 상황이라면 인덱스는 항상 최신 상태에 있고
DB에 기록된 모든 문서는 바로 인덱스에 반영되어야 한다.
-
하지만 용어 파티셔닝 인덱스를 사용할 때
그렇게 하려면 쓰기에 영향받는 모든 파티션에 걸친 분산 트랜잭션을 실행해야 하는데
모든 DB에서 분산 트랜잭션을 지원하지 않는다.
-
현실에서는 전역 보조 인덱스는 대체로 비동기로 갱신된다.
즉 쓰기 실행 후 바로 인덱스를 읽으면 변경 사항이 반영되지 않을 수도 있다.
-
예를 들어 아마존 다이나모DB는 정상적인 상황에서는
전역 보조 인덱스를 갱신하는데 1초도 안 걸리지만
결함이 생기면 반영 지연 시간이 더 길어질 수 있다.