이 글은 책 내용을 토대로 작성하였습니다.
목차
Goal
- 파티셔닝 글 시리즈에서는 다음과 같은 부분들을 살펴본다.
-
대용량 데이터셋을 파티셔닝하는 방법
-
인덱싱과 파티셔닝의 상호작용 방법
-
클러스터에 노드 추가/삭제 시 재균형화 과정
-
DB가 어떻게 요청을 올바른 파티션에 전달 및 질의를 하는지 그 실행 과정에 대학 학습
요청 라우팅
-
이전 글을 통해 데이터셋을 여러 장비에서 실행되는 여러 노드에 파티셔닝할 수 있다.
하지만 아직 해결되지 않은 문제가 있다.
-
클라이언트에서 요청을 보내려고 할 때
어느 노드로 접속해야 하는지 어떻게 알 수 있을까?
-
파티션이 재균형화되면 노드에 할당되는 파티션이 바뀐다.
누군가가 “foo” 키를 읽거나 쓰려면 어떤 IP 주소와 포트 번호로 접속해야 할까?
이 질문에 답할 수 있도록 파티션 할당 변경을 알고 있어야 한다.
서비스 찾기 (Service Discovery)
-
이 문제는 DB에 국한되지 않는
서비스 찾기(Service Discovery)라고 부르는 일반적인 문제의 일종이다.
-
구체적 예로는 H/A 구조 혹은 네트워크를 통해 접속되는 S/W라면 이 문제에 해당한다.
해결 방법
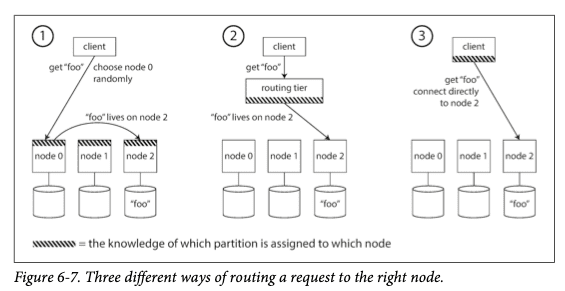
-
3가지의 서비스 찾기 문제를 해결할 방법이 있다.
각 방법에 대해 구체적으로 하나씩 알아보자.
해결 방법 - 1번째
-
클라이언트가 아무 노드에나 접속하게 한다.
그리고 해당 노드에 요청을 적용할 파티션이 있다면 직접 처리를 한다.
만약 찾고자 하는 파티션이 아니었다면
올바른 노드로 전달해서 응답을 받고 클라이언트에게 응답을 전달한다.
해결 방법 - 2번째
-
클라이언트의 모든 요청을 라우팅 계층으로 먼저 보낸다.
라우팅 계층에서는 각 요청을 처리할 노드를 알아내고
그에 따라 해당 노드로 요청을 전달한다.
-
라우팅 계층은 파티션을 정하는 로드밸런서로 동작만 할 뿐
그 자체에서는 아무 요청도 처리하지 않는다.
해결 방법 - 3번째
-
클라이언트가 파티셔닝 방법과
파티션이 어떤 노드에 할당됐는지를 알고
중개자 없이 올바른 노드로 직접 접속한다.
한계
-
이 문제는 참여하는 모든 곳에서 정보가 일치해야 하므로 다루기 어렵다.
그렇지 않으면 요청이 잘못된 노드로 전송되고 제대로 처리되지 못한다.
-
또한 분산 시스템에서 합의를 이루는 데 쓰이는 프로토콜이 있지만 제대로 구현하기가 까다롭다.
코디네이션 서비스
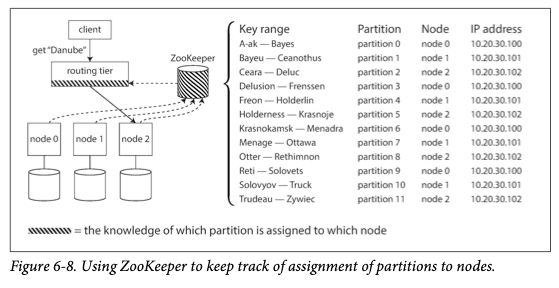
-
이러한 한계를 극복하기 위해
많은 분산 데이터 시스템은 클러스트 메타데이터를 추적하기 위해
주키퍼(ZooKeeper)와 같은 별도의 코디네이션 서비스를 사용한다.
-
각 노드는 주키퍼에 자신을 등록하고
주키퍼는 파티션과 노드 사이의 신뢰성 있는 정보를 관리한다.
-
그래서 파티션 소유자가 바뀌거나
클러스터에 노드가 추가 혹은 삭제가 되면
주키퍼는 라우팅 계층에 이를 알려서
라우팅 정보를 최신으로 유지할 수 있게 한다.
-
그리고 이 라우팅 계층을 바라보는 다른 구성요소들은 주키퍼에 있는 정보를 구독한다.
실제 프로젝트 예
-
링크드인의 에스프레소는 주키퍼에 의존하는 헬릭스(Helix)를 사용하여 클러스터를 관리한다.
또한 HBase, 솔라클라우드, 카프카도 파티션 할당을 추적하는 데 주키퍼를 사용한다.
-
몽고DB도 아키텍처는 비슷하지만
자체적인 설정 서버(Config Server) 구현에 의존하고
몽고스(Mongos) 데몬을 라우팅 계층으로 사용한다.
-
카산드라와 리악은 다른 방법을 쓴다.
가십 프로토콜(Gossip Protocol)을 사용해서 클러스 상태 변화를 노드 사이에 퍼뜨린다.
아무 노드나 요청을 받을 수 있고
요청을 받은 노드는 요청을 처리할 파티션을 갖고 있는 올바른 노드로 요청을 전달해준다.
( = 그림 6-7의 1번 방법 )